几个基础函数
(1)搜索文本:text.concordance(word)
例如,在text1中搜索词”is”在文本中出现的次数以及上下文的词:text1.concordance("is")

(2)搜索上下文相似的词:text.similar(word)
例如,在text1中搜索哪些相似的词出现在词”is”的上下文中:text1.similar("is")
(3)搜索几个词汇上下文的公共词汇:text.common_contexts([word1,word2…])
例如,在text1中搜索哪些词是”is”和“that”上下文中的公共词汇:text1.common_contexts(["is","that"])

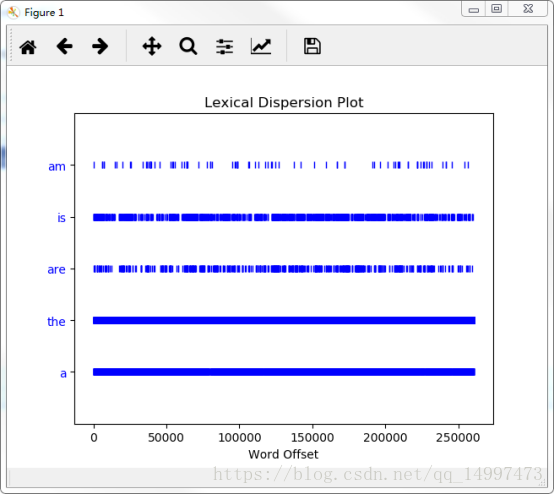
(4)离散图表示词出现的位置序列:text.dispersion_plot([word1, word2,])
例如,用离散图表示词"am","is","are","the","a"在text1中出现的位置,即从开头算起的第多少个词:text1.dispersion_plot(["am","is","are","the","a"])
(5)统计文本标示符(单词和标点符号)的个数:len(text)
(6)获取文本的词汇表(含标点符号):set(text)
(7)获取词汇表并排序:sorted(set(text))
(8)统计词汇表的大小:len(set(text))