Spark SQL可以支持Parquet、JSON、Hive等数据源,并且可以通过JDBC连接外部数据源
一、通过JDBC连接数据库

1.准备工作
在Linux中启动MySQL数据库:

输入下面SQL语句完成数据库和表的创建:
2.读取mysql数据库中的数据
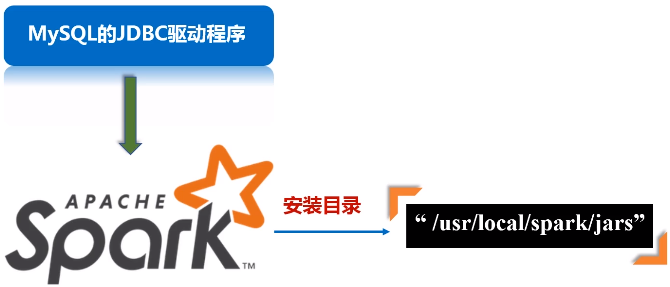
- 下载MySQL的JDBC驱动程序,比如mysql-connector-java-5.1.40.tar.gz
- 把该驱动程序拷贝到spark的安装目录” /usr/local/spark/jars”下
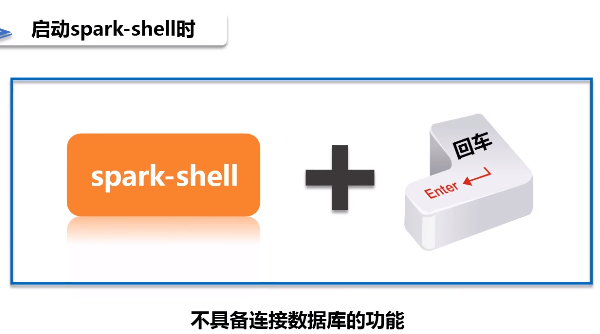
- 启动一个spark-shell,启动Spark Shell时,必须指定mysql连接驱动jar包

执行以下命令连接数据库,读取数据,并显示:

load()读取数据,封装到DataFrame内存中。

3.向mysql数据库写入数据
在MySQL数据库中创建了一个名称为spark的数据库,并创建了一个名称为student的表创建后,查看一下数据库内容:

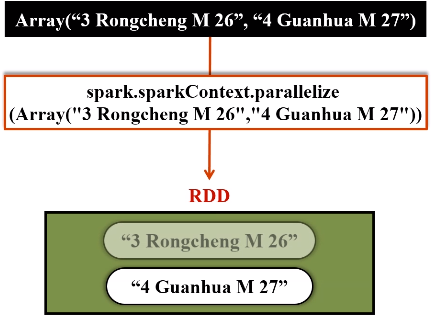
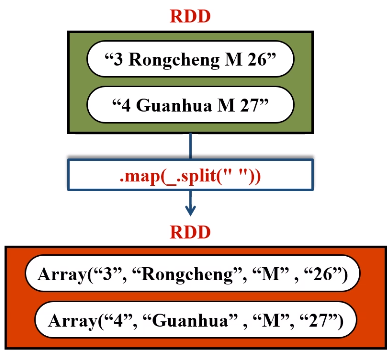
现在开始在spark-shell中编写程序,往spark.student表中插入两条记录



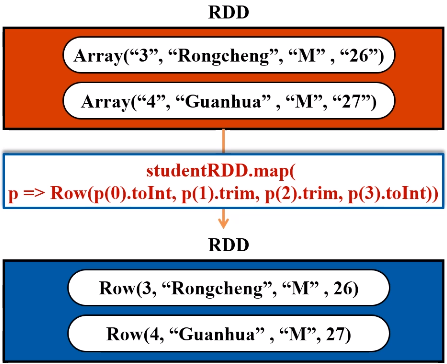



二、连接Hive读写数据
1.准备工作
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策。
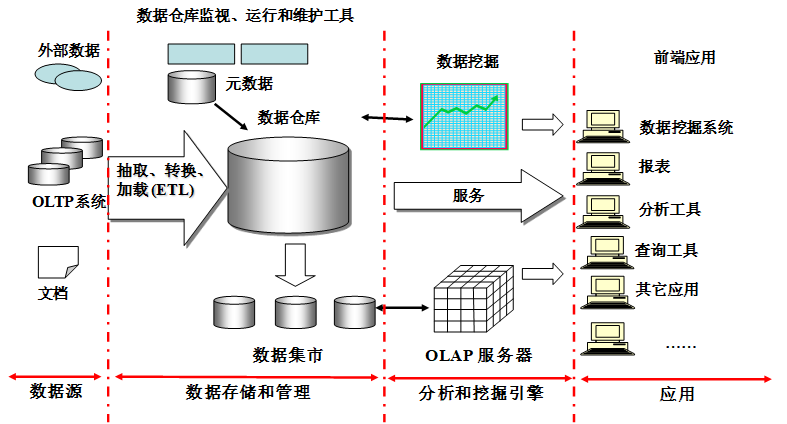
图 数据仓库的体系结构