使用FormRequest.from_response()方法模拟用户登录
1、说明
通过网站会实现对某些表单字段(如数据或是登录界面中的认证令牌等)的预填充。
使用Scrapy抓取网页时,如果想要预填充或重写像用户名、用户密码这些表单字段,可以使用`FormRequest.from_response()`方法实现
类原型:from_response(
response, #一个包含HTML表单的响应页面
formname(string)=None, # 如果不为None,表单中的name属性将会被设定为这个值
formnumber(int)=0, # 当响应页面中包含多个HTML表单时,本参数用来指定使用第几个表单,第一个表单数字为0
formdata(dict)=None, #本参数用来填充表单中属性的值,如果其中一个属性的值在响应页中已被预填充,formadta中的值会将预填充的值覆盖掉
formxpath(string)=None, # 如果页面中有多个HTML表单,可以用xpath表达式定位页面中的表单,第一个被匹配的将会被操作
callback(callable), 请求成功后,调用的方法
)
2、参考代码
import scrapy class LoginSpider(scrapy.Spider): name = "example.com" start_urls = ['http://www.example.com/users/login.html'] def parse(self,response): return scrapy.FormRequest.from_response( response, formdata={"username":"dada","password":"secret"}, callback=self.after_login, ) def after_login(self,response): # 在执行下一步之前检查是否登录成功 if "authentication failed" in response.body: self.log("Login failed",level=log.ERROR) return

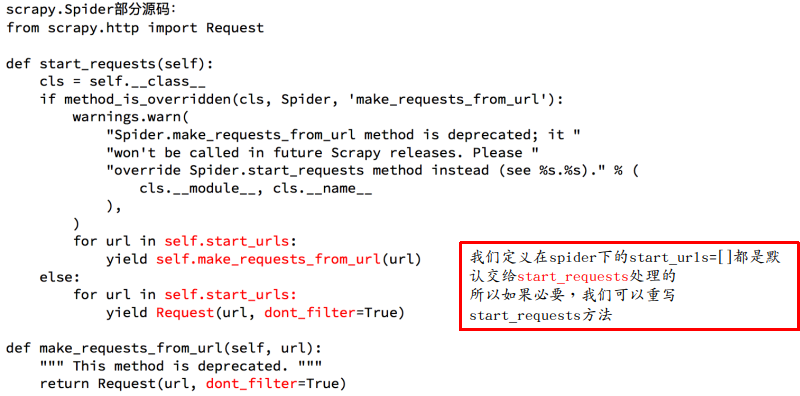
3、通过重写start_requests,