1、新建项目
(1)创建一个新的Scarpy项目,进入自定义的项目目录中,运行命令:`scrapy startproject mySpider`
说明:(1)mySpider为项目名称
(2)运行这条命令后,会生成一个mySpider的文件夹,里面存放创建的spider项目
(2)mySpider的目录结构
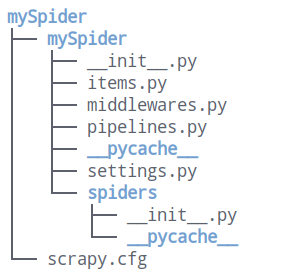
(3)各个主要文件的作用
`scrapy.cfg`:项目的配置文件
`mySpider/`:项目的python模块,将会从这里引用代码
`mySpider/items.py`:项目的目标文件
`mySpider/pipelines.py`:项目的管道文件
`mySpider/settings.py`:项目的设置文件
`mySpider/spiders/`:存储爬虫代码的目录
2、明确目标(mySpider/items.py)
爬取网站里的所有讲师的姓名、职称和个人信息:http://www.itcast.cn/channel/teacher.shtml
(1)打开mySpider目录下的items.py
(2)item定义结构化数据字典,用来保存爬取到的数据,类似于python中的字典,但是提供了一些额外的保护减少错误
(3)可以通过创建一个继承自scrapy.Item的类,并且定义类型为scrapy.Field的类属性来定义一个Item
(4)创建一个ItcastItem类,和构建item模型(model)
class ItcastItem(scrapy.Item): name = scrapy.Field() level = scrapy.Field() info = scrapy.Field()
3、制作爬虫
爬虫功能要分为两步:(1)爬数据(2)取数据
3.1 爬数据
(1)在当前目录下输入 命令,在mySpider/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
`scrapy genspider itcast 'itcast.cn'`
(2)打开mySpider/spider目录里的itcast.py

说明:上面的代码为默认生成,可以自行创建。
注意:要建立一个Spider,必须用scrapy.Spider类创建一个子类,并确定三个强制的属性和一个方法
(1)三个属性
`name=""`:是这个爬虫的识别名称,必须是唯一的,在不用的爬虫必须定义不同的名字
`allow_domains=[]`:是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。
`start_urls=()`:爬去的URL元祖/列表。爬虫从这里开始抓取数据,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
(2)一个方法
`parse(self,response)`:解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用:1)负责解析返回的网页数据(response.body),提取结构化数据(生成item)2)生成下一页需要的URL请求。
(3)将start_urls的值修改为需要爬去的第一个URL
`start_urls=("http://www.itcast.cn/channel/teacher.shtml")`
(4)修改parse()方法
parse()方法继承自scrapy.Spider,如果不重写这个方法,就会报错NotImplementedErrror。
def parse(self, response): with open('teacher.html','w') as f: f.write(response.text)
(5)在mySpider目录下运行:
`scrapy crawl itcast`
说明:itcast是ItcastSpider类的name属性,即使用`scrapy genspider`命令产生的爬虫名,一个Scrapy爬虫项目里,可以存在多个爬虫,各个爬虫在执行时,就是按照name属性来区分的。
(5)运行之后,如果打印的日志出现`[scrapy] INFO:Spider closed(finished)`,代表执行完成。
(6)在当前文件夹中出现的teacher.html文件,里面就是我们刚才要爬取的网页的全部源代码信息。
3.2 取数据
(1)引入mySpider/items.py里定义的一个ItcastItem类
`from mySpider.items import ItcastItem`
(2)从选择器中提取字符串
1)extract()返回一个包含有字符串数据的列表
2)extract_first()返回列表中的第一个字符串
(3)注意
1)spider中的parse方法名不能修改
2)需要爬取的url地址必须要属于allow_domain下的链接
3)response.xpath()返回的是一个含有selector对象的列表
(4)为什么要使用yield?
让整个函数变成一个生成器,变成generator(生成器)有什么好处?
每次遍历的时候挨个读到内存中,不会导致内存的占用量瞬间变高。
(5)将得到的数据封装到一个ItcastItem对象中
class ItcastSpider(scrapy.Spider): # 自定义Spider类,继承自scrapy.Spider name = 'itcast' # 爬虫名字 <爬虫启动时候使用:scrapy crawl itcast> allowed_domains = ['itcast.cn'] # 允许爬取的范围,防止爬虫爬到了别的网站 start_urls = ['http://www.itcast.cn/channel/teacher.shtml'] # 开始爬取的地址 def parse(self, response): # 数据提取方法,接收下载中间件传过来的response # 存取内容 with open('teacher_.html','w') as f: f.write(response.text) # 读取内容 for each in response.xpath("//div[@class='tea_con']/div//li"): # 将得到的数据封装到一个"ItcastItem" item = ItcastItem() # extract()方法返回的都是字符串 # xpath返回的是包含一个元素的列表 name = each.xpath(".//h3/text()") name = name[0] if name else None title = each.xpath(".//h4/text()") title = title[0] if title else None info = each.xpath(".//p/text()") info = info[0] if info else None item["name"] = name item["title"] = title item["info"] = info # 将获取的数据交给pipelines
# yield的作用是将函数parse变成一个生成器,在通过pipelines取数时,不断的遍历parse函数。因为不是返回的所有数据,只是一个一个地取,所以能减少内存占用。
yield item
(3)编辑settings.py文件
# 打开settings.py文件,编辑如下设置 # Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36' # Obey robots.txt rules ROBOTSTXT_OBEY = False ITEM_PIPELINES = { 'mySpider.pipelines.MyspiderPipeline': 300, }
(4)保存数据
scrapy保存信息的最简单的方法主要有四种,`-o`输出指定格式的文件,命令如下:
# json格式,默认为Unicode编码 scrapy crawl itcast -o teachers.json # json lines格式,默认为Unicode编码 scrapy crawl itcast -o teachers.jsonl # csv 逗号表达式,可用Excel打开 scrapy crawl itcast -o teachers.csv # xml格式 scrapy crawl itcast -o teachers.xml