参考url:
https://jakevdp.github.io/PythonDataScienceHandbook/05.11-k-means.html
聚类算法直接从数据的内在性质中学习最优的划分结果或者确定离散标签类型。
1、k-means简介
k-means算法在不带标签的多维数据集中寻找确定数量的簇。
最优的聚类结果需要符合以下两个假设:
(1)'簇中心点'(cluster center)是属于该簇的所有数据点坐标的算术平均值
(2)一个簇的每个点到该簇中心点的距离,比到其他簇中心点的距离短
这两个假设是k-means模型的基础。

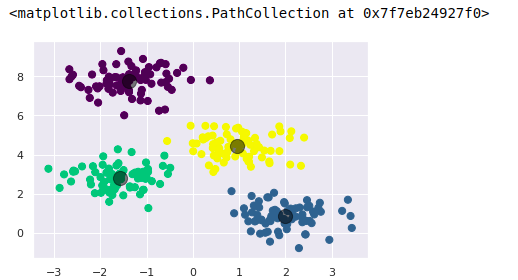
2、k-means算法:期望最大化
期望最大化(ecpectation-maximization,E-M)是一种非常强大的算法,应用于数据科学的很多场景中,k-means是该算法的一个非常简单并且易于理解的应用。
期望最大化方法包含以下步骤:
(1)猜测一些簇中心点
(2)重复直至收敛
a、期望步骤(E-step):将点分配至离其最近的簇中心点。
b、最大化步骤(M-step):将簇中心点设置为所有点坐标的平均值
期望步骤(E-step或Expectation step)不断更新每个点是属于哪一个簇的期望值,最大化步骤(M-step或Maximization step)计算关于簇中心点的拟合函数值最大化对应坐标(argmax函数)
在本例中,通过简单地求每个簇中所有数据点坐标的平均值得到了簇中心点坐标。
在典型环境下,每一次重复E-step和M-step都将会得到更好的聚类效果。
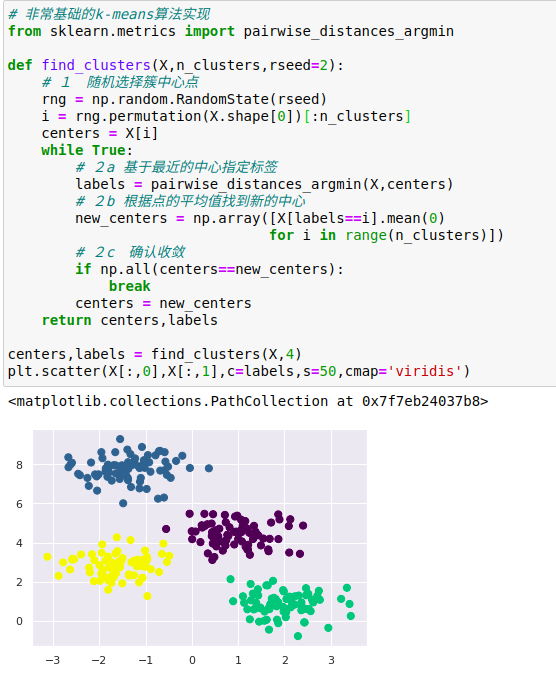
虽然大部分可用的聚类算法底层其实都是对上诉示例的进一步扩展,但上述函数解释了期望最大化方法的核心内容。
并不一定得到最优解
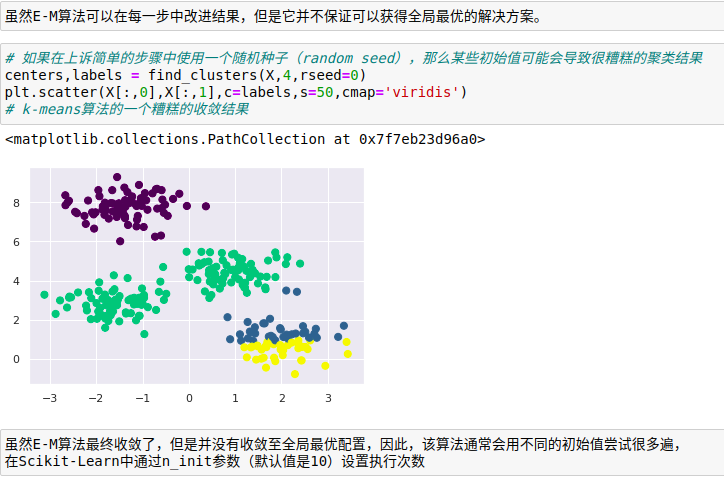
簇数量必须事先定好
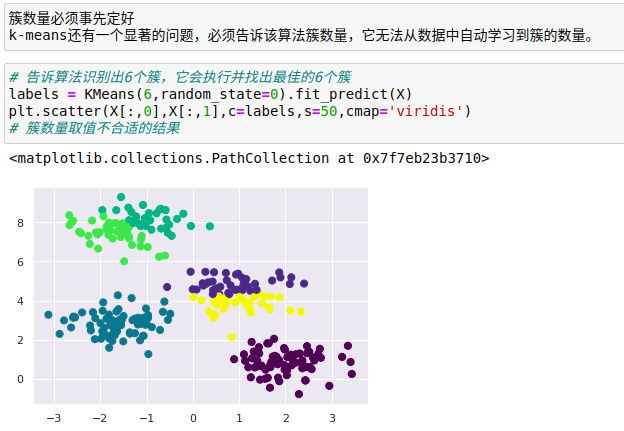
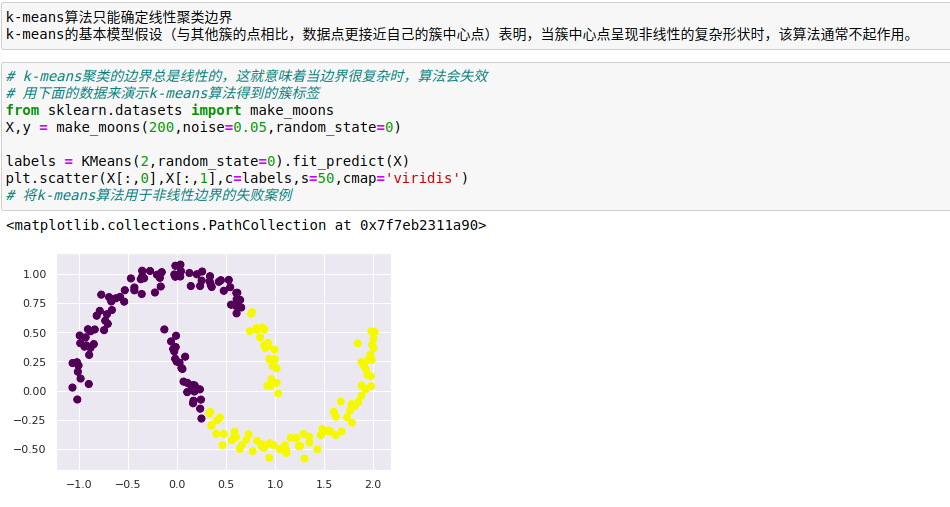
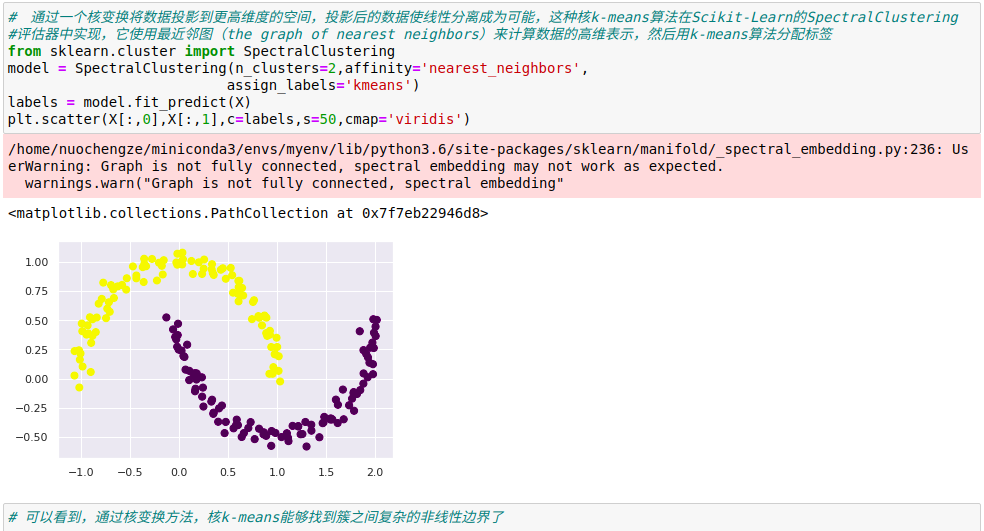
k-means算法只能确定线性聚类边界
当数据量较大时,k-means会很慢
由于k-means的每次迭代都必须获取数据集所有的点,因此随着数据量的增加,算法会变得很缓慢。
使用批处理(batch-based)k-means算法来解决,该算法将条件从'每次迭代都必须使用所有数据点'放宽至'每一步仅使用数据集的一个子集来更新簇中心点',算法在sklearn.cluster.MiniBatchKMeans中实现,其接口和标准的KMeans接口相同。
3、案例
1、用k-means算法处理手写数字
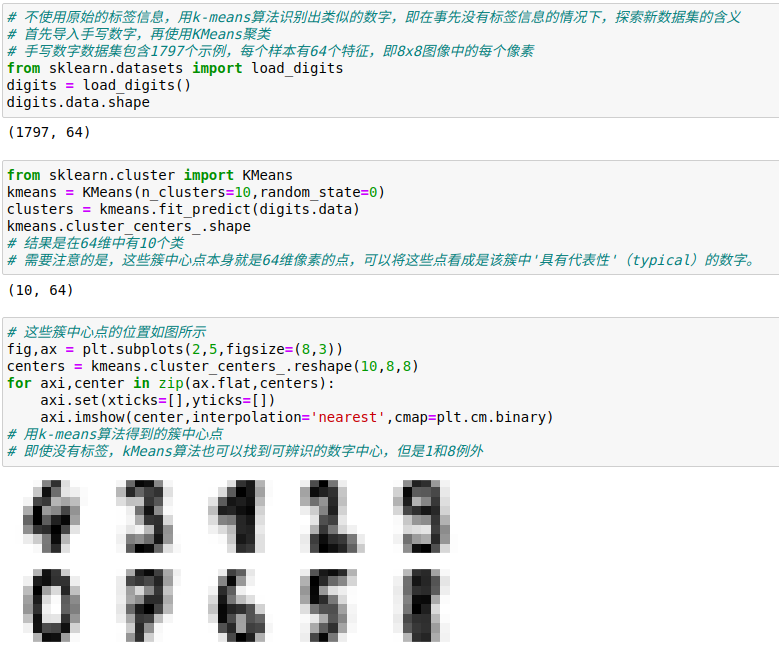
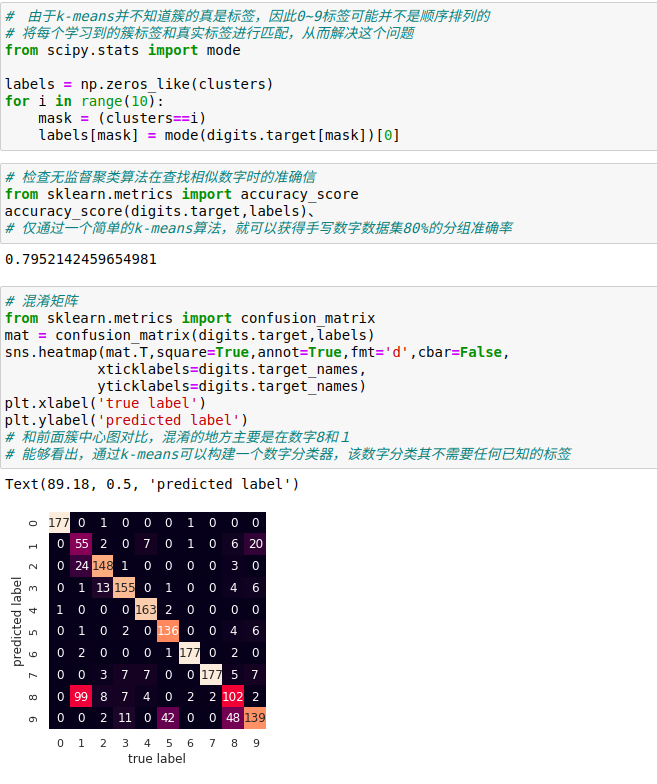

同样在没有标签的情况下,它可以达到94%的分类准确率,无监督学习可以从数据集中抽取难以用手眼直接提取的信息。