 

推荐教程
- 官方文档
- multiprocess各个模块较详细介绍
- 廖雪峰教程--推荐
- Pool中apply, apply_async的区别联系
- (推荐)python多进程的理解 multiprocessing Process join run
multiprocessing.Manager.Queuue vs multiprocessing.Queuue
| 队列 | 说明 |
|---|---|
| multiprocessing.Queuue | 只应通过继承在进程之间共享 Queue 对象 |
| multiprocessing.Manager.Queue | 如上所述,在进行并发编程时,通常最好尽量避免使用共享状态。使用多个进程时尤其如此。但是,如果您确实需要使用某些共享数据,那么多处理提供了两种方法。其中一种就是使用 Manager |
范例一
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2019-03-09 17:24
# @Author : wangbin
# @FileName: demo06.py
# @mail : bupt_wangbin@163.com
from multiprocessing import Process, Queue, Pool, Manager
import os
import time
import random
def write(q):
# 写数据进程执行的代码:
print('Process to write: %s' % os.getpid())
for value in range(8):
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
def read(q):
# 读数据进程执行的代码:
print('Process to read: %s' % os.getpid())
while True:
if not q.empty():
value = q.get(True)
print('Get %s from queue.' % value)
time.sleep(random.random())
else:
break
if __name__ == '__main__':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
p = Pool()
pw = Process(target=write, args=(q,))
pw.start()
time.sleep(0.5)
pr = p.apply(read, args=(q,))
p.close()
p.join()
pw.join()
报错: Queue objects should only be shared between processes through inheritance(只应通过继承在进程之间共享 Queue 对象, 即为只可以父进程和子进程之间共享 Queue 对象)
 

范例二
一下方式可以使用
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2019-03-09 15:45
# @Author : wangbin
# @FileName: demo04.py
# @mail : bupt_wangbin@163.com
"""
进程间通信
Process之间肯定是需要通信的,操作系统提供了很多机制来实现进程间的通信。
Python的multiprocessing模块包装了底层的机制,提供了Queue、Pipes等多种方式来交换数据。
我们以Queue为例,在父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据:
"""
from multiprocessing import Process, Queue, Pool, Manager
import os
import time
import random
def write(q):
# 写数据进程执行的代码:
print('Process to write: %s' % os.getpid())
for value in range(10):
# print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
def read(q):
# 读数据进程执行的代码:
print('Process to read: %s' % os.getpid())
while True:
value = q.get(True)
print('Get %s from queue.' % value)
if __name__ == '__main__':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr1 = Process(target=read, args=(q,))
pr2 = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 启动子进程pr,读取:
pr1.start()
pr2.start()
# 等待pw结束:
pw.join()
# pr进程里是死循环,无法等待其结束,只能强行终止:
pr1.terminate()
pr2.terminate()
上述程序由于都是死循环, pr1 和 pr2如果有一个调用 join 方法的话, 程序就会一直在 block 住. 如果使用 Pool 会比较好管理, 而之前第一个范例说明, Pool 与 Produce 之间使用 multiprocessing.Queue 会出现错误, 所以, 如果使用 Pool 来产生多个进程用于生产者或者消费者, 用 Pool 很简单. 所以, 当要共享数据时候, 使用Manager.Queue() 准没错
总结: 如果使用进程共享数据的话, 就使用 Manager.Queue()
范例三
下面是使用进程池来做的
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : 2019-03-09 15:45
# @Author : wangbin
# @FileName: demo04.py
# @mail : bupt_wangbin@163.com
from multiprocessing import Process, Queue, Pool, Manager
import os
import time
import random
def write(q):
# 写数据进程执行的代码:
print('Process to write: %s' % os.getpid())
for value in range(3):
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
def read(q):
# 读数据进程执行的代码:
print('Process to read: %s' % os.getpid())
while True:
value = q.get(True)
print('Get %s from queue.' % value)
if __name__ == '__main__':
# 父进程创建Queue,并传给各个子进程:
with Manager() as manager:
with Pool(processes=8) as pool:
# 启动子进程pr,读取:
q = manager.Queue()
for i in range(3):
pool.apply_async(func=write, args=(q,))
pool.apply_async(func=read, args=(q,)).get()
pool.close()
pool.join()
pool.terminate()
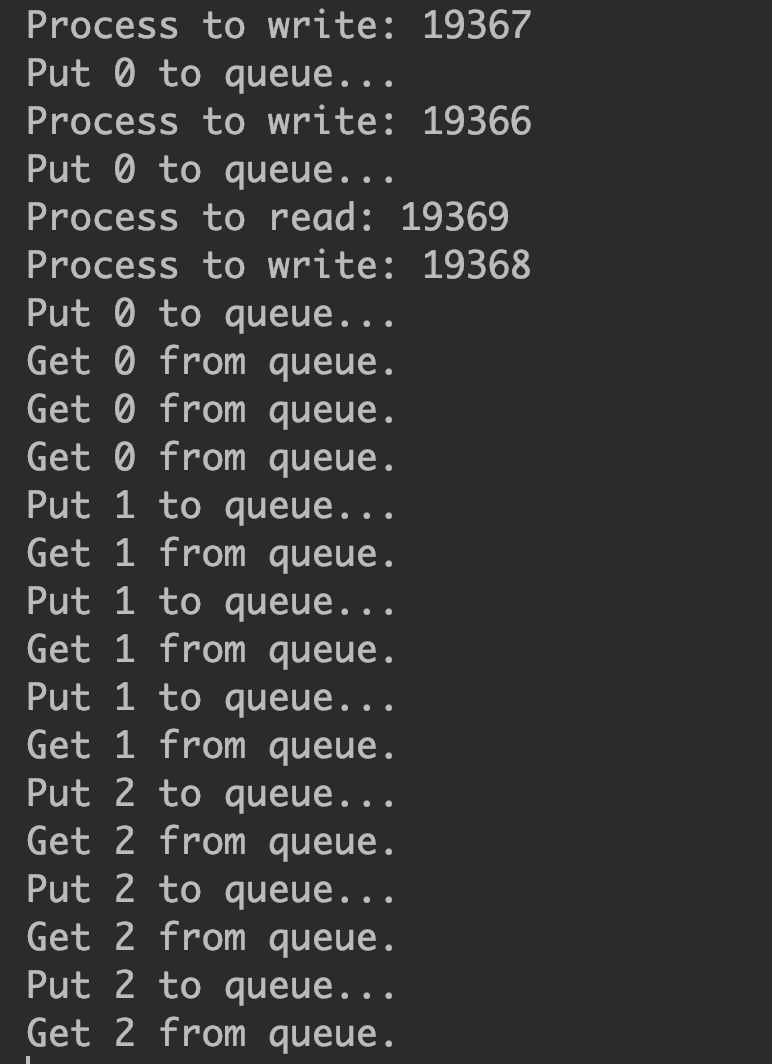 

由此可以看出, 每个进程中, 每个程序都会跑一边. 所以炼丹测试时, 验证集数据集只能使用一个进程跑, 而读取的进程需要多设置几个
Pool
如果要启动大量的子进程,可以用进程池的方式批量创建子进程:
from multiprocessing import Pool
import os, time, random
def long_time_task(name):
print('Run task %s (%s)...' % (name, os.getpid()))
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print('Task %s runs %0.2f seconds.' % (name, (end - start)))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Pool(4)
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print('Waiting for all subprocesses done...')
p.close()
p.join()
print('All subprocesses done.')
执行结果如下:
Parent process 669.
Waiting for all subprocesses done...
Run task 0 (671)...
Run task 1 (672)...
Run task 2 (673)...
Run task 3 (674)...
Task 2 runs 0.14 seconds.
Run task 4 (673)...
Task 1 runs 0.27 seconds.
Task 3 runs 0.86 seconds.
Task 0 runs 1.41 seconds.
Task 4 runs 1.91 seconds.
All subprocesses done.
代码解读:
-
对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process了。
-
请注意输出的结果,task 0,1,2,3是立刻执行的,而task 4要等待前面某个task完成后才执行,这是因为Pool的默认大小在我的电脑上是4,因此,最多同时执行4个进程。这是Pool有意设计的限制,并不是操作系统的限制。如果改成:p = Pool(5), 就可以同时跑5个进程。
-
由于Pool的默认大小是CPU的核数,如果你不幸拥有8核CPU,你要提交至少9个子进程才能看到上面的等待效果。