函数是程序的基本组成单位,利用函数,不仅能够实现程序的模块化,而且简单、直观,能极大的提高程序的易读性及可维护性,所以将程序中的一些计算或操作抽象成函数以供谁是调用,理解函数的执行原理以及应用是一个优秀程序员应该具备的基本能力。
1、怎么样写一个接受可变参数的函数
C语言支持函数调用的参数为变参形式。例如,printf()这个函数,它的函数原型是int printf(const char* format,...),它除了有一个参数format固定以外,后面跟的参数的个数和类型都是可变的,可以有以下多种不同的调用方法:
1、printf("%d",i );
2、printf("%s",s);
3、printf("the number is %d,string is %s",i,s);
printf函数是一个有着变参的库函数,在C语言中,也可以更具实际的需求编写变参函数,示例如下:
#include "stdafx.h"
#include<stdio.h>
int add2(char num, ...)
{
int sum = 0;
int index = 0;
int *p = NULL;
p = (int *)&num + 1;
for (; index < (int)num; ++index)
{
sum += *p++;
}
return sum;
}
int main()
{
int i = 1;
int j = 2;
int k = 3;
printf("%d
", add2(3, i, j, k));
return 0;
}
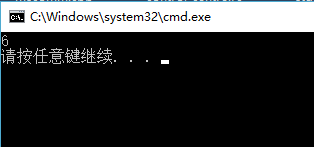
运行结果如下:
2、函数指针和指针函数有什么区别
指针函数是指带指针的函数,本质上是一个函数,函数返回类型是某一类型的指针。其形式一般如下:
类型标识符 *函数名(参数列表)
例如,int *f(x,y),它的意思是声明一个函数f(x,y),该函数返回类型为int型指针。
而函数指针是指想函数的指针变量,即本质是一个指针变量,表示的是一个指针,它指向的是一个函数。其形式一般如下:
类型说明符 (*函数名)(参数)
例如,int (*pf)(int x),它的意思就是声明一个函数指针,而pf=func则是将func函数的首地址赋值给指针。下面是一个相关示例:
#include "stdafx.h"
#include<stdio.h>
#define NULL 0
#define ASGN 1
#define MUL 2
int asgn(int*a, int b)
{
return *a = b;
}
int mul(int*a, int b)
{
return *a*b;
}
int(*func(int op))(int*, int)
{
switch (op)
{
case ASGN:
return &asgn;
case MUL:
return &mul;
default:
return NULL;
}
return NULL;
}
int main()
{
int i = 0xFEED, j = 0xBEEF;
printf("%x
", func(ASGN)(&i, j));
printf("%x
", func(MUL)(&i, j));
printf("%x,%x
", i, j);
return 0;
}
程序运行结果如下:

引申:数组指针/指针数组、函数模板/模板函数、类模板/模板类、指针常量/常量指针分别有什么区别?
(1)数组指针/指针数组
数组指针就是指向数组的指针,他表示的是一个指针,它指向的是一个数组,他的重点是指针。例如,int (*pa)[8]声明了一个指针,该指针指向了一个有8个int型元素的数组。
#include "stdafx.h"
#include<stdio.h>
int main()
{
int(*p)[4];
int a[3][4] = { {1,2,3,4},{5,6,7,8},{9,10,11,12} };
p = &a[0];
for (int i = 0; i < 12; i++)
printf("%d", (*p)[i]);
printf("
");
return 0;
}
运行结果如下: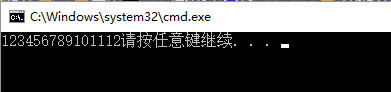
指针数组就是指针的数组,表示的是一个数组,它包含的元素是指针,它的重点是数组。
例如,int* ap[8]声明了一个数组,该数组的每一个元素都是int型的指针。
#include "stdafx.h"
#include<stdio.h>
int main()
{
int* p[4];
int a[4] = { 1,2,3,4 };
p[0] = &a[0];
p[1] = &a[1];
p[2] = &a[2];
p[3] = &a[3];
for (int i = 0; i < 4; i++)
printf("%d", *p[i]);
printf("
");
return 0;
}
程序运行结果如下:
(2)函数模板/模板函数
函数模板是对一批模样相同的函数的说明描述,它不是某一个具体的函数;而模板函数则是将函数模板内的“数据类型参数”具体化后得到的重载函数(就是由模板而来的函数)。简单的说,函数模板是抽象的,而模板函数是具体的。
函数模板减少了程序员输入代码的工作量,是C++中功能最强的特性之一,是提高软件代码重用性的重要手段之一。函数模板的形式一般如下:
template<模板函数形参表>
<返回值类型><函数名>(模板模板形参表)
{
//函数体
}
其中<模板含形参表>的,包括基本数据类型和类类型。需要注意到的是,函数模板并不是一个实实在在的函数,它是一组函数的描述,并不能直接执行,需要示例化为模板函数后才能执行,而一旦数据类型形参实例化以后,就会产生一个实实在在的模板函数了。
(3)模板类/类模板
类模板和函数模板类似,将数据类型定义为参数,描述了代码类似的部分类的集合,具体化为模板类后,可以用于生成具体的对象。
template<类型参数表>
class<类名>
{
//类说明体
};
template <类型形参表>
<返回类型><类名><类型名表>::<成员函数1>(形参表)
{
//成员函数定义体
}
其中<类型形参表>与函数模板<类型形参表>意义雷氏,而类模板本身不是一个真实的类,只是对类的一种描述,必须用类型参数将其实例化为模板类后,才能用来生成具体的对象。简而言之,类是对象的抽象,而类模板就是类的抽象。
具体而言,C++中引入模板类主要由以下5个方面的好处:
- 可用来创建动态增长和减小的数据结构。
- 它是类型无关的,因此具有很高的可复用性。
- 它在编译时而不是运行时检查数据类型,保证了类型安全。
- 它是与平台无关的,可移植性强。
- 可用于基本数据类型。
(4)指针常量/常量指针
指针常量是指定义的指针只能在定义的时候初始化,之后不能改变其值。其格式为:
[数据类型][*][const][指针常量名称] 例如: char * const p1; int* const p2;
const位于指针声明符“*”的右侧,这说明声明的对象是一个常量,而对象的数据类型是指针。所以第一句定义了一个只读的字符型指针p1;第二局定义了一个只读型的整形指针p2。常指针的值不能改变,但是其指向的内容却可以改变。
#include "stdafx.h"
#include<stdio.h>
int main()
{
char a[5] = "abcd";
char b[5] = "efgh";
char * const p1 = a;
char * const p2 = b;
printf("Before Change:
");
printf("a:%s
b:%s
", a, b);
*p1 = '1';
b[0] = '2';
//p1=p2;
printf("After Change:
");
printf("a:%s
b:%s
", a, b);
return 0;
}
运行结果如下: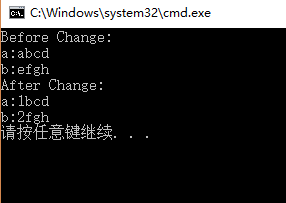
上例中,如果去掉注释行,执行p1=p2操作,则会编译出错。指针所指向的内存地址不能更改,指针的值只能在定义的时候初始化,其他地方不能更改。
常量指针是指向常量的的指针,因为常量指针指向的对象是常量,因此这个对象的值不能够改变的。定义的格式如下:
[数据类型][const][*]{常量指针对象];
或
[const][数据类型][*]{常量指针名称];
例如:
int const *p;const int *p;
程序示例如下:
#include "stdafx.h"
#include<stdio.h>
int main()
{
char a[5] = "abcd";
char b[5] = "efgh";
const char * p1 = a;
const char * p2 = b;
printf("Before Change:
");
printf("a:%s
b:%s
", a, b);
a[0] = '1';
p1=p2;
//*p2='2';
printf("After Change:
");
printf("a:%s
b:%s
", a, b);
return 0;
}
运行结果如下:

上例中,注释部分错误,不能给常量赋值。
需要注意的是,指针常量强调的是指针的不可改变性,而常量指针强调的是针对其所指对象的不可改变性,它所指向的对象的值是不能通过常量来改变的。对于字符串“abc”,可以这样获取地址:&(”abc“)。
3、C++函数传递参数的方式有哪些
当金星函数调用时,要填入与函数形式参数个数相同的实际参数,在程序运行过程中,实际参数就会将参数传递给相应的形式参数,然后在函数中实现对数据的处理和返回。C++函数传递参数的方式一般由以下4种:
(1)值传递:值传递就是将实参的值复制到形参中。程序示例如下:
#include "stdafx.h"
#include<iostream>
using namespace std;
void swap(int a, int b)
{
int temp;
temp = a;
a = b;
b = temp;
cout << a << "," << b << ednl;
}
int main()
{
int x = 1;
int y = 2;
swap(x, y);
cout << x << "," << y << endl;
return 0;
}
程序运行结果如下
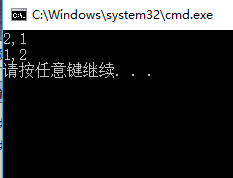
(2)指针传递:指针传递,进行指针传递时,形参是指针变量,实参是一个变量的地址,调用函数时,形参指向实参变量单元。示例如下:
#include "stdafx.h"
#include<iostream>
using namespace std;
void swap(int *a, int *b)
{
int temp;
temp = *a;
*a = *b;
*b = temp;
cout << *a << "," << *b << endl;
}
int main()
{
int x = 1;
int y = 2;
swap(&x, &y);
cout << x << "," << y << endl;
return 0;
}
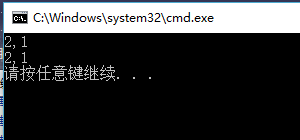
(3)传引用:实参地址传递到形参,使形参的地址去实参的地址,从而使形参与实参共享同一单元的方式。示例代码如下:
#include "stdafx.h" #include<iostream> using namespace std; void swap(int &a, int &b) { int temp; temp = a; a = b; b = temp; cout << a << "," << b << endl; } int main() { int x = 1; int y = 2; swap(x, y); cout << x << "," << y << endl; return 0; }
运行结果为:
(4)全局变量传递
4、重载与覆盖有什么区别
重载是指函数不同的参数表,对同名函数的名称做修饰,然后这些同名函数就成了不同的函数。在同一个可访问区域内被声明的几个具有不同参数列(参数的类型、个数、顺序不同)的同名函数,程序会根据不同的参数列来确定具体调用哪个函数。对于重载函数的调用,在编译期间就已经确定,是静态的,它们的地址在编译期间就绑定了与多态无关。重载不关心函数的返回值类型。
(1)double calculate(double); (2)double calculate(double,double); (3)double calculate(double,int); (4)double calculate(int,double); (5)double calculate(int); (6)float calculate(double); (7)float calculate(float);
7个同名函数calculate,1,2,3,4,5,6,中任意两个均构成重载,6,7也能构成重载,而1,7不能构成重载,因为1,7的参数相同。
成员函数被重载的特征如下:
- 相同的范围
- 函数名相同
- 参数不同
- virtual关键字可有可无。
覆盖是指派生类中存在重新定义基类的函数,其函数名、参数列、返回值类型必须同父类中的相对应被覆盖的函数严格一致,覆盖函数和比覆盖函数只有函数体不同,当派生类对象调用子类中该同名函数时会自动调用子类中的覆盖版本,而不是父类中的被覆盖函数版本,它和多态真正相关。当子类重新定义了父类的虚函数后,父类指针根据赋给它的不同的子类指针,动态的调用属于子类的该函数,这样的哈是你地址是在运行期绑定的。
覆盖的特征如下:
- 不同的范围。
- 函数名字相同
- 参数相同
- 基类函数必须由virutal关键字。
重载和覆盖的区别如下:
- 覆盖是子类和父类之间的关系,是垂直关系;重载是同一类中方法之间的关系,是水平关系。
- 覆盖只能由一个方法,或只能由一对方法产生关系;方法的重载是多个方法之间的关系。
- 覆盖要求参数列表相同;重载要求参数列表不同。
- 覆盖关系中,调用方法体是根据对象的类型(对象对应存储空间类型)来决定的,重载关系是根据调用时的实参表与形参表来选择方法体的。
程序示例如下:
#include "stdafx.h"
#include<iostream>
using namespace std;
class Base
{
public:
void f(int x)
{
cout << "Base::f(int)" << x << endl;
}
void f(float x)
{
cout << "Base::f(float)" << x << endl;
}
virtual void g(void)
{
cout << "Base::g(void)" << endl;
}
};
class Derived :public Base
{
public:
virtual void g(void)
{
cout << "Derived::g(void)" << endl;
}
};
int main()
{
Derived d;
Base *pb = &d;
pb->f(42);
pb->f(3.14f);
pb->g();
return 0;
}
程序运行结果如下: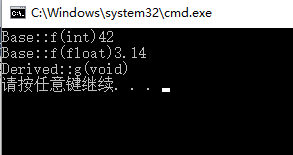
上例中,函数Base::f(int)与Base::f(float)相互重载,而Base::g(void)被Derived::g(void)覆盖。
隐藏是之派生类的函数与基类的函数同名,规则如下:
- 如果派生类的函数与基类的函数同名,但是参数不同,则无论有无virutal关键字,基类的函数都被隐藏。
- 如果派生类的函数与基类的函数同名,并且参数也相同,但是基类函数没有virtual关键字,此时基类的函数被隐藏。
在调用一个类的成员函数是,编译器会沿着类的集成连逐级的向上查找函数的定义,如果找到了就停止查找。所以,如果一个派生类和一个基类都存在同名(不管参数)的函数,而编译器最终选择了派生类中的函数,那么就说这个派生类的成员函数“隐藏”了基类的成员函数,也就是说它阻止了编译器继续向上查找函数的定义。
回到隐藏的定义,前面已经说了有virtual关键字,并且派生类函数与基类函数同名,同参数函数构成覆盖的关系,因此隐藏的关系只有如下的可能:
- 必须分别位于派生类和基类中
- 必须同名
- 参数不同的时候本身已经不构成覆盖关系了,所以此时是否有virtual已经不重要了。
当参数相同的时候就要看是否有virtual关键字了,有的话就是覆盖关系,没有的时候就是隐藏关系。示例如下:
#include "stdafx.h"
#include<iostream>
using namespace std;
class Base
{
public:
virtual void f(float x)
{
cout << "Base::f(float)" << x << endl;
}
void g(float x)
{
cout << "Base::g(float)" <<x<< endl;
}
void h(float x)
{
cout << "Base::h(float)" <<x<< endl;
}
};
class Derived :public Base
{
public:
virtual void f(float x)
{
cout << "Derived::f(float)" << x << endl;
}
void g(float x)
{
cout << "Derived::g(int)" << x << endl;
}
void h(float x)
{
cout << "Derived::h(float)" << x << endl;
}
};
int main()
{
Derived d;
Base *pb = &d;
Derived *pd = &d;
pb->f(3.14f);
pd->f(3.14f);
pb->g(3.14f);
pd->h(3.14f);
return 0;
}
运行结果如下:Derived::f(float)覆盖了Base::f(float),函数Derived::g(int)隐藏了Base::g(float)而不是重载,Derived::h(float)隐藏了Base::h(float)而不是覆盖。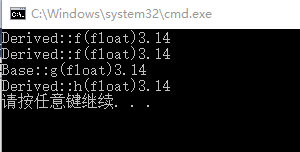
5、是否可以通过绝对内存地址进行参数的赋值与函数的调用
同一个数可以通过不同的方式表达出来,对于函数的访问,变量的赋值除了直接对变量赋值以外,还可以通过绝对内存地址进行参数赋值和函数调用。
- 通过地址修改变量的值
#include "stdafx.h"
#include<iostream>
int main()
{
int x;
int *p;
printf("%x ", &x);
p = &x;
*p = 3;
printf("%d ", x);
}程序输出结果为

- 通过地址调用函数的执行
#include "stdafx.h"
#include<iostream>
using namespace std;
typedef void(*FuncPtr)();
void p()
{
static int i = 0;
i++;//每调用一次+1
printf("%d
",i);
}
int main()
{
void(*ptr)();
p();//第一次调用ptr函数指针
printf("%x
", p);//输出函数的入口地址
ptr = (void(*)())&p;//将指针ptr指向函数的入口地址
ptr();//调用ptr
((void(*)())&p)();//不通过函数指针,直接通过地址调用
((FuncPtr)&p);//最后通过typedef调用直接执行。
return 0;
}
运行结果如下:
函数名称、代码都是放在代码段的,因为放在代码段,每次都会跳到相同的地方,但参数会压栈,所以函数只根据函数名来获取入口地址,与参数和返回值无关。无论参数和返回值如何不同,函数入口地址都是一个地方。
#include "stdafx.h"
#include<iostream>
#include<stdio.h>
int p(int a, int b)
{
return((a > b) ? a : b);
}
int main()
{
int(*ptr)(int, int);
printf("%x
", p);
ptr = (int(*)(int, int))&p;
int c = ptr(5, 6);//通过函数指针调用有返回值的参数,不使用函数名,而是用函数入口地址调用。
printf("%x
", ptr);
printf("%d
", c);
return 0;
}
程序运行结果如下:

6、默认构造函数是否可以调用单参数构造函数
默认构造函数不可以调用单参数的构造函数。
7、C++中函数调用有哪几种方式
编译器一般使用堆栈实现函数调用。堆栈是存储器的一个区域,嵌入式环境有时需要自己定义一个数组作为堆栈。Windows为每个线程自动维护一个堆栈,堆栈的大小可以设置。编译器使用堆栈来存放每个函数的参数、局部变量等等信息。
由于函数调用经常会被嵌套,在同一时刻,堆栈中会存储多个函数的信息,每个函数又占用一个连续的区域,一个函数占用的区域常被称为帧,编译器是从高地址开始使用堆栈的,在多线程(任务)环境,CPU的堆栈指针指向的存储器区域就是当前使用的堆栈。切换线程是一个重要的工作,就是将堆栈指针设置为当前线程的堆栈栈顶地址。不同CPU,不同编译期的堆栈布局、函数调用方法都可能不同,但堆栈的基本概念是一样的。
当一个函数被调用时,进程内核对象为其在进程的地址空间的堆栈部分分配一定的栈内存给该函数使用,函数堆栈功能如下:
- 在进入函数之前,保存“返回地址”和环境变量。返回地址是指该函数结束后,从进入该函数之前的那个地址继续执行下去。
- 在进入函数之后,保存实参或实参复制、局部变量。
函数原型:[连接规范]函数类型[调用约定]函数名 参数列表{...}
调用约定:调用约定是决定函数实参或实参复制进入和退出函数堆栈的方式以及函数堆栈释放的方式,简单来讲就是实参或实参复制入栈、出栈、函数堆栈释放的方式。在Win32下有以下4种调用:
- _cdecl:C/C++的默认调用方式。实参是以列表从右依次向左入栈 ,出栈相反。函数堆栈由调用方来释放,主要用在那些带有可变参数的函数上,对于传送参数的内存栈是由调用者来维护的,另外,在函数名修饰约定方面也有所不同。由于每一个调用它的函数都包含清空堆栈的代码,所以产生的可执行文件大小会比调用_stdcall函数的大。
- _stdcall:它是win api的调用约定,其实COM接口等只要是申明定义接口都要显示指定其调用约定为_stdcall。实参以参数列表从由依次向左入栈,出栈相反。函数堆栈是由被调用方自己释放的。但是若函数含有可变参数,那么即使显示指定了_stdcall,编译器也会自动将其改变成_cdecall.
- _thiscall:它是类的非静态成员函数默认的调用约定,其不能用在含有可变参数的函数上,否则会编译出错。实参以参数列表从右一次向左入栈,出栈相反。函数堆栈是由被调用方自己释放的。但是类的非静态成员函数内部都隐含由一个this指针,该指针不是存放在函数堆栈上,而是直接存放在CPU寄存器上。
- _fastcall:快速调用。它们的实参并不是存放在函数堆栈上,而是直接存放在CPU寄存器上,所以不存在入栈、出栈、函数堆栈释放。
需要注意到的是,全局函数或类静态成员函数,若没有指定调用,约定默认是_cdecl或是IDE设置的。
8、什么是可重入函数?C语言如何编写可重入函数
可重入函数是指能够被多个线程“同时”调用的函数,并且能保证函数结果正确性的函数。
在C语言种编写可重入函数时,尽量不要使用全局变量或静态变量,如果使用了全局变量或静态变量,就需要特别注意对这类变量访问的互斥。一般采用以下几种措施来保证函数的可重入性:信号量机制、关调度机制、关中断机制等方式。
需要注意的是,不要调用不可重写的函数,当调用了不可重入的函数时,会使该函数也变为不可重入的函数。一般驱动程序都是不可重写的函数,因此在编写驱动程序时一定要注意重入的问题。