进程控制的主要任务就是系统使用一些具有特定功能的程序端来创建、撤销进程以及完成进程各状态之间的转换,从而达到多进程、高效率、并发的执行和协调,实现资源共享的目的。
1、进程标识
每个进程都有唯一的、用非负整型表示的进程ID,这个ID就是进程标识符。起作用就如同身份证一样,因其唯一性,系统可以准确的定位到每一个进程。进程标识符的类型是pid_t,本质是一个无符号整数。
虽然是唯一的,但是进程ID是可复用的,当一个进程终止后,其ID就称为复用的候选者,大多数UNIX/Linux系统实现了延时复用算法,使得赋予新建进程的ID不同于最近终止进程所使用的ID。这防止将新进程误认为是使用同一个ID的某个已终止的进程。
一个进程标识符对应唯一进程,多个进程标识符可以对应同一个程序。所谓程序指的是可运行的二进制代码的文件,把这种文件加载到内存中运行就得到了一个进程。同一个程序文件加载多次就会得到不同的进程,因此进程标识符与进程之间是一一对应的,和程序是多对一的关系。

在Linux shell中,可以使用ps命令查看当前用户所使用的进程。
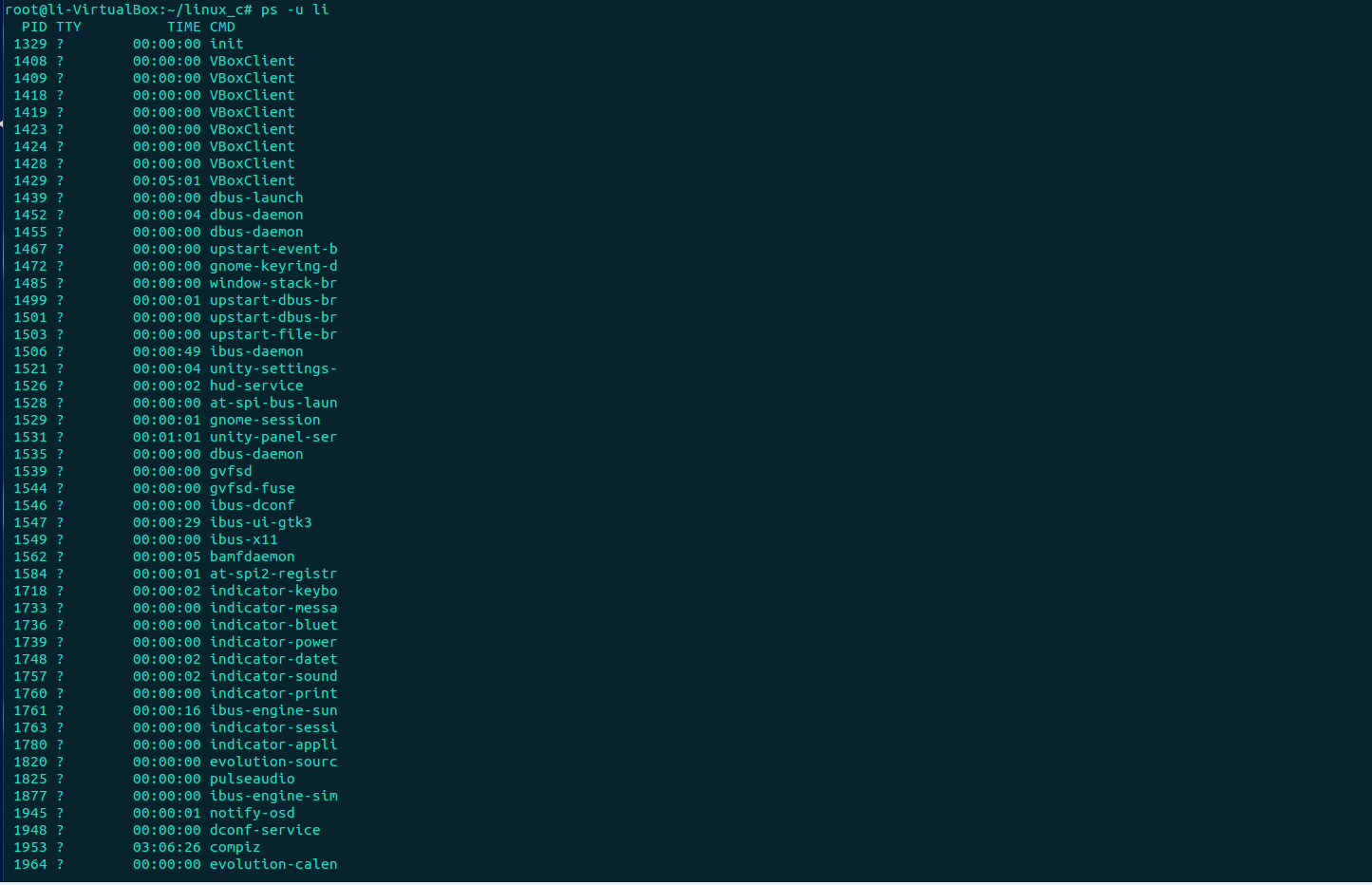
第一列内容是进程标识符(PID),这个标识符是唯一的;最后一列内容是进程的程序文件名。我们可以从中间找到有多个进程对应同一个程序文件名的情况,这是因为有一些常用的程序被多次运行了,比如shell和vi编辑器等。
每个进程都有6个重要的ID值,分别是:进程ID、父进程ID、有效用户ID、有效组ID、实际用户ID和实际组ID。这6个ID保存在内核中的数据结构中,有些时候用户程序需要得到这些ID。
例如,在/proc文件系统中,每一个进程都拥有一个子目录,里面存有进程的信息。当使用进程读取这些文件时,应该先得到当前进程的ID才能确定进入哪一个进程的相关子目录。由于这些ID存储在内核之中,因此,Linux提供一组专门的接口函数来访问这些ID值。
Linux环境下分别使用getpid()和getppid()函数来得到进程ID和父进程ID,分别使用getuid()和geteuid()函数来得到进程的用户ID和有效用户ID,分别使用getgid()和getegid()来获得进程的组ID和有效组ID,其函数原型如下:
#include <unistd.h> pid_t getpid(void); //获取进程ID pid_t getppid(void); //获取父进程ID uid_t getuid(void); //获取用户ID uid_t geteuid(void); //获取有效用户ID gid_t getgid(void); //获取组ID gid_t getegid(void); //获取有效组ID
函数执行成功,返回当前进程的相关ID,执行失败,则返回-1。
示例:
获取当前进程的ID信息:
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <sys/types.h> int main(int argc,char *argv[]) { pid_t pid=0,ppid=0; uid_t uid=0,euid=0; gid_t gid=0,egid=0; pid=getgid(); ppid=getppid(); uid=getuid(); euid=geteuid(); gid=getgid(); egid=getegid(); printf("当前进程ID:%u ",pid); printf("父进程ID:%u ",ppid); printf("用户ID:%u ",uid); printf("有效用户ID:%u ",euid); printf("组ID:%u ",gid); printf("有效组ID:%u ",egid); return 0; }
运行结果如图

2、进程创建
进程是Linux系统中最基本的执行单位。Linux系统允许任何一个用户创建一个子进程。创建之后,子进程存在于系统之中,并且独立于父进程。该子进程可以接受系统调度,可以分配到系统资源。系统能检测到它的存在,并且会赋予它与父进程同样的权利。
Linux系统中,使用函数fork()可以创建一个子进程,其函数原型如下:
#include <stdio.h> pid_t fork(void);
除了0号进程以外,任何一个进程都是由其他进程创建的。创建新进程的进程,即调用函数fork()的进程就是父进程。
函数fork()不需要参数,返回值是一个进程的ID。返回值情况有以下三种:
(1)对于父进程,函数fork()返回新创建的子进程的ID。
(2)对于子进程,函数fork()返回0.由于系统的0号进程是内核进程,所以子进程的进程号不可能是0,由此可以区分父进程和子进程。
(3)如果出错,返回-1。
fork的一个特性是父进程的所有打开文件描述符都被复制到子进程中去。在fork之后处理的文件描述符有两种常见的情况:
1. 父进程等待子进程完成。在这种情况下,父进程无需对其描述符做任何处理。当子进程终止后,子进程对文件偏移量的修改和已执行的更新。
2. 父子进程各自执行不同的程序段。这种情况下,在fork之后,父子进程各自关闭他们不需要使用的文件描述符,这样就不会干扰对方使用文件描述符。这种方法在网络服务进程中经常使用。
下面通过一个示例对此函数进行了解
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int global;
int main(int argc,char *argv[])
{
pid_t pid;
int stack=1;
int *heap=NULL;
heap=(int*)malloc(sizeof(int));
*heap=2;
pid=fork();
if(pid<0)
{
perror("fork()");
exit(1);
}
else if(pid==0)//0是第一个父进程
{
global++;
stack++;
(*heap)++;
printf("the child,data:%d,stack:%d,heap:%d
",global,stack,*heap);
exit(0);
}else
{
sleep(2);
printf("the child,data:%d,stack:%d,heap:%d
",global,stack,*heap);
exit(0);
}
return 0;
}
程序运行结果如下:

函数fork()会创建一个新的进程,并从内核中为此进程得到一个新的可用的进程ID,之后为这个新进程分配进程空间,并将父进程的进程空间中的内容复制到子进程的进程空间中,包括父进程的数据段和堆栈段,并且和父进程共享代码段。这时候,系统中又多出一个进程,这个进程和父进程一样,两个进程都要接受系统的调用。
下列两种情况可能会导致fork()的出错:
(1)系统中已经存在了太多的进程。
(2)调用函数fork()的用户进程太多。
一般系统中对每个用户所创建的进程数是有限的,如果数量不加限制,那么用户可以利用这一缺陷恶意攻击系统。
创建共享空间的子进程
进程在创建一个新的子进程之后,子进程的地址空间完全和父进程分开。父子进程是两个独立的进程,接受系统调度和分配系统资源的机会均等,因此父进程和子进程更像是一对兄弟。如果父子进程共用父进程的地址空间,则子进程就不是独立于父进程的。
Linux环境下提供了一个与fork()函数类似的函数,也可以用来创建一个子进程,只不过新进程与父进程共用父进程的地址空间,其函数原型如下:
#include <unistd.h> pid_t vfork(void);
现在通过一个示例对vfork()函数进行理解
#include <stdio.h> #include <stdlib.h> #include <unistd.h> int globvar = 6; int main(void) { int var; pid_t pid; var = 88; printf("before vfork "); if((pid = vfork()) < 0 ) { perror("vfork()"); } else if(pid == 0) { globvar ++; var ++; _exit(0); } printf("pid = %ld, glob = %d, var = %d ",(long)getpid(), globvar, var); exit(0); }
程序运行结果:

(1) vfork()函数产生的子进程和父进程完全共享地址空间,包括代码段、数据段和堆栈段,子进程对这些共享资源所做的修改,可以影响到父进程。由此可知,vfork()函数与其说是产生了一个进程,还不如说是产生了一个线程。
(2) vfork()函数产生的子进程一定比父进程先运行,也就是说父进程调用了vfork()函数后会等待子进程运行后再运行。
下面的示例程序用来验证以上两点。在子进程中,我们先让其休眠2秒以释放CPU控制权,在前面的fork()示例代码中我们已经知道这样会导致其他线程先运行,也就是说如果休眠后父进程先运行的话,则第(2)点则为假;否则为真。第(2)点为真,则会先执行子进程,那么全局变量便会被修改,如果第(1)点为真,那么后执行的父进程也会输出与子进程相同的内容。代码如下:
#include <stdio.h> #include <stdlib.h> #include <unistd.h> int global = 1; int main(void) { pid_t pid; int stack = 1; int *heap; heap = (int *)malloc(sizeof(int)); *heap = 1; pid = vfork(); if (pid < 0) { perror("fail to vfork"); exit(-1); } else if (pid == 0) { //sub-process, change values sleep(2);//release cpu controlling global = 999; stack = 888; *heap = 777; //print all values printf("In sub-process, global: %d, stack: %d, heap: %d ", global, stack, *heap); exit(0); } else { //parent-process printf("In parent-process, global: %d, stack: %d, heap: %d ", global, stack, *heap); } return 0; }
程序运行结果:

在使用vfork()函数时应该注意不要在任何函数中调用vfork()函数。下面的示例是在一个非main函数中调用了vfork()函数。该程序定义了一个函数f1(),该函数内部调用了vfork()函数。之后,又定义了一个函数f2(),这个函数没有实际的意义,只是用来覆盖函数f1()调用时的栈帧。main函数中先调用f1()函数,接着调用f2()函数。
//@file vfork.c //@brief vfork() usage #include <stdio.h> #include <stdlib.h> #include <unistd.h> int f1(void) { vfork(); return 0; } int f2(int a, int b) { return a+b; } int main(void) { int c; f1(); c = f2(1,2); printf("%d ",c); return 0; }
程序运行结果:

通过上面的程序运行结果可以看出,一个进程运行正常,打印出了预期结果,而另一个进程似乎出了问题,发生了段错误。出现这种情况的原因可以用下图来分析一下:

左边这张图说明调用vfork()之后产生了一个子进程,并且和父进程共享堆栈段,两个进程都要从f1()函数返回。由于子进程先于父进程运行,所以子进程先从f1()函数中返回,并且调用f2()函数,其栈帧覆盖了原来f1()函数的栈帧。当子进程运行结束,父进程开始运行时,就出现了右图的情景,父进程需要从f1()函数返回,但是f1()函数的栈帧已经被f2()函数的所替代,因此就会出现父进程返回出错,发生段错误的情况。
由此可知,使用vfork()函数之后,子进程对父进程的影响是巨大的,其同步措施势在必行。
3、父子进程
子进程完全复制了父进程地址空间的内容。但它并没有复制代码段,而是和父进程共用代码端。这样做是因为虽然由于子进程可能执行不同的流程,会改变数据段,但是代码是只读的,不存在被修改的问题,因此可共用。
从前面的示例中可以看出子进程对于数据段和堆栈端变量的修该并不能影响到父进程的进程环境。父进程的资源大部分能被fork()所复制,只有一小部分资源不同于子进程。子进程继承的资源情况如表所示

现在的Linux内核实现fork()函数时往往实现了在创建子进程时并不立即复制父进程的数据段和堆栈段,而是当子进程修改这些数据内容时复制才会发生,内核才会给子进程分配进程空间,将父进程的内容复制过来,然后继续后面的操作。这样的实现更加合理,对于一些只是为了复制自身完成一些工作的进程来说,这样做的效率会更高。这也是现代操作系统中一个重要的概念——“写时复制”的一个重要体现。
4、进程资源回收
当一个进程正常或异常终止时,内核会向其父进程发送SIGCHLD信号。因为子进程终止是个异步事件(这可以在父进程运行的任意时刻发生),所以这种信号也是内核向父进程发送的异步通知。父进程可以选择-忽略该信号,或者提供一个该信号发生时被调用执行的信号处理函数,对于这种信号,系统默认的是忽略它。
linux系统提供了函数wait()和waitpid()来回收子进程资源,其函数原型如下:
#include <sys/wait.h> #include <sys/types.h> pid_t wait(int *statloc); pid_t waitpidd(pid_t pid, int *statloc, int options);
这两个函数区别:
- wait如果在子进程终止前调用则会阻塞,而waitpid有一选项可以使调用者不阻塞。
- waitpid并不等待第一个终止的子进程--它有多个选项,可以控制它所等待的进程。
如果调用者阻塞而且它有多个子进程,则在其一个子进程终止时,wait就立即返回。因为wait返回子进程ID,所以调用者知道是哪个子进程终止了。
参数statloc是一个整型指针。如果statloc不是一个空指针,则终止状态就存放到它所指向的单元内。如果不关心终止状态则将statloc设为空指针。
这两个函数返回的整型状态由实现定义。其中某些位表示退出状态(正常退出),其他位则指示信号编号(异常返回),有一位指示是否产生了一个core文件等等。POSIX.1规定终止状态用定义在<sys/wait.h>中的各个宏来查看。有三个互斥的宏可用来取得进程终止的原因,它们的名字都已WIF开始。基于这三个宏中哪一个值是真,就可选用其他宏(这三个宏之外的其他宏)来取得终止状态、信号编号等。
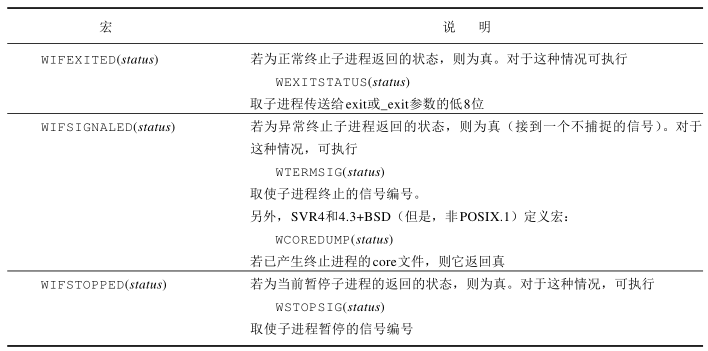
下面的程序中pr_exit函数使用上表中的宏以打印进程的终止状态。
#include <sys/types.h> #include <sys/wait.h> #include <stdio.h> #include <stdlib.h> void pr_exit(int status) { if (WIFEXITED(status)) { printf("normal termination, exit status=%d ", WEXITSTATUS(status)); } else if (WIFSIGNALED(status)) { printf("abnormal termination, signal number = %d ", WTERMSIG(status), #ifdef WCOREDUMP WCOREDUMP(status) ? "(core file generated)" : ""); #else ""); #endif } else if (WIFSTOPPED(status)) { printf("child stopped, signal number = %d ", WSTOPSIG(status)); } } int main(void) { pid_t pid; int status; if ((pid = fork()) < 0) { fprintf(stderr, "fork error"); } else if (pid == 0) { exit(7); } if (wait(&status) != pid) { fprintf(stderr, "wait error"); } pr_exit(status); if ((pid = fork()) < 0) { fprintf(stderr, "fork error"); } else if (pid == 0) { abort(); } if (wait(&status) != pid) { fprintf(stderr, "wait error"); } pr_exit(status); if ((pid = fork()) < 0) { fprintf(stderr, "fork error"); } else if (pid == 0) { status = 8; } if (wait(&status) != pid) { fprintf(stderr, "wait error"); } pr_exit(status); return 0; }
编译运行结果:

wait是只要有一个子进程终止就返回,waitpid可以指定子进程等待。对于waitpid的pid参数:
- pid == -1, 等待任一子进程。这时waitpid与wait等效。
- pid > 0, 等待子进程ID为pid。
- pid == 0, 等待其组ID等于调用进程的组ID的任一子进程。
- pid < -1 等待其组ID等于pid的绝对值的任一子进程。
对于wait,其唯一的出错是没有子进程(函数调用被一个信号中断,也可能返回另一种出错)。对于waitpid, 如果指定的进程或进程组不存在,或者调用进程没有子进程都能出错。 options参数使我们能进一步控制waitpid的操作。此参数或者是0,或者是下表中常数的逐位或运算。

竞态条件
当多个进程都企图对某共享数据进行某种处理,而最后的结果又取决于进程运行的顺序,则我们认为这发生了竞态条件(race condition)。如果在fork之后的某种逻辑显式或隐式地依赖于在fork之后是父进程先运行还是子进程先运行,那么fork函数就会是竞态条件活跃的孽生地。
如果一个进程希望等待一个子进程终止,则它必须调用wait函数。如果一个进程要等待其父进程终止,则可使用下列形式的循环:
while(getppid() != 1) sleep(1);
这种形式的循环(称为定期询问(polling))的问题是它浪费了CPU时间,因为调用者每隔1秒都被唤醒,然后进行条件测试。
为了避免竞态条件和定期询问,在多个进程之间需要有某种形式的信号机制。在UNIX中可以使用信号机制,各种形式的进程间通信(IPC)也可使用。
在父、子进程的关系中,常常有以下情况:在fork之后,父、子进程都有一些事情要做。例如:父进程可能以子进程ID更新日志文件中的一个记录,而子进程则可能要为父进程创建一个文件。在本例中,要求每个进程在执行完它的一套初始化操作后要通知对方,并且在继续运行之前,要等待另一方完成其初始化操作。这种情况可以描述为如下:
TELL_WAIT(); if ((pid = fork()) < 0) { err_sys("fork error"); } else if (pid == 0) { TELL_PARENT(getppid()); WAIT_PARENT(); exit(0); } TELL_CHILD(pid); WAIT_CHILD(); exit(0);
5、进程体替换
使用函数fork()创建新的进程后,子进程往往需要调用函数exec以执行另一个程序。当进程调用函数exec()时,该进程执行的程序完全替换为新程序,而新程序则从其函数main()开始执行。因为调用exec并不能创建新进程,所以前后的进程ID并未改变,函数exec指示用磁盘上的一个程序替换了当前进程的正文段、数据段、堆段和栈段。
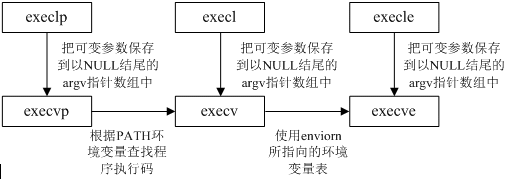
通常有6种exec()函数可供使用,它们统称为exec()函数族,我们可以使用其中任意一个。exec()函数族使Linux系统对进程的控制更加完善。使用fork()创建新进程,使用函数exec()执行新程序,使用函数exit()和wait()终止进程和等待进程终止。exec()函数原型如下:
#include <unistd.h> extern char **environ; int execl(const char *pathname, const char *arg0, ... /* (char *) 0 */); int execv(const char *pathname, char *const argv[]); int execle(const char *pathname, const char *arg0, ... /* (char *)0, char *const envp[] */); int execve(const char *pathname, char *const argv[], char *const envp[]); int execlp(const char *filename, const char *arg0, ... /* (char *) 0 */); int execvp(const char *filename, char *const argv[]);
这些函数之间的第一个区别是前四个取路径名作为参数,后两个取文件名作为参数。当制定filename作为参数时:
- 如果filename中包含/,则就将其视为路径名。
- 否则按PATH环境变量。
如果excelp和execvp中的任意一个使用路径前缀中的一个找到了一个可执行文件,但是该文件不是机器可执行代码文件,则就认为该文件是一个shell脚本,于是试着调用/bin/sh,并以该filename作为shell的输入。
第二个区别与参数表的传递有关(l 表示表(list),v 表示矢量(vector))。函数execl、execlp和execle要求将新程序的每个命令行参数都说明为一个单独的参数。这种参数表以空指针结尾。另外三个函数execv,execvp,execve则应先构造一个指向个参数的指针数组,然后将该数组地址作为这三个函数的参数。
最后一个区别与向新程序传递环境表相关。以 e 结尾的两个函数excele和exceve可以传递一个指向环境字符串指针数组的指针。其他四个函数则使用调用进程中的environ变量为新程序复制现存的环境。
六个函数之间的区别:

每个系统对参数表和环境表的总长度都有一个限制。当使用shell的文件名扩充功能产生一个文件名表时,可能会收到此值的限制。
归结起来,6个exec()函数之间的关系如下:
执行exec后进程ID没改变。除此之外,执行新程序的进程还保持了原进程的下列特征:
- 进程ID和父进程ID。
- 实际用户ID和实际组ID。
- 添加组ID。
- 进程组ID。
- 对话期ID。
- 控制终端。
- 闹钟尚余留的时间。
- 当前工作目录。
- 根目录。
- 文件方式创建屏蔽字。
- 文件锁。
- 进程信号屏蔽。
- 未决信号。
- 资源限制。
- tms_utime,tms_stime,tms_cutime以及tms_ustime值。
对打开文件的处理与每个描述符的exec关闭标志值有关。进程中每个打开描述符都有一个exec关闭标志。若此标志设置,则在执行exec时关闭该文件描述符,否则该描述符仍打开。除非特地用fcntl设置了该标志,否则系统的默认操作是在exec后仍保持这种描述符打开。
POSIX.1明确要求在exec时关闭打开目录流。这通常是由opendir函数实现的,它调用fcntl函数为对应于打开目录流的描述符设置exec关闭标志。
在exec前后实际用户ID和实际组ID保持不变,而有效ID是否改变则取决于所执行程序的文件的设置-用户-ID位和设置-组-ID位是否设置。如果新程序的设置-用户-ID位已设置,则有效用户ID变成程序文件的所有者的ID,否则有效用户ID不变。对组ID的处理方式与此相同。
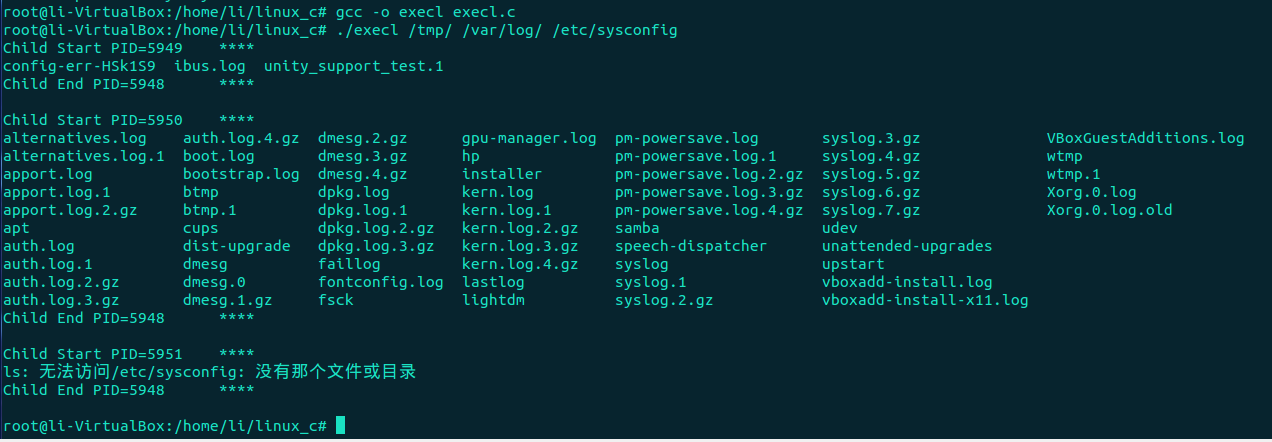
示例:使用execl()进行进程体替换
#include <stdio.h> #include <stdlib.h> #include <unistd.h> int main(int argc,char *argv[]) { int count =0; pid_t pd =0; if(argc<2) { printf("Usage Error! "); exit(1); } for(count=1;count<argc;count++)//指令输入多少个文件,创建多少个进程 { pd=fork(); if(pd<0) { perror("fork()"); exit(1); }else if(pd==0) { printf("Child Start PID=%d **** ",getpid());//创建进程成功输出当前进程PID execl("/bin/ls","ls",argv[count],NULL); //调用execl函数切换新进程,第一参数path字符指针所指向要执行的文件路径, 接下来的参数代表执行该文件时传递的参数列表:argv[0],argv[1]... 最后一个参数须用空指针NULL作结束。 perror("execl"); exit(1); } else { wait();//等待当前进程终止 printf("Child End PID=%d **** ",getpid()); } } exit(0); }
程序运行结果如下:
6、调用命令行
C程序调用shell脚本共同拥有三种法子 :system()、popen()、exec系列数call_exec1.c 。其中system() 不用你自己去产生进程。它已经封装了,直接增加自己的命令,使用起来最为方便,这里重点讲解Linux下使用函数system()调用Shell命令,其函数原型如下:
#include <stdlib.h> int system(const char *command);
参数command是需要执行的Shell命令。函数system的返回值比较复炸,其为一个库函数,封装了fork()、exec()、和waitpid(),其函数原型如下:
int system(const char * cmdstring) { pid_t pid; int status; if(cmdstring == NULL){ return (1); } if((pid = fork())<0){ status = -1; } else if(pid == 0){ execl("/bin/sh", "sh", "-c", cmdstring, (char *)0); -exit(127); //子进程正常执行则不会执行此语句 } else{ while(waitpid(pid, &status, 0) < 0){ if(errno != EINTER){ status = -1; break; } } } return status; }
其返回值需要根据着三个函数加以区分:
如果fork()或waitpid()执行失败,函数system()返回-1.
如果函数exec()执行失败,函数system的返回值于shell调用的exit的返回值一样,表示指定文件不可执行。
如果三个文件都执行成功,函数system()返回执行程序的终止状态,其值和命令“echo $”的值是一样的。
如果参数command所指向的字符串为NULL,函数system返回1,这可以用来测试当前系统是否支持函数system。对于Linux来说,其全部支持函数system。
函数system()的执行效率比较低:在函数system中要两次调用函数fork()和exec(),第一次加载Shell程序,第二次加载需要执行的程序(这个程序由Shell负责加载)。但是对比直接使用fork()+exec()的方法,函数system()虽然效率较低,却有以下优点:
(1)添加了出错处理函数
(2)添加了信号处理函数
(3)调用了wait()函数,保证不会出现僵尸进程。
示例:
使用system函数调用系统命令行
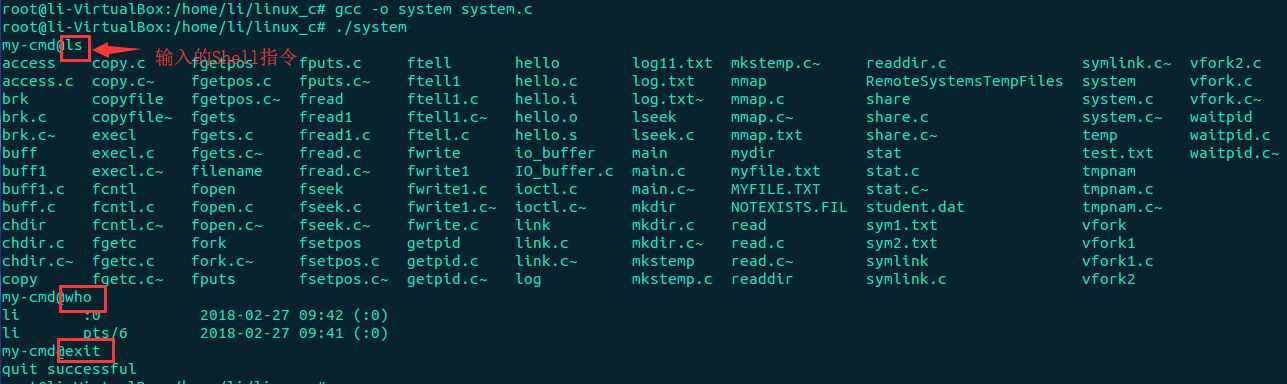
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> int main(int argc,char **argv[]) { char *command=NULL; int flag=0; command=(char*)malloc(1024*sizeof(char)); memset(command,0,1024*sizeof(char)); while(1) { printf("my-cmd@"); if(fgets(command,100,stdin)!=NULL) { if(strcmp(command,"exit ")==0) { puts("quit successful"); break; } flag=system(command); if(flag==-1) { perror("fork()"); exit(1); } memset(command,0,100); } } free(command); command=NULL; exit(0); }
程序运行结果:
7、进程时间
任一进程都可调用times函数以获得它自己及终止子进程的时钟时间、用户CPU时间和系统CPU时间。
#include <sys/times.h> clock_t times(struct tms *buf);
返回: 若成功则为经过的时钟时间,若出错则为-1此函数填写由buf指向的tms结构,该结构定义如下:
struct tms { clock_t tms_utime; /* 用户CPU时间 */ clock_t tms_stime; /* 系统CPU时间 */ clock_t tms_cutime; /* 终止子进程用户CPU时间 */ clock_t tms_cstime; /* 终止子进程系统CPU时间 */ }
此结构没有时钟时间。作为代替,times函数返回时钟时间作为函数值。此至是相对于过去的某一时刻度量的,所以不能用其绝对值而应该使用其相对值。例: 调用times,保存其返回值,在以后的某个时间再次调用times,从新返回的值中减去以前返回的值,此差值就是时钟时间。
所有由次函数返回的clock_t值都用_SC_CLK_TCK(由sysconf函数返回的每秒时钟滴答数)转换成秒数。