1.索引失效原因?
分析复合索引案例:表结构和索引如下
CREATE TABLE IF NOT EXISTS tem_0232( id INT(11) primary key AUTO_INCREMENT, t_name varchar(24) not null default'' comment'姓名', age int not null default 0 comment '年龄', pos varchar(20) not null default '' comment '职位', address varchar(100) not null default '' comment '地址' )ENGINE=InnoDB DEFAULT CHARSET=utf8 comment '员工表'; insert into tem_0232 values(1,'feifei',25,'manager','北京'),(2,'shishi',22,'dev','上海'),(3,'wanwan',26,'dba','广州'),(4,'weiwei',23,'uc','天津'); select * from tem_0232; alter table tem_0232 add index idx_tem0232_NameAgePos(t_name,age,pos); show index from tem_0232;
+----+--------+-----+---------+---------+
| id | t_name | age | pos | address |
+----+--------+-----+---------+---------+
| 1 | feifei | 25 | manager | 北京 |
| 2 | shishi | 22 | dev | 上海 |
| 3 | wanwan | 26 | dba | 广州 |
| 4 | weiwei | 23 | uc | 天津 |
+----+--------+-----+---------+---------+
4 rows in set (0.00 sec)
- 全值匹配 :多列索引,最好都使用上,如果使用一部分也要遵守左前缀法则:
- 最佳左前缀法则:如果是多列索引,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。
- 不在索引列上做任何操作(计算,函数,(自动or手动)类型转换),会导致索引失效而转向全表扫描
- 存储引擎不能使用索引中范围条件右边的列
- 尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select*
- mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
- is null,is not null 也无法使用索引
- like 以通配符开头('%abc...')mysql 索引失效会变成全表扫描
- 字符串不加单引号索引失效
- 少用or,用它来连接时会索引失效
分析1:不在索引列上做任何操作(计算,函数,(自动or手动)类型转换),会导致索引失效而转向全表扫描

type: 类型为all 全表扫描
分析2:存储引擎不能使用索引中范围条件右边的列

type:range 范围扫描 ,key_len:78,那么我们来算算,复合索引共三个字段的索引长度为:t_name长度 24*3+2=74 ,age长度 4, pos是20*3+2=62, 总共长度:74+4+62=140 ,而78 = 74+4 , 所以pos索引未使用
key_len的长度计算公式: varchr(10)变长字段且允许NULL : 10*(Character Set:utf8=3,gbk=2,latin1=1)+1(NULL)+2(变长字段) varchr(10)变长字段且不允许NULL : 10*(Character Set:utf8=3,gbk=2,latin1=1)+2(变长字段) char(10)固定字段且允许NULL : 10*(Character Set:utf8=3,gbk=2,latin1=1)+1(NULL) char(10)固定字段且不允许NULL : 10*(Character Set:utf8=3,gbk=2,latin1=1)
总结: 变长字段需要额外的2个字节,固定长度字段不需要额外的字节。而null都需要1个字节的额外空间,所以以前有个说法:索引字段最好不要为NULL,因为NULL让统计更加复杂,并且需要额外一个字节的存储空间。
分析3:尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select*

上面使用 * 查询 Extra Using index condition
下面使用 t_name,age,pos 查询 Extra Using where; Using index
他们唯一区别是 Extra里面的信息区别:
Using index condition : 会先条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行
Extra Using where; Using index: 使用到了索引 和 过滤条件
对 Extra 细谈:https://blog.csdn.net/poxiaonie/article/details/77757471
分析4:like 以通配符开头('%abc...')mysql 索引失效会变成全表扫描
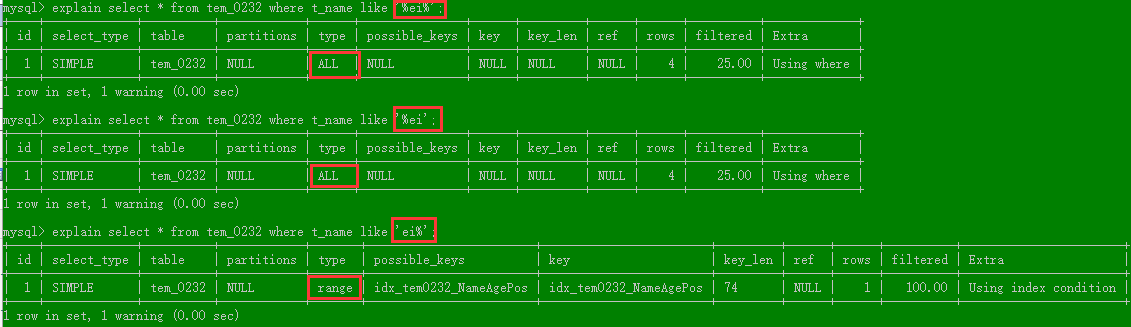
分析结果:使用like模糊查询时,%只能在右边,左边没有的情况下,索引列 才生效。
问题:如何解决like'%字符串%'时,索引不失效呢?
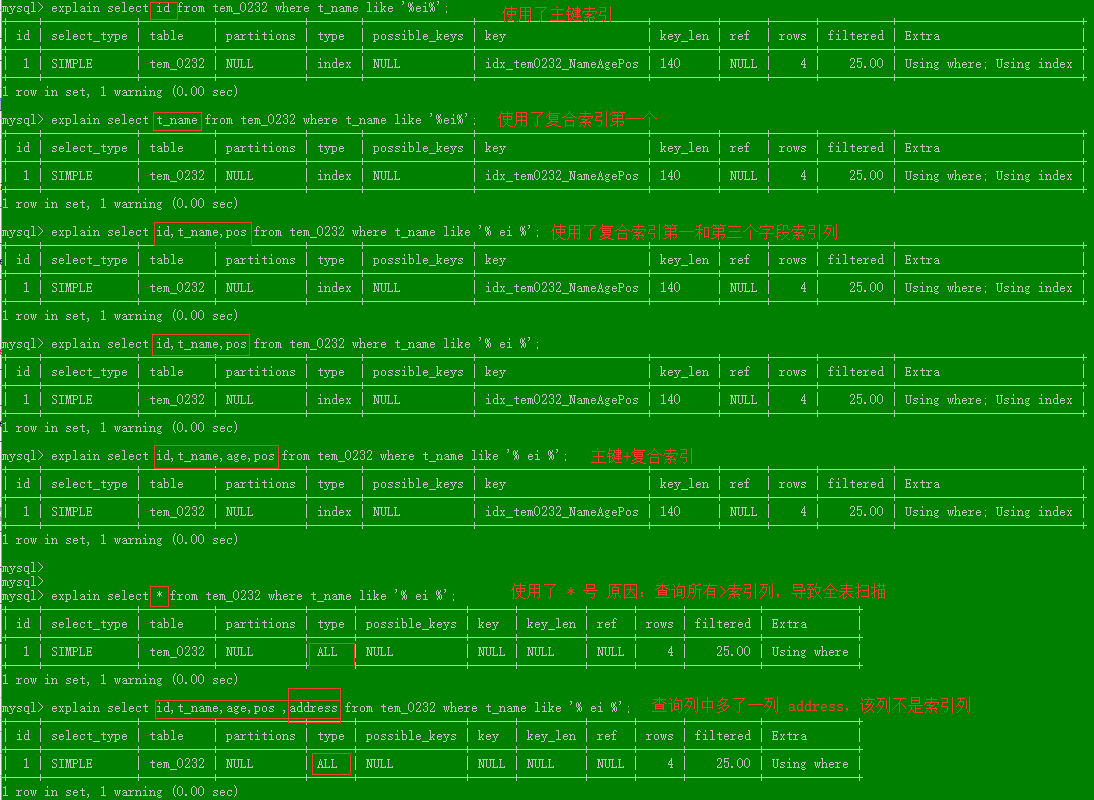
解决like查询 '%字符串%' 使用覆盖索引;
覆盖索引:查询列<=索引列
2.索引优化总结口诀
全值匹配我最爱,最左前缀要遵守;
带头大哥不能死,中间兄弟不能断;
索引列上少计算,范围之后全失效;
Like百分写最右,覆盖索引不写星;
不等空值还有or,索引失效要少用;
Var引号不可丢,SQL高级也不难!
3.练习题:
create table test03( id int primary key not null auto_increment, c1 char(10), c2 char(10), c3 char(10), c4 char(10), c5 char(10) ); insert into test03(c1,c2,c3,c4,c5)values('a1','a2','a3','a4','a5'); insert into test03(c1,c2,c3,c4,c5)values('b1','b2','b3','b4','b5'); insert into test03(c1,c2,c3,c4,c5)values('c1','c2','c3','c4','c5'); insert into test03(c1,c2,c3,c4,c5)values('d1','d2','d3','d4','d5'); insert into test03(c1,c2,c3,c4,c5)values('e1','e2','e3','e4','e5'); select * from test03; 【键索引】 create index idx_test03_c1234 on test03(c1,c2,c3,c4); show index from test03;
问题:我们创建了复合索引idx_test03_c1234 ,根据以下SQL分析索引使用情况?
1)索引全部使用
explain select * from test03 where c1='a1' and c2='a2' and c3='a3' and c4='a4';
2)索引全部使用
explain select * from test03 where c1='a1' and c2='a2' and c4='a4' and c3='a3';
3)索引c1c2c3使用 c4 未使用
explain select * from test03 where c1='a1' and c2='a2' and c3>'a3' and c4='a4';
4)索引全部使用
explain select * from test03 where c1='a1' and c2='a2' and c4>'a4' and c3='a3';
5)索引c1c2使用 c3作用在排序而不是查找 c4不使用
explain select * from test03 where c1='a1' and c2='a2' and c4='a4' order by c3;
6)索引c1c2使用 c3作用在排序而不是查找 和5题一样
explain select * from test03 where c1='a1' and c2='a2' order by c3;
7)索引c1c2使用 ,但出现 Using filesort
explain select * from test03 where c1='a1' and c2='a2' order by c4;
8.1)索引c1使用 ,但是c2,c3用于排序,无 filesort
explain select * from test03 where c1='a1' and c5='a5' order by c2,c3;
8.2)索引c1使用,出现filesort,我们建立索引1234,它没有按照顺序来,3 2 颠倒了
explain select * from test03 where c1='a1' and c5='a5' order by c3,c2;
9)索引c1c2使用,
explain select * from test03 where c1='a1' and c2='a2' order by c2,c3;
10)索引c1c2使用,但是c2、c3用于排序 ,无filesort
explain select * from test03 where c1='a1' and c2='a2' and c5='a5' order by c2,c3;
本例有常量c2的情况,和8.2对比 无filesort
explain select * from test03 where c1='a1' and c2='a2' and c5='a5' order by c3,c2;
11)索引c1使用
explain select * from test03 where c1='a1' and c4='a4' order by c2,c3;
12)索引c1使用, 出现了 Using where; Using temporary; Using filesort
explain select * from test03 where c1='a1' and c4='a4' order by c3,c2;
- groupby基本上都需要进行排序,会有临时表产生
- 定值、范围还是排序。一般orderby是给个范围