| 项目 | 内容 |
|---|---|
| 2020春季计算机学院软件工程(罗杰 任健) | 博客园班级博客 |
| 作业要求 | 团队项目选择 |
| 我们在这个课程的目标是 | 在团队合作中提升软件开发水平 |
| 这个作业在哪个具体方面帮助我们实现目标 | 进行项目调研、完成需求和技术分析 |
项目选择
需求:基于微软开源的OCR表单标注工具等开源模块,开发一个表单数据的识别和收集工具,对信息采集表、调查问卷表等各类表格式数据能够自动识别成可编辑的表格数据,并能将多页同类表格收集汇总为一个大表。
必备条件:熟悉机器学习,Android应用开发,较强的团队协作能力
需求分析
核心需求总结
- 基础功能:拍照扫描数字化图表内容
- 扩展功能:多个数字化图表合并储存
- 云端功能:手机或者web采集的数据在其他设备上迁移
NABCD 分析
- Need: 目前的OCR工具主要在通用文字识别方面功能比较完善,对具有逻辑性的表格识别需求应用空白。
- 大量的办公用表格需要电子化,而纸质填写的原件很多
- 大量表格是来自于统一模板,批量处理的需求很大
- Approach: 途径,利用react-native框架实现本软件的第一初步版本
- 优化:根据用户反馈和组内测试,优化产品的体验和用户交互逻辑
- 完善:针对一些特定的表格处理场景,做专门的优化
- Benifit: 本项目能够改善办公人群、学生人群、教师人群对表格下发、填写、处理、收集的体验
- 批量处理纸质原件,解决收集数字化数据的困难
- 原件和数字化数据统一管理,方便回溯原件,核实表格细节
- 表格归纳合并、解决传统表格填写需要传递的难点
- Competitors: 我们的分析团队对竞品现有的市场份额和竞品特点做了一些分析
- 腾讯OCR:五个大类,47个小类。大类包括:通用文字识别、卡证文字识别、票据单据识别、汽车相关识别、行业相关文档识别。在行业文档识别中,又分为表格识别,算式识别,数学公式识别,数学试题识别和保险单据识别。
- 阿里云OCR:产品的场景大类包括文档识别、卡证识别和KV结构模板
- 百度云OCR:分为网络图片文字识别、表格文字识别、数字识别、二维码识别、印章检测五个大类。对于表格文字识别,其介绍如下:支持识别具备完整框线的常规表格和含合并单元格的复杂表格,并可选择以JSON或Excel形式返回识别结果。对于无表格线版:支持识别无表格框线,但行、列位置明确的表格,并以JSON形式同步返回识别结果。
- Delivery:
- 学生群体:在可以在教学群中通过使用班级博客的教师、学生推广、微信推广
- github:在github上的release中交付,并推广到各个社交网络
- 应用商店:安卓各个应用商店,过审并交付
OCR的核心实体与核心需求
what is OCR
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。如何除错或利用辅助信息提高识别正确率,是OCR最重要的课题,ICR(Intelligent Character Recognition)的名词也因此而产生。衡量一个OCR系统性能好坏的主要指标有:拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等。
常见的软件结构
前期处理(图像处理)
- 图像输入与预处理
- 二值化
- 去噪
- 倾斜校正
中期处理(文本处理与排版)
- 版面分析
- 字符切割
- 字符识别
- 版面恢复
后期处理
- 后处理与校对
- 输出
核心实体
在后端需要完成从图片中抓取文字,完成文字的分割与识别
核心需求
高准确率的文字识别
版面识别与复原
Microsoft OCR from labeling tools
在传统的OCR基础上,还增加了label功能。
在train model时,用户给出自己的待识别文本,允许用户对文本进行标签,之后经过训练。
在对于其他的文本,则能通过模型对于文本抓取类似的label信息。
本应用需要用户提供大量已经标注过的表单数据,作为训练数据训练模型,最后用训练好的模型预测一张同类型的新表格,在新表上预测标注,并给出每处标注的置信度
输入:用户手动标注的表单,可以标注的表单格式PDF, JPEG,TIFF
训练:用Form Recognizer模块训练模型
输出:预测新表格的key/value特征
标注过程
识别表单的文本区域,并通过高亮给出文本框边界
用户新建标签类型
用户点击想要标注的文本区域,再点击对应的标签,完成标注
用户界面组成
preview pane 包含源地址中的表单列表
main editor pane 展示表单,用户使用标签标注表单文本的区域
tags editor pane 允许用户修改,记录和删除标签
微软开源OCR调研情况
核心功能定义:识别表单并进行标注
核心功能具体使用链
- 前提:所有训练文档格式相同。
- 标注训练集的表单并训练:通过API获得文档文本布局[识别表单元素]->标注表单元素->指定标注类型与格式->训练(train)
- 预测:上传非训练集的表单文档->预测(为表单生成标注)。
- 格式支持支持pdf、图片、TIFF等文件
- 额外功能-更多的是用户体验的角度:
- 保存项目与重启项目。
- 键盘快捷键的使用-支持方便快捷的标注操作。
源代码角度获得的信息
我认为比较核心的上层文件:
| 上层文件名 | 基本功能 |
|---|---|
| applicationState.ts | 定义了基本应用程序状态:设置、标签项目结构、存储类型、assets信息等等 |
| assetService.ts | 处理项目assets的一些方法 |
| connectionServece.ts | 连接服务 |
| ocrService.ts | 处理OCR |
| projectService.ts | 处理用户创建的整个项目 |
发布预测
我们现在可能的发布形式是web引用,或者是安卓app。
α版本:预计发布以后一周内的OCR的使用次数达到500,注册的用户量达到100。
β版本:预计发布以后一周内的OCR的使用次数达到1000,注册的用户量达到200。
γ版本:预计发布以后一周内的OCR的使用次数达到2000,注册的用户量达到400。
分析与设计
目前的软件架构分析:
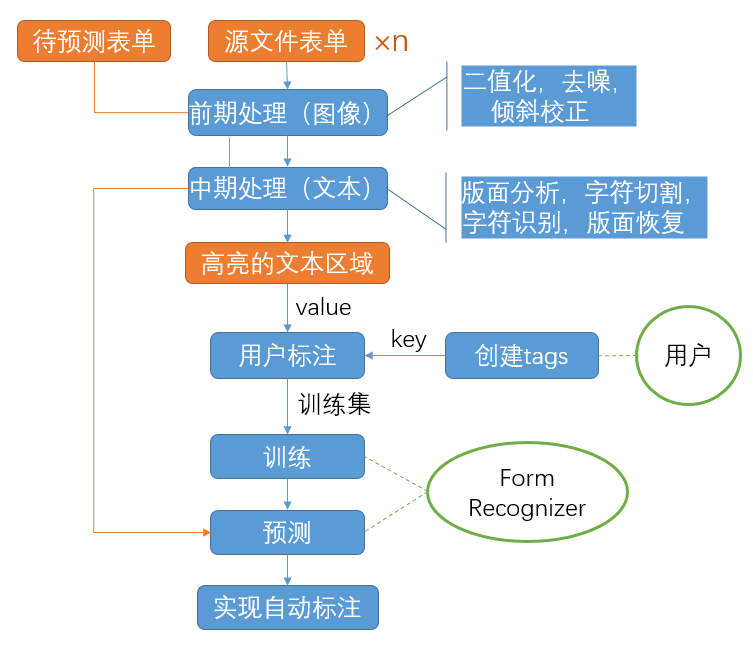
目前的用户交互设计
竞品分析
目前OCR软件的市场份额初步分析
| APP | Apple iOS store | Google Play Store | 华为应用市场 | vivo应用市场 |
|---|---|---|---|---|
| Text Scanner[OCR] | 3.2k | 87.7k | ||
| Microsoft Office Lens | 2.9k | 461.0k | ||
| Adobe Scan | 296.4k | 480.9k | ||
| FineScanner AI | 3.2k | |||
| Scanner Pro | 128.9k | |||
| OCR扫描王 | 500k | 380k | ||
| 扫描全能王 | 24,350k | |||
| 文字识别OCR | 370k | 120k | ||
| 扫描王OCR | 60k | |||
| 得力OCR文字识别 | 110k | |||
| 回识OCR文字识别 | 120k |
初步分工
| 成员 | 需求技术调研阶段 | alpha产品阶段 |
|---|---|---|
| 彭毛小民 | PM、协调总结各个人员汇总的技术细节、总结报告 | PM、对团队成员工作进行可视化管理、协同各个成员共同工作、加入框架开发 |
| 伦泽标 | 框架技术调研负责 | 引领团队框架技术开发,和OCR底层项目组对接 |
| 叶开辉 | 竞品项目和现有工具调研 | react框架相关成员 |
| 黎正宇 | 项目需求分析负责 | 开发设计待定 |
| 马延 | 项目需求分析成员,项目交互设计负责 | 云端数据库存储待定 |
| 肖思炀 | 微软OCR工具调研负责 | 引领OCR底层项目组,OCR底层项目与前端框架对接 |
| 赵涛 | 微软OCR工具调研成员 | OCR底层开发相关成员 |