1 kafka简介
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。

kafka是用于构建实时数据管道和流应用程序。具有横向扩展,容错,wicked fast(变态快)等优点,并已在成千上万家公司运行。
2 常用消息队列对比
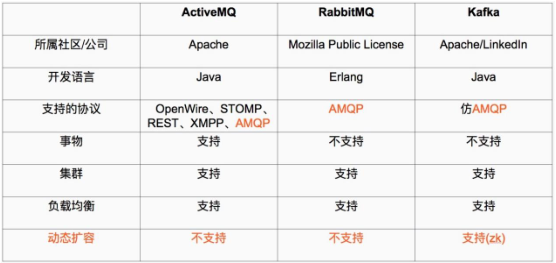
kafka相对于其他消息队列,最大的优势就是:具备分布式功能、并可以结合zookeeper实现动态扩容,kafka是一种高吞吐量的分布式发布订阅的消息系统。
3 kafka的优势
kafka通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够长时间的稳定性能。
高吞吐量:即使是非常普通的硬件,kafka也可以支持每秒数百万的消息。
支持通过kafka服务器分区消息。
支持Hadoop并行数据加载。
支持通过zookeeper进行动态扩容。
O(1)就是最低的时空复杂度,也就是耗时/耗空间与输入数据大小无关,无论输入数据增大多少倍,哈希算法就是典型的O(1)时间复杂度,无论数据规模多少,都可以在一次计算后找到目标。
4 kafka角色介绍
Topic:每条发布到kafka集群的消息都有一个类型,这个类别被称为topic(物理上不同topic的消息分开存储在不同的文件夹,逻辑上一个topic的消息虽然保存于一个或多个broker上,但用户只需指定消息的topic即可生产或消费数据儿不必关心数据存于何处),topic在逻辑上对record(记录、日志)进行分组保存,消费者需要订阅相应的topic才能消费topice中的消息。
partition:是物理上的概念,每个topic包含一个或多个partition,创建topic时,可指定partition数量,每个partition对应于一个文件夹,该文件夹下存储该partition的数据和索引文件,为了实现数据的高可用,比如将分区0的数据分散到不同的kafka节点,每一个分区都有一个broker作为leader和broker作为follower。
分区的优势:
1、实现存储空间的横向扩容,即将多个kafka服务器的空间结合利用。
2、提升性能,多服务器读写。
3、实现高可用,分区leader分布在不同的kafka服务器,比如分区0的leader为服务器A,则服务器B和服务器C为A的follower,而分区1的leader为服务器B,则服务器A和C为服务器的follower,而分区2的leader为C,则服务器A和B为C的follower。
Producer:负责发布消息到Kafka broker。
Consumer:消费消息,每个consumer属于一个特定的consuer group(可为每个consumer指点group name,若不指定group name则属于默认的group),使用consumer high level API时,同一topic的一条消息只能被同一个consumer group内的一个consumer消费,但多个consumer group可同时消费这一消息。
5 kafka部署
官方参考文档:https://kafka.apache.org/quickstart
部署三台服务器的高可用kafka环境。
环境:
server1 10.0.0.10
server2 10.0.0.20
server3 10.0.0.30
5.1 版本选择
北京外国语大学镜像源:https://mirrors.bfsu.edu.cn/apache/kafka/
清华大学镜像源:https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/
官方下载地址:http://kafka.apache.org/downloads
#kafka2.13-2.8.0版本更新内容
Kafka 2.8.0 includes a number of significant new features. Here is a summary of some notable changes:
-
Early access of replace ZooKeeper with a self-managed quorum
-
Add Describe Cluster API
-
Support mutual TLS authentication on SASL_SSL listeners
-
JSON request/response debug logs
-
Limit broker connection creation rate
-
Topic identifiers
-
Expose task configurations in Connect REST API
-
Update Streams FSM to clarify ERROR state meaning
-
Extend StreamJoined to allow more store configs
-
More convenient TopologyTestDriver construtors
-
Introduce Kafka-Streams-specific uncaught exception handler
-
API to start and shut down Streams threads
-
Improve TimeWindowedDeserializer and TimeWindowedSerde to handle window size
-
Improve timeouts and retries in Kafka Streams
5.2 部署kafka集群
部署kafka集群需要使用到zookeeper,所以需要先部署zookeeper。
5.2.1 zookeeper集群部署节点1配置
见上文
5.2.2 kafka集群部署
操作系统:debian10
java版本:1.8
kafka版本:2.13-2.8.0
节点1配置
#创建kafka文件夹
mkdir -p /apps/
#下载软件压缩包
cd /apps
wget https://mirrors.bfsu.edu.cn/apache/kafka/2.8.0/kafka_2.13-2.8.0.tgz
#解压压缩包
tar xvf kafka_2.13-2.8.0.tgz
#创建软连接
ln -sv kafka_2.13-2.8.0 kafka
#修改配置文件
cd /apps/kafka
root@debian10-10:/apps/kafka# grep ^[a-Z] config/server.properties
#集群唯一标识,为正整数
broker.id=1
#kafka监听的地址和端口
listeners=PLAINTEXT://10.0.0.10:9092
#服务器用于从网络接收请求并向网络发送响应的线程数
num.network.threads=3
#IO线程数
num.io.threads=8
#socket发送缓冲区大小
socket.send.buffer.bytes=102400
#socket接收缓冲区大小
socket.receive.buffer.bytes=102400
#socket请求缓冲区大小
socket.request.max.bytes=104857600
#kafka用于保存数据的目录,所有的消息都会存储在该目录当中,如果修改,则目录需要存在,不然kafka无法正常启动
log.dirs=/tmp/kafka-logs
#创建topic时默认存储其分区数
num.partitions=1
#每个数据目录的线程数用于启动时的日志恢复和关闭时的刷新。对于数据目录位于 RAID 阵列的安装,建议增加此值。
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
#设置kafka中保存消息的保存时间,默认为168小时,即7天
log.retention.hours=168
#日志文件最大大小
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
#连接zookeeper的地址和端口,zookeeper存储broker的元数据
zookeeper.connect=10.0.0.10:2181,10.0.0.20,2182,10.0.0.30:2181
#连接zookeeper的超时时间,默认18秒钟
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
#启动kafka
#命令启动
/apps/kafka/bin/kafka-server-start.sh /apps/kafka/config/server.properties
#systemctl启动
systemctl start kafka
节点2配置
#创建kafka文件夹
mkdir -p /apps/
#下载软件压缩包
cd /apps
wget https://mirrors.bfsu.edu.cn/apache/kafka/2.8.0/kafka_2.13-2.8.0.tgz
#解压压缩包
tar xvf kafka_2.13-2.8.0.tgz
#创建软连接
ln -sv kafka_2.13-2.8.0 kafka
#修改配置文件
cd /apps/kafka
root@debian10-20:/apps/kafka# grep ^[a-Z] config/server.properties
#集群唯一标识,为正整数
broker.id=2
#kafka监听的地址和端口
listeners=PLAINTEXT://10.0.0.20:9092
#服务器用于从网络接收请求并向网络发送响应的线程数
num.network.threads=3
#IO线程数
num.io.threads=8
#socket发送缓冲区大小
socket.send.buffer.bytes=102400
#socket接收缓冲区大小
socket.receive.buffer.bytes=102400
#socket请求缓冲区大小
socket.request.max.bytes=104857600
#kafka用于保存数据的目录,所有的消息都会存储在该目录当中,如果修改,则目录需要存在,不然kafka无法正常启动
log.dirs=/tmp/kafka-logs
#创建topic时默认存储其分区数
num.partitions=1
#每个数据目录的线程数用于启动时的日志恢复和关闭时的刷新。对于数据目录位于 RAID 阵列的安装,建议增加此值。
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
#设置kafka中保存消息的保存时间,默认为168小时,即7天
log.retention.hours=168
#日志文件最大大小
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
#连接zookeeper的地址和端口,zookeeper存储broker的元数据
zookeeper.connect=10.0.0.10:2181,10.0.0.20,2182,10.0.0.30:2181
#连接zookeeper的超时时间,默认18秒钟
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
#启动kafka
#命令启动
/apps/kafka/bin/kafka-server-start.sh /apps/kafka/config/server.properties
#systemctl启动
systemctl start kafka
节点3配置
#创建kafka文件夹
mkdir -p /apps/
#下载软件压缩包
cd /apps
wget https://mirrors.bfsu.edu.cn/apache/kafka/2.8.0/kafka_2.13-2.8.0.tgz
#解压压缩包
tar xvf kafka_2.13-2.8.0.tgz
#创建软连接
ln -sv kafka_2.13-2.8.0 kafka
#修改配置文件
cd /apps/kafka
root@debian10-30:/apps/kafka# grep ^[a-Z] config/server.properties
#集群唯一标识,为正整数
broker.id=3
#kafka监听的地址和端口
listeners=PLAINTEXT://10.0.0.30:9092
#服务器用于从网络接收请求并向网络发送响应的线程数
num.network.threads=3
#IO线程数
num.io.threads=8
#socket发送缓冲区大小
socket.send.buffer.bytes=102400
#socket接收缓冲区大小
socket.receive.buffer.bytes=102400
#socket请求缓冲区大小
socket.request.max.bytes=104857600
#kafka用于保存数据的目录,所有的消息都会存储在该目录当中,如果修改,则目录需要存在,不然kafka无法正常启动
log.dirs=/data/kafka/kafka-logs
#创建topic时默认存储其分区数
num.partitions=1
#每个数据目录的线程数用于启动时的日志恢复和关闭时的刷新。对于数据目录位于 RAID 阵列的安装,建议增加此值。
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
#设置kafka中保存消息的保存时间,默认为168小时,即7天
log.retention.hours=168
#日志文件最大大小
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
#连接zookeeper的地址和端口,zookeeper存储broker的元数据
zookeeper.connect=10.0.0.10:2181,10.0.0.20,2182,10.0.0.30:2181
#连接zookeeper的超时时间,默认18秒钟
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
#启动kafka
#命令启动
/apps/kafka/bin/kafka-server-start.sh /apps/kafka/config/server.properties
#systemctl启动
systemctl start kafka
5.2.3 测试搭建的集群是否可用
#先在10.0.0.10节点上创建topic
root@debian10-10:/apps/kafka/bin# /apps/kafka/bin/kafka-topics.sh --create --zookeeper 10.0.0.10:2181,10.0.0.20,2182,10.0.0.30:2181 --topic test --partitions 3 --replication-factor 1
Created topic test.
#验证topic
root@debian10-10:/apps/kafka/bin# /apps/kafka/bin/kafka-topics.sh --describe --zookeeper 10.0.0.10:2181,10.0.0.20,2182,10.0.0.30:2181 --topic test
Topic: test TopicId: gnVmp82nSRahYeqc9_6EQg PartitionCount: 3 ReplicationFactor: 1 Configs:
Topic: test Partition: 0 Leader: 2 Replicas: 2 Isr: 2
Topic: test Partition: 1 Leader: 1 Replicas: 1 Isr: 1
Topic: test Partition: 2 Leader: 2 Replicas: 2 Isr: 2
#获取所有topic
root@debian10-10:/apps/kafka/bin# /apps/kafka/bin/kafka-topics.sh --list --zookeeper 10.0.0.10:2181,10.0.0.20,2182,10.0.0.30:2181
__consumer_offsets
test
#测试发送消息
root@debian10-10:/apps/kafka/bin# ./kafka-console-producer.sh --broker-list 10.0.0.10:9092,10.0.0.20:9092,10.0.0.30:9092 --topic test
hello word
#在10.0.0.30上尝试消费,如果能消费,则表示集群搭建成功
root@debian10-30:/apps/kafka/bin# ./kafka-console-consumer.sh --bootstrap-server 10.0.0.30:9092 --topic test --from-beginning
hello word
#删除topic
root@debian10-10:/apps/kafka/bin# /apps/kafka/bin/kafka-topics.sh --delete --zookeeper 10.0.0.10:2181,10.0.0.20,2182,10.0.0.30:2181 --topic test
Topic test is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
[Unit]
Description=Apache Kafka Server
Documentation=http://kafka.apache.org/documentation.html
[Service]
Type=simple
#java目录
Environment=JAVA_HOME=/apps/java/jdk
#启动kafka
ExecStart=/apps/kafka/bin/kafka-server-start.sh /apps/kafka/config/server.properties
#停止kafka
ExecStop=/apps/kafka/bin/kafka-server-stop.sh
#重启kafka
Restart=on-abnormal
[Install]
WantedBy=multi-user.target