1、ANSI (American National Standards Institute,美国国家标准协会)制定的“ASCII”编码(American Standard Code for Information Interchange,美国信息互换标准代码)。那时世界上所有的计算机都用同样的ASCII方案来保存英文文字,是基于拉丁字母的一套电脑编码系统,主要是用于显示现代英语和其他西欧的语言,它是现今最通用的单字节编码系统,等同于国际标准ISO/IEC 646。
下面我们来看一下,ASCII表格。
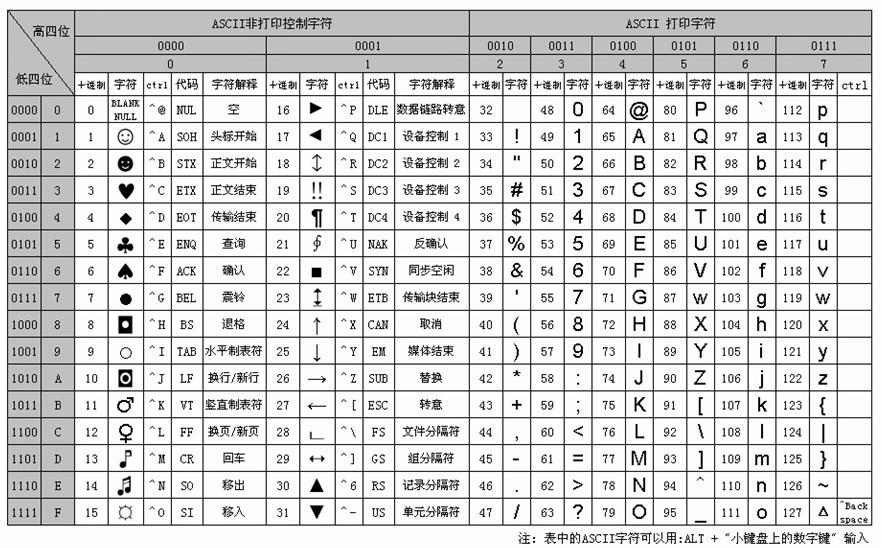
ASCII码为7位,占一个字节(最高为0),它存放时必须占全一个字节,也即占用8位。ASCII编码是由ANSI(美国国家标准协会)制定的一种包括数字、字母、通用符号、控制符号在内的字符编码集。
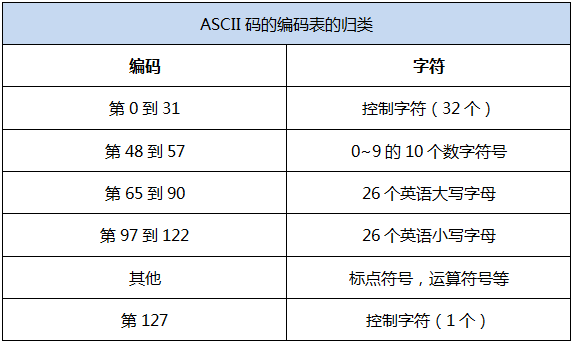
编码简单描述:
(1)ASCII码:美国人最初把自己的语言用计算表示,发现0-127可以表示数字、字母、通用符号、控制符号。(7位,占用1个字节。)
(2)ISO 8899-1:欧洲人研发,0-127是ASCII码,128-255加了一些特殊的字符。(占用1个字节。)
(3)GBK:中国人研发,兼容ASCII码来表示中文。(占用两个2字节。)
(4)Unicode:设计出全世界语言的对应编码,就像编了一本大汉语词典。
定义地址范围:3个字节(编码表的编号从0一直算到了100多万)。
字符都有唯一的编号,这就解决了解码的冲突。
没有为编码的二进制传输和二进制解码作出规定。
于是,就出现了如下解决方案:utf-8(1个字节), utf-16(2个字节), utf-32(4个字节)这些编码方案。
utf-8这种解决方案,用得最多,因为在当时它的方案最好,最节省资源。
utf-8为了节省资源,采用变长编码,编码长度从1个字节到6个字节不等。
1、对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2、对于n字节的符号(n>1),第一个字节的前n位都设为1,第n个字节的第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
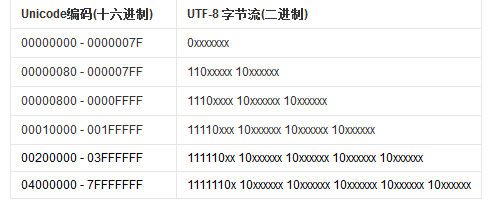
提问:后面字节的前两位一律设为10,为什么呢?
后面字节的前两位一律设为10(10000000也就是80)是因为必须要大于7F才和ASCII码分开。
下面,我们来宏观的看一下UTF-8和Unicode是怎么工作的吧?
