1、 查看当天的服务器日志信息(要求:在出现警告甚至警告级别以上的都要查询)
2、 能够查看服务器的所有用户的操作日志
3、 能够查询nginx服务器采集的日志(kibana作图)
4、 查看tomcat+log4j运行日志
5、 Mysql的慢查询日志
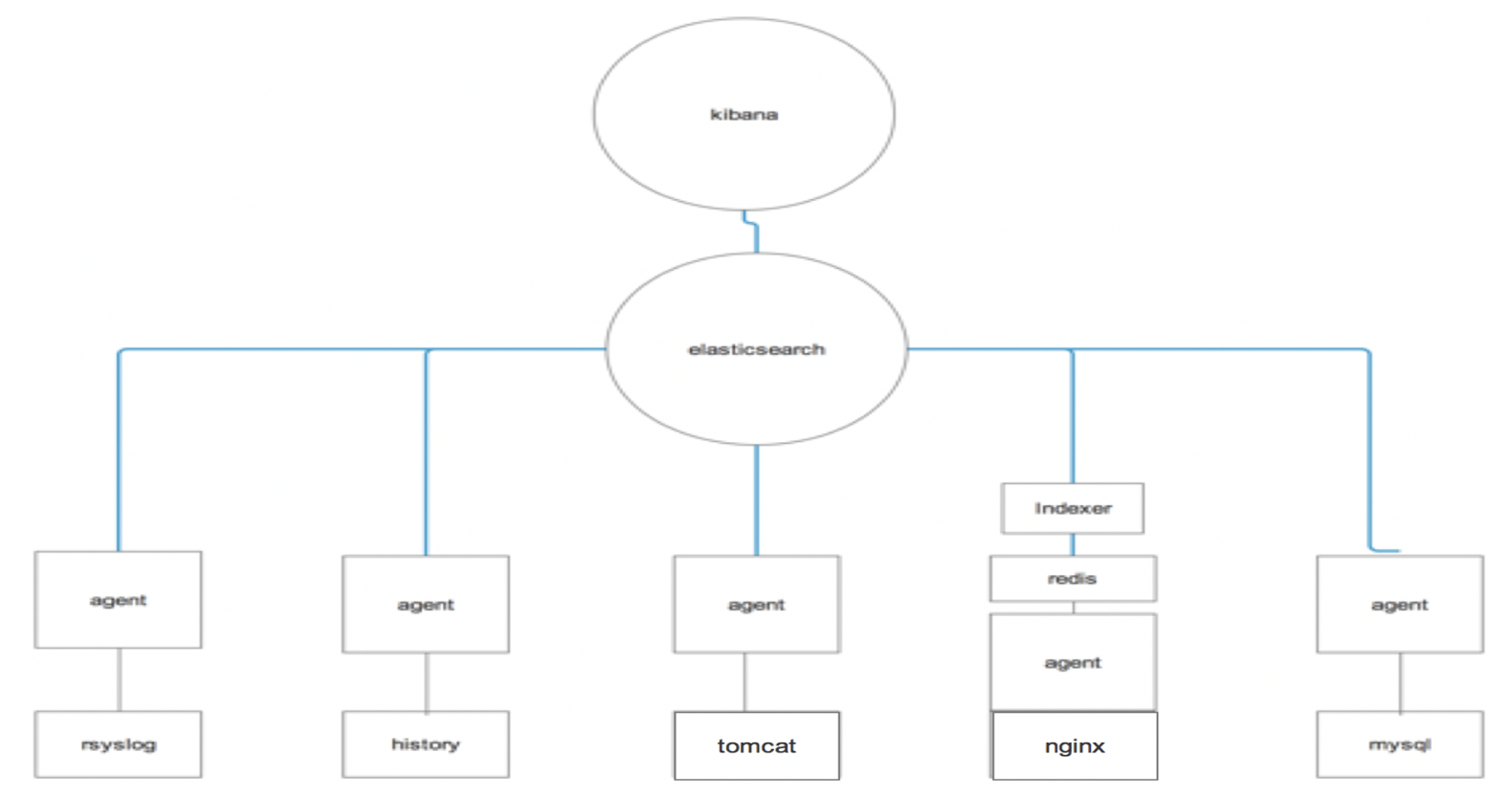
3.1:采集服务器日志
Rsyslog是CentOS6.X自带的一款系统日志工具:
1.支持多线程
2.支持TCP,SSL,TLS,RELP等协议
3.支持将日志写入MySQL, PGSQL, Oracle等多种关系型数据中
4.拥有强大的过滤器,可实现过滤系统信息中的任意部分
5.可以自定义日志输出格式
对于ELK stack来说,我们需要实时的知道当前系统运行的情况,如果当前系统出现了问题,能够及时发现,以免影响线上实例
Rsyslog配置文件介绍:/etc/rsyslog.conf文件:
| *.info;mail.none;authpriv.none;cron.none | /var/log/messages. | 各类型日志存放位置 |
|---|---|---|
| cron.* | /var/log/cron | 具体日志存放的位置 |
| authpriv.* | /var/log/secure | 认证授权认证 |
| mail.* | -/var/log/maillog | 邮件日志 |
| cron.* | /var/log/cron | 任务计划相关日志 |
| kern | 内核相关日志 | |
| lpr | 打印 | |
| mark(syslog) | rsyslog服务内部的信息,时间标识 | |
| news | 新闻组 | |
| user | 用户程序产生的相关信息 | |
| uucp | 协议 | |
| local 0~7 | 用户自定义日志级别 |
日志级别:
rsyslog共有7种日志级别,数字代号从 0~7。具体的意义如下所示:
0 debug –有调式信息的,日志信息最多
1 info 一般信息的日志,最常用
2 notice –最具有重要性的普通条件的信息
3 warning –警告级别
4 err –错误级别,阻止某个功能或者模块不能正常工作的信息
5 crit –严重级别,阻止整个系统或者整个软件不能正常工作的信息
6 alert –需要立刻修改的信息
7 emerg –内核崩溃等严重信息
本项目中,将日志界别调整成3 warning:
local3.* /var/log/boot.log
*.warning /var/log/warning_Log
然后将日志信息发送至6789端口:
*.* @@hadoop01:6789
这样系统在生成日志,同时也会将日志发送到6789端口
重启日志:/etc/init.d/rsyslog restart
编写logstash:Vim rsyslog.conf
input {
tcp {
port => "6789" #监控6789端口
type => "rsyslog" #日志类型是rsyslog
}
}
filter {
if [type] == "rsyslog" { # 做一次判断,只要从6789端口过来的rsyslog日志
grok { # 通过正则表达式,取出想要的字段
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:[%{POSINT:syslog_pid}])?: %{GREEDYDATA:syslog_message}" }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
}
date {
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] #将系统的日志格式化成标准国际化时间
}
}
}
output{ #将日志打入elasticsearch
if [type] == "rsyslog"{
stdout{codec=>rubydebug}
elasticsearch {
action => "index"
hosts => "hadoop01:9200"
index => "logstash-%{type}-%{+yyyy.MM.dd}"
}
}
}
启动logstash:
bin/logstash -f /usr/local/elk/logstash-5.5.2/conf/template/rsyslog.conf
通过telnet hadoop01 6789传输数据:
【注意,在logstash中的grok是正则表达式,用来解析当前数据】
Dec 23 12:11:43 louis postfix/smtpd[31499]: connect from unknown[95.75.93.154]
Jun 05 08:00:00 louis named[16000]: client 199.48.164.7#64817: query (cache) 'amsterdamboothuren.com/MX/IN' denied
Jun 05 08:10:00 louis CRON[620]: (www-data) CMD (php /usr/share/cacti/site/poller.php >/dev/null 2>/var/log/cacti/poller-error.log)
Jun 05 08:05:06 louis rsyslogd: [origin software="rsyslogd" swVersion="4.2.0" x-pid="2253" x-info="http://www.rsyslog.com"] rsyslogd was HUPed, type 'lightweight'.
然后去ip:9100查看日志是否生成:

用户在命令行环境下的操作日志都会被系统记录下来;比如我们输入history命令,都会展示出每一个用户输入过的命令;
.bash_history文件,这个日志格式可以定义成我们需要显示的内容,方便我们排查或者做入侵检查的时候使用;
自定义日志格式:
HISTFILESIZE=4000 #保存命令的记录总数
HISTSIZE=4000 # history 命令输出的记录数
HISTTIMEFORMAT='%F %T' #输出时间格式
export HISTTIMEFORMAT. #自定义日志输出格式,也就是取出我们想要的字段,以json的形式
HISTTIMEFORMAT修改线上的相关格式
PROMPT_COMMAND实时记录历史命令(一般用在存储history命令文件中)
vim /etc/bashrc
HISTDIR='/var/log/command.log'
if [ ! -f $HISTDIR ];then
touch $HISTDIR
chmod 666 $HISTDIR
fi
export HISTTIMEFORMAT="{"TIME":"%F%T","HOSTNAME":"$HOSTNAME","LI":"$(who am i 2>/dev/null| awk '{print $NF}'|sed -e's/[()]//g')","LOGIN_USER":"$(who am i|awk '{print$1}')","CHECK_USER":"${USER}","CMD":""
export PROMPT_COMMAND='history 1|tail -1|sed "s/^[ ]+[0-9]+ //"|sed "s/$/"}/">>/var/log/command.log'
export PROMPT_COMMAND='history >> /var/log/command.log'
最后source /etc/bashrc
配置logstash:Vim /conf/history.conf
input {
file {
path => ["/var/log/command.log"]
type => "command"
codec => "json"
}
}
output{
if [type] == "command"{
stdout{codec=>rubydebug}
elasticsearch {
hosts => "hadoop01:9200"
index => "history-%{+yyyy.MM.dd}"
}
}
}
启动logstash:
bin/logstash -f /usr/local/elk/logstash-5.5.2/conf/template/history.conf
去9100页面,查看是否已经把history日志灌入elasticsearch

3.3:项目之采集nginx日志
在企业中, 日志量非常大,如果直接采用:
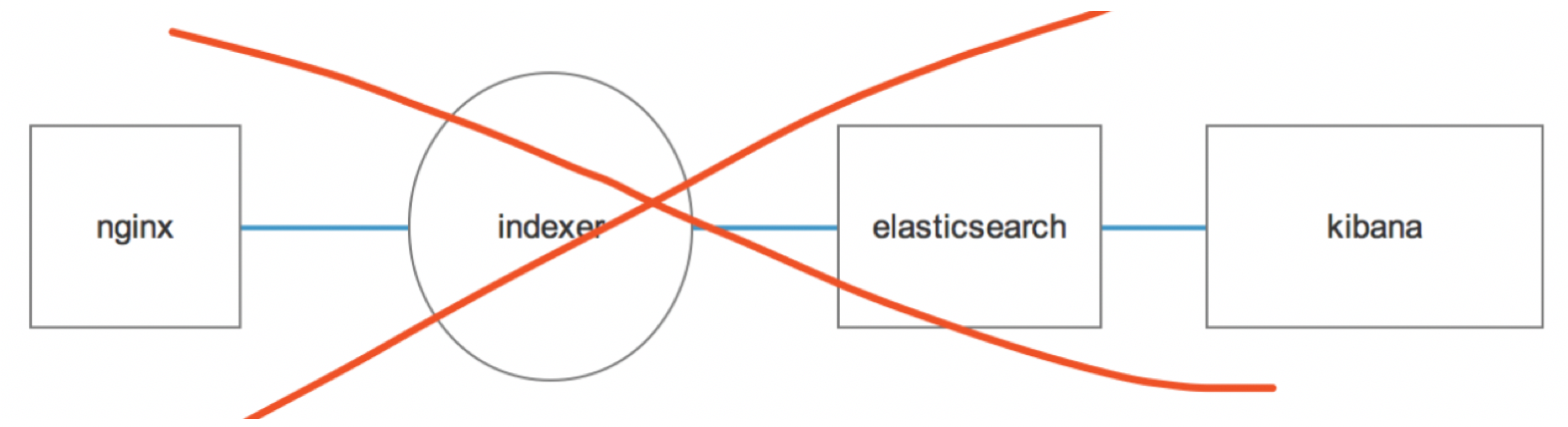
会出现这样一种情况:logstash瞬间采集大量日志(同一时间要存储的数据量已经超过elasticsearch的最大连接数),这个时候elasticsearch会忽略继续存储的数据,也就是所谓的丢数据现象;
那么为了不让logstash采集的数据突发、井喷的方式将数据灌入elasticsearch;最合理的方式是在中间介入缓冲队列:kafka、rubbitMQ、redis等
我们采用的架构师:

Nginx中生成的日志格式:
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
Nginx采集的日志配置

agent的目的是将nginx中的日志采集到hadoop01的redis中,这种agent只是做日志发送,对性能影响不大,读取access.log.1日志文件,并且发送到远端redis。
配置:Vim nginx.conf
input {
file {
path => ["/usr/local/nginx/logs/agent.log"]
type => "nginx_access"
}
}
output {
if [type] == "nginx_access"{
redis {
host => ["hadoop01:6379"]
data_type =>"list"
db => 3
key => "agent"
}
}
stdout{codec=>rubydebug}
}
启动logstash
bin/logstash -f myconf/nginx_redis.conf --path.data=/home/angel/logstash-5.5.2/logs
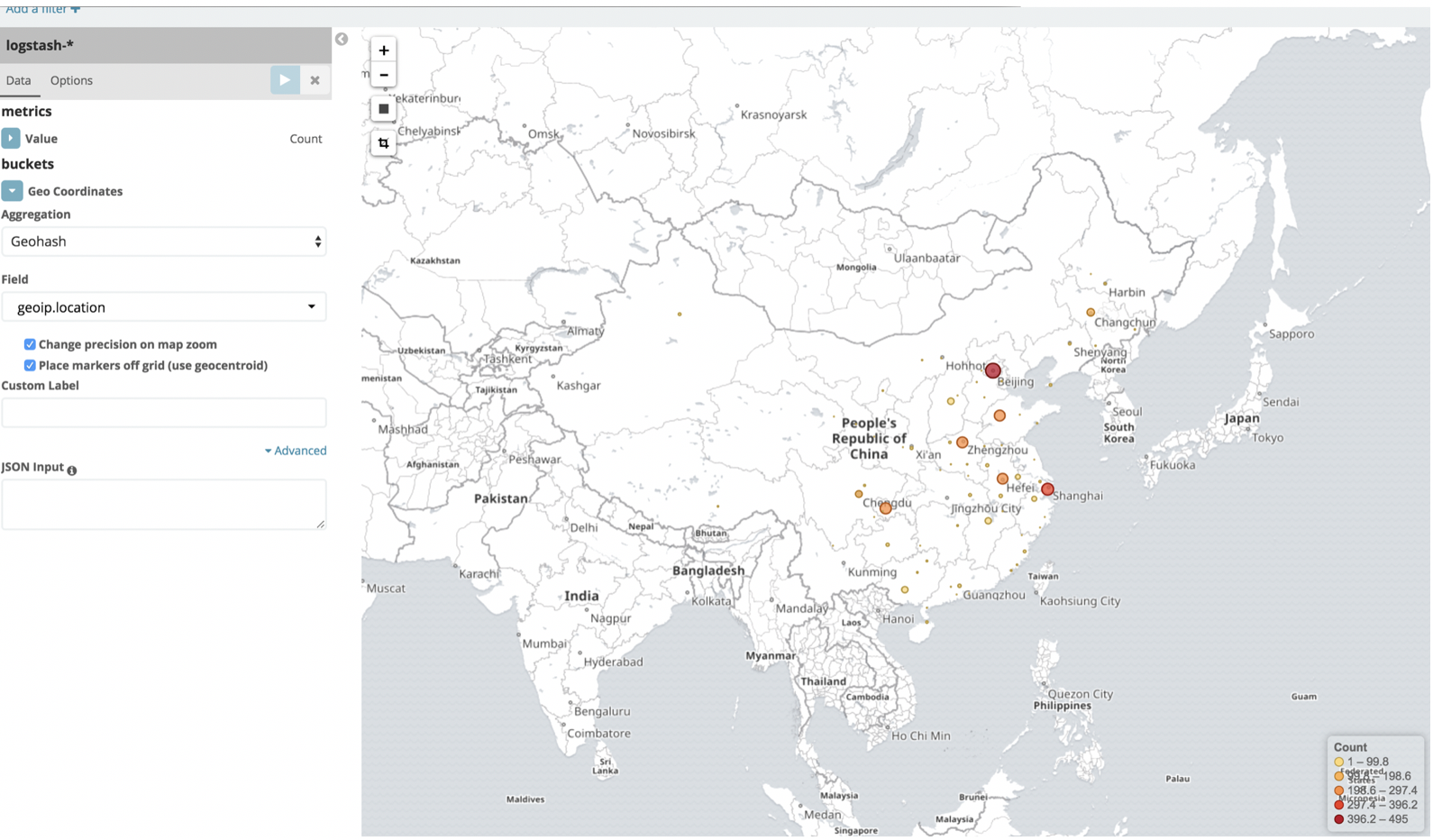
使用实际成产数据做测试数据,方便观察地理位置:
cat /usr/local/generator_nginx_data/access.log >> /usr/local/nginx/logs/access.log.1
观察redis是否出现nginx的key:

Vim indexer.conf
input{
redis {
host => "hadoop01"
port => 6379
data_type => "list"
key => "agent"
db => 3
}
}
filter {
date {
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
}
grok {
match => {
"message" => "%{IPORHOST:remote_addr} - %{NGUSER:remote_addr} [%{HTTPDATE:time_local}] "(?:%{WORD:request} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{NUMBER:status} %{NUMBER:body_bytes_sent} %{QS:http_referer} %{QS:agent} %{NOTSPACE:http_x_forwarded_for}"
}
}
geoip{
source => "remote_addr"
database => "/home/angel/logstash-5.5.2/conf/GeoLite2-City.mmdb"
target => "geoip"
add_field => [ "[geoip][coordinates]", "%{[geoip][longitude]}" ]
add_field => [ "[geoip][coordinates]", "%{[geoip][latitude]}" ]
#fields => ["country_name", "region_name", "city_name", "latitude", "longitude"]
}
mutate {
convert => [ "[geoip][location]", "geo_point" ]
}
}
output {
stdout{codec=>rubydebug}
elasticsearch {
action => "index"
hosts =>"hadoop01:9200"
index => "redis-es-%{+yyyy.MM.dd}"
}
}
启动:bin/logstash -f /usr/local/elk/logstash-5.5.2/conf/template/indexer.conf
然后观察elasticsearch,是否已经插入数据;
Kibana生成高德地图:
Logstash分析tomcat日志是最复杂的,没有之一;
下面给出tomcat的日志格式:
Caused by: org.I0Itec.zkclient.exception.ZkTimeoutException: Unable to connect to zookeeper server within timeout: 5000
at org.I0Itec.zkclient.ZkClient.connect(ZkClient.java:876)
at org.I0Itec.zkclient.ZkClient.<init>(ZkClient.java:98)
at org.I0Itec.zkclient.ZkClient.<init>(ZkClient.java:92)
at org.I0Itec.zkclient.ZkClient.<init>(ZkClient.java:80)
at com.alibaba.dubbo.remoting.zookeeper.zkclient.ZkclientZookeeperClient.<init>(ZkclientZookeeperClient.java:29)
at com.alibaba.dubbo.remoting.zookeeper.zkclient.ZkclientZookeeperTransporter.connect(ZkclientZookeeperTransporter.java:10)
at com.alibaba.dubbo.remoting.zookeeper.ZookeeperTransporter$Adpative.connect(ZookeeperTransporter$Adpative.java)
at com.alibaba.dubbo.registry.zookeeper.ZookeeperRegistry.<init>(ZookeeperRegistry.java:69)
at com.alibaba.dubbo.registry.zookeeper.ZookeeperRegistryFactory.createRegistry(ZookeeperRegistryFactory.java:37)
at com.alibaba.dubbo.registry.support.AbstractRegistryFactory.getRegistry(AbstractRegistryFactory.java:94)
at com.alibaba.dubbo.registry.RegistryFactory$Adpative.getRegistry(RegistryFactory$Adpative.java)
at com.alibaba.dubbo.registry.integration.RegistryProtocol.refer(RegistryProtocol.java:240)
at com.alibaba.dubbo.rpc.protocol.ProtocolListenerWrapper.refer(ProtocolListenerWrapper.java:63)
at com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper.refer(ProtocolFilterWrapper.java:60)
at com.alibaba.dubbo.rpc.Protocol$Adpative.refer(Protocol$Adpative.java)
at com.alibaba.dubbo.config.ReferenceConfig.createProxy(ReferenceConfig.java:392)
at com.alibaba.dubbo.config.ReferenceConfig.init(ReferenceConfig.java:300)
at com.alibaba.dubbo.config.ReferenceConfig.get(ReferenceConfig.java:138)
at com.alibaba.dubbo.config.spring.ReferenceBean.getObject(ReferenceBean.java:65)
at org.springframework.beans.