KNN算法是采用测量不同特征向量之间的距离的方法进行分类。
工作原理:存在一个数据集,数据集中的每个数据都有对应的标签,当输入一个新的没有标签的数据时,KNN算法找到与新数据特征量最相似的分类标签。
KNN算法步骤:
(1)选择邻近的数量k和距离度量方法;
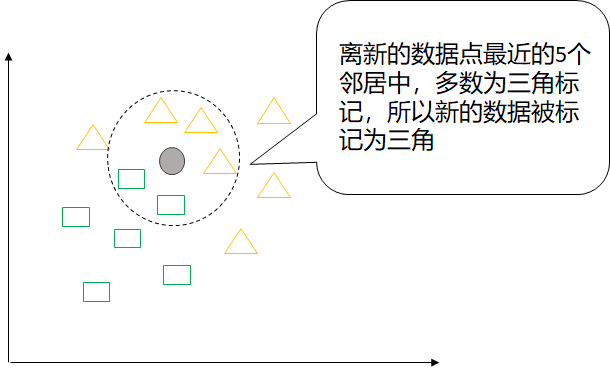
(2)找到待分类样本的k个最近邻居;
(3)根据最邻近的类标进行多数投票。
KNN算法优点:精度高,对异常值不敏感,无数据输入假定;
缺点:计算复杂度高,空间复杂度高。
适用范围:数值型、标称型
python 代码:
KNeighborsClassifier中的参数
| 参数 | 含义 |
| n_neighbors | k值,默认为5 |
| weights |
k个近邻样本的权重。可选值:uniform、distance,默认为uniform。 uniform:所有最近邻样本权重一样; distance:权重和距离成反比; 还可以自定义权重,即自定义一个函数,输入距离值,输出权重值。 |
| algorithm |
算法,可选值:'auto', 'ball_tree', 'kd_tree', 'brute'。 'ball_tree':球树实现 'kd_tree':KD树实现 'brute’:蛮力实现 'auto':会在上述三种算法中做权衡,选择一个拟合最好的最优算法。 |
| leaf_size |
用于控制KD树或球树停止建子树的叶子节点阈值,默认为30。这个值越小,生成的KD树或球树越大,层数越深,耗时越长。 随着样本的增加,这个值要增加。 |
| metric | 距离度量,默认为'minkowski' 即闵可夫斯基距离。 |
| p | 距离度量参数metric附属参数,只用于'minkowski'中p值的选择,p=1,位曼哈顿距离,p=2位欧式距离,默认为2。 |
| metric_params | 距离度量的其他附属参数,主要用于带权重闵可夫斯基距离的权重,以及其他一些复杂的距离度量的参数。 |
| n_jobs | 并行处理任务数,默认值为1。 |
#KNN
1 import numpy as np
2 import pandas as pd 3 from sklearn.neighbors import KNeighborsClassifier
4 df=pd.read_csv(r'E:data analysis estclassification.csv')#训练数据集
5 df_test=pd.read_csv(r'E:data analysis estclassification_test.csv')#测试数据集
6 x=df.ix[:,:-1] #特征值
7 y=df.ix[:,-1] #目标变量
8 knn=KNeighborsClassifier(n_neighbors=5) #取得knn分类器
9 knn.fit(x,y) #导入数据进行训练
10 print(knn.predict (df_test)) #对新数据进行分类