(本篇文章为本人学习记录,没有写的很规范,仅供本人学习期间记录使用),也没有记录的特别全,有些我也没有写进来,熟悉一下,以后用到不会就百度吧。
DML(data manipulation language)数据操纵语言:就是我们最经常用到的 SELECT、UPDATE、INSERT、DELETE。 主要用来对数据库的数据进行一些操作。
DDL(data definition language)数据库定义语言:就是我们在创建表的时候用到的一些sql,比如说:CREATE、ALTER、DROP等。DDL主要是用在定义或改变表的结构,数据类型,表之间的链接和约束等初始化工作上
DML可回滚,DDL不可回滚
因此,事务只能用于增删,操作表结构这些都无法使用事务,因为它不写入内存,当然无法回滚。
truncate table zzznew --清空表数据 仍然无法回滚
而delete from zzznew --清空表数据,是可以回滚的
因为truncate 位于DDL,而delete位于DML

个人觉得重要的是相关子查询,相关子更新,相关删除,with等..
--返回比本部门平均工资高的员工的last_name,department_id,salary以及平均工资 --方法一(在from语句中使用子查询) select last_name,department_id,salary,e2.avg(salary) from employees e1,(select department_id,avg(salary) from employees e2 group by department_id) e2 where e1.department_id=e2.department_id and e1.salary>e2.avg(salary) --方法二(相关子查询) select last_name,department_id,salary,(select avg(salary) from employees group by department_id) avg_salary from employees e1 where salary>( select avg(salary) from employees e2 where e1.department_id=e2.department_id group by department_id )
--更新zzznew表按照key排序的前5条,且其值为id值和本表key值相同的那条记录的column1值 update zzznew set col1=(select column1 from AAA where id=zzznew.key) where key in( select key from (select * from zzznew order by key) where rownum<5 )
--查询公司各部门的总工资大于公司按部门的工资的平均值的部门信息 with dept_costs as --每个部门的工资总额 (select depatertment_name ,sum(salary) dept_total from employees e,departments d where e.department_id=d.department_id group by depatertment_name ), avg_cost as--公司按部门的平均工资 (select sum(dept_total)/count(*) dept_avg from dept_costs ) select * from dept_costs where dept_total>(select dept_avg from avg_cost) order by depatertment_name
个人领悟:组函数之间可以嵌套,但是追踪到内部的字段都必须是from查询表的字段,而不能在组函数内部搞一个select
对于分组函数中,若显示的不是组函数,而是单个列,那么列一定要在group by中!
如下:因为查询的department_name与location_id并未包含组函数,因此必须放入group by中才可以显示出来
select department_name,location_id,count(employee_id),avg(salary) from employees e join departments d on e.department_id=d.department_id group department_name,location_id
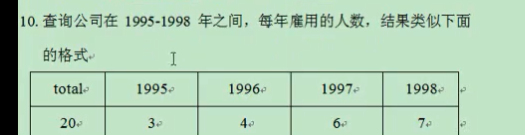
select count(*) "total",count(decode(to_char(hire_date,'yyyy'),'1995',1, null)) "1995", count(decode(to_char(hire_date,'yyyy'),'1996',1, null)) "1996", count(decode(to_char(hire_date,'yyyy'),'1997',1, null)) "1997", count(case to_char(hire_date,'yyyy') when '1998' then 1 else null end) "1998"--两种方式,还是decode方便些 from employees where to_char(hire_date,'yyyy') in (1995,1996,1997,1998) --where hire_date between to_date(1995,'yyyy') and to_date(1999,'yyyy')
个人学习记录:
--drop table ZZZWOCA --导入sql执行语句 @d:/a.sql --查询列 desc ZZZNEW --sql中除了别名使用双引号其余基本都是单引号 --AS后加双引号按照引号内字符串大小写命名,否则默认全大写(必须双引号) select key "id",col1 column1 from ZZZNEW --oracle连接符使用||(用于连接多列值合并为1列)(必须单引号才能表示字符串) select key||'的列值是'||col1 as "newCol" from ZZZNEW --查询名字中含有_ (escape规定转义字符,一般都规定为转义字符) select key,col1 from ZZZNEW where col1 like '%\_%' escape'' --函数(lower upper initcap(首字母大写)) select COL1 from ZZZNEW where upper(COL1)='CES1' --去除两边的h select trim('h' from 'hhelhloh') from dual --将所有满足条件的全部替换 select replace('hehllo','h','H') from dual --指定日期的最后一天last_day select last_day(sysdate)-1 from dual --查询倒数第二天 select * from ZZZNEW WHERE CREATEDATE=LAST_DAY(CREATEDATE)-1 --查询创建时间为创建时那月的倒数第二天创建的 select ROUND(col1,0) FROM ZZZNEW where key='1'
--7代表接下来的星期六 因为oracle索引从1开始,1为星期天
select sysdate,next_day(sysdate,7) from dual --date char之间转换 (有特殊符号需要使用双引号) select createdate from ZZZNEW where to_char(createdate,'yyyy"年"mm"月"dd"日"')='2018年10月31日' select createdate from ZZZNEW where to_date('2018年10月31日','yyyy"年"mm"月"dd"日"')=createdate --char number之间转换(使用9数字)(用0设置的长度数字不够则使用0补充)(L人民币(local),$ 美元) --9:数字;0:零;L:人民币符号;$:美元符号;,:千分符;.:小数点 (就这些) select to_char(123456.78,'L999,999,999.99') from dual select to_char(123456.78,'$000,000,000.000') from dual select to_number('123,456.78','999,999,999.99') from dual select to_number('$132.2','$999.9') from dual select to_number('¥123,456.2','L999,999,999.99') from dual --通用函数 --nvl(exp1,exp) 若exp1为空则使用exp2代替,否则就是本身 select 1+nvl(null,0) from dual --1 select 1+nvl(1,0) from dual --2 select key,nvl(col2,'没有时间**') from ZZZNEW --当col2为null的时候显示没有时间**,否则显示自己 select key,nvl(to_char(createdate,'yyyy-mm-dd'),'没时间') from ZZZNEW --nvl2(exp1,exp2,exp3) exp1不为空返回exp2 否则返回exp3 select 1+nvl2(null,0,100) from dual --101 select 1+nvl2(5,0,1) from dual --1 --nullif(exp1,exp2) 若二者相同,返回null 否则返回exp1 (二者类型必须相同) select nullif(5,5) from dual --相同,返回null select nullif(5,1) from dual --不等,返回5 --oracle中的if-else --1.case (filed) when (exp1) then (exp2) [when (exp1) then (exp2)] else (exp3) end select department_id,last_name case department_id when 10 salary*1.1 when 20 salary*1.2 else salary*1.3 end as new_salary_col from employees where department_id in (10,20,30) --2.decode(filed,exp1,exp2[,exp1,exp2],defalut) select department_id,last_name decode(department_id,10,salary*1.1 ,20,salary*1.2 ,30,salary*1.3 ,salary) as new_salary_col from employees select z1.key,z1.col1,z2.col2 from ZZZNEW z1 join ZZZNEW z2 on z1.col1=z2.col2 --组函数 --avg() max() min() count() sum() stadev()标准差 --count(ex)仅仅包含ex非空的数量 select avg(CC) from(SELECT nvl(C,0) as CC from ZZZNEW) select sum(c)/count(*) as "cc" from zzznew select count(distinct(c)) from zzznew select avg(nvl(c,0)) from zzznew --使用group by这样的函数 列出的除了组函数,其余的列必须被分组,即经过group by --求出employees表中(某个几个)部门的平均工资 select department_id,avg(salary) from employees where department_id in (40,60,80,100) group by department_id --不同部门不同工种的平均工资 select department_id,job_id,avg(salary) from employees group by department_id,job_id --不能在where中使用组函数,只能在having中使用 select department_id,avg(salary) from employees having avg(salary)>6000 group by department_id --示例 select avg(nvl(c,0)) from zzznew where nvl(c,0)!=-1 having avg(nvl(c,0))>=0 group by key order by key --显示各个部门平均值的最大值(由此可以看出,组函数可以嵌套) select max(avg(salary)) from employees group by department_id
---子查询 --单行子查询使用= < > >= <= <> --多行子查询使用 in any all --查询最低工资比50号部门高的各个部门的最低工资 select min(salary),department_id from employees where min(salary)>( select salary from employees where department_id=50 ) group by department_id --返回其他部门中比job_id为'IT_PROG'部门一意工资低的员工的员工号、姓名、job_id以及salary --若为所有改为all即可 select employee_id,last_name,job_id,salary from employees where job_id<>'IT_PROG' and salary< any( select salary from employees where job_id='IT_PROG' ) --子查询时,可以使用外边的表进入子查询内部 --查询工资在该部门的平均工资上的员工信息 select employee_id from employee e1 where salary>( select avg(salary) from employee e2 where e1.department_id=e2.department_id group by department_id )

constraint就是约束的意思,我们使用这样起名字,这样以后在查看约束的时候就见名知意了,否则系统生成的一看根本不知道是什么意思
create table AAA2( id varchar2(100) default(sys_guid()) constraint AAA1_ID_NN not null , name varchar2(20) CONSTRAINT AAA1_NAME_NN not null , CONSTRAINT AAA1_ID_NAME_UNIQUE unique(ID,name)--这样写是同时针对两列,这两个都相同才不行 CONSTRAINT AAA1_NAME_UNIQUE unique(name) --这样写是针对name一列 )
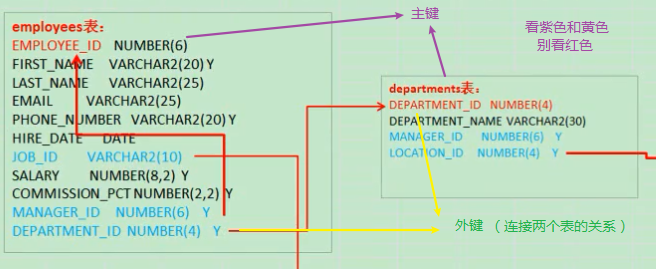
create table AAA2( id varchar2(100) , name varchar2(20) , department_id varchar2(100), CONSTRAINT AAA2_ID_NAME_PK primary key(id), --AAA是父 AAA2是子 --此时AAA2中department_id必须是AAA的id包含的,否则写不进去(因为无父项);删除AAA得时候也是看AAA2的department_id是否存在删除的id,若有则删不掉(因为有子项) constraint AAA2_department_fk foreign key(department_id) references AAA(id) )
上面引入外键的时候,父的外键一定要是主键或者有唯一约束
若父有多个主键,则外键也必须结合多个主键才能设置成功 如:constraint foreign_name foreign AAA2(courseid,studentid) references AAA(courseid,studentid)--这里假设courseid与studentid都为AAA的主键

on delete cascade或者on delete set null在声明完外键后面写,就是
constraint AAA2_department_fk foreign key(department_id) references AAA(id) on delete cascade 这样
设置级联删除时:父表删除本项,子表对应父表删除的关联项外键值全部删除
设置级置空时:父表删除本项,子表对应父表删除的关联项外键值清空,就是该行,对应的外键关联字段清空,其余保留
什么都不设置是:子表有,则父表是无法删除的。
not null只能加在行级
其余的可以加在表级
完整示例
create table AAA3( --列级约束 id varchar2(200) default sys_guid(), email varchar2(20), name varchar2(20) constraint AAA3_name_nn not null, department_id varchar2(10) constraint AAA3_department_id_nn not null, salary number(10,2) constraint AAA3_salary_check check(salary>1500 and salary<30000), --check 它和unique一样写了就检查,否则就为空 --表级约束 constraint AAA3_email_unique unique(email),--空值之间不判别唯一性,换言之,写了就判别唯一性,不写就是null constraint AAA3_PK primary key(id), --primary key constraint AAA3_DEPARTMENT_FK foreign key(department_id) references AAA(id) --on delete cascade/set null )
--视图
--创建视图 create view view1 as select * from zzznew --查询 select * from view1 --可以修改 update view1 set col1='wdddd' where key='3333' --创建只读视图 create view view2 as select * from zzznew with read only --无法更新,以下更新语句将报错 update view2 set col1='wdddd' where key='3333'
rownum伪列只能进行<或<= 若进行=和>或>=返回的结果将为空,那么我们如何操作取40~50之间的数据呢?我们在查询的时候使用伪列,将这个结果作为新表,同时将查询时的伪列作为具体列,那么他就可以使用>号了。
select rn,key from(--此时使用rn,就是内部的伪列,现在他就是我要查询新表的具体列了,若使用rownum,系统判别它是该表的伪列,因此在内部命名为rn select rownum rn,key from(select key from zzznew order by key) ) where rr>40 and rr<50

--序列
select row_version.nextval from dual
select row_version.currval from dual
序列就是自己定义递增,他不会随着rollcak回滚。
row_version我们使用的原理就是更新时设置行版本列nextval,同时where找行版本列=事务开始时查询的那个值,如果在提交的时候发现更新了0行,说明该行已经被更新,那么他需要抛出异常,使得整个事务回滚!
当然可以定义主键数字递增
如 create table AAA(id number default mysequence1.nextval)--这样完成默认的主键递增
--索引(为了加速查询,oracle自己调用)
设置主键或唯一约束的时候,默认生成索引
如果自己按照某列查询的比较多,也可以自己定义该列的索引,以加速查询
索引不是随便创建的,若随意创建 可能不仅不提高效率反而拖慢速度,那么何时创建索引才能提高效率呢?



--高级子查询

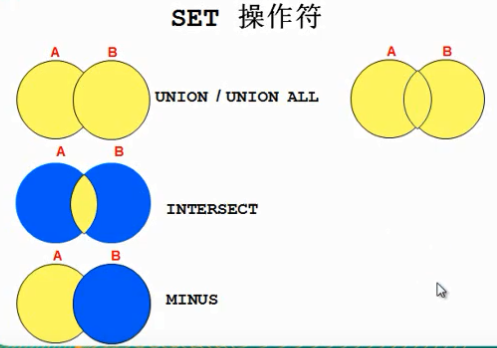
select id from aaa union select id from aaa2 order by 1 desc --1代表查询出来的第一列 select AAA.id from AAA join (select id from AAA2) a2 on AAA.id=a2.id select id from AAA INTERSECT select id from AAA2 --找共同的 select id from AAA MINUS select id from AAA2 --去除AAA中,AAA2中包含的 --联合两个表 select id,column1,to_date(null) zzznew_createdate from aaa union select key id,to_char(null),createdate from zzznew --高级子查询内容 --多列子查询 select * from zzznew where (key,col1)=(select key,col1 from zzznew where rownum<2)
select * from zzznew where (key,col1) in (select key,col1 from zzznew where rownum<2)
--返回比本部门平均工资高的员工的last_name,department_id,salary以及平均工资 --方法一(在from语句中使用子查询) select last_name,department_id,salary,e2.avg(salary) from employees e1,(select department_id,avg(salary) from employees e2 group by department_id) e2 where e1.department_id=e2.department_id and e1.salary>e2.avg(salary) --方法二(相关子查询) select last_name,department_id,salary,(select avg(salary) from employees group by department_id) avg_salary from employees e1 where salary>( select avg(salary) from employees e2 where e1.department_id=e2.department_id group by department_id ) --查询公司管理者的信息(exists) select * from employees e1 where exists ( select 'A' from employees e2 where e1.employee_id=e2.manage_id ) --相关更新 update zzznew set col1=( select key from AAA where id=zzznew.key ) select * from zzznew rollback --相关删除 delete zzznew where col1=( select key from AAA where id=zzznew.key ) delete zzznew where key in(select id from aaa)

以下代码使用with相当重要哦。
--查询公司各部门的总工资大于公司按部门的工资的平均值的部门信息 with dept_costs as --每个部门的工资总额 (select depatertment_name ,sum(salary) dept_total from employees e,departments d where e.department_id=d.department_id group by depatertment_name ), avg_cost as--公司按部门的平均工资 (select sum(dept_total)/count(*) dept_avg from dept_costs ) select * from dept_costs where dept_total>(select dept_avg from avg_cost) order by depatertment_name
select id from aaa union select id from aaa2 order by 1 desc --1代表查询出来的第一列 select AAA.id from AAA join (select id from AAA2) a2 on AAA.id=a2.id select id from AAA INTERSECT select id from AAA2 --找共同的 select id from AAA MINUS select id from AAA2 --去除AAA中,AAA2中包含的 --联合两个表 select id,column1,to_date(null) zzznew_createdate from aaa union select key id,to_char(null),createdate from zzznew --高级子查询内容 --多列子查询 select * from zzznew where (key,col1)=(select key,col1 from zzznew where rownum<2) --返回比本部门平均工资高的员工的last_name,department_id,salary以及平均工资 --方法一(在from语句中使用子查询) select last_name,department_id,salary,e2.avg(salary) from employees e1,(select department_id,avg(salary) from employees e2 group by department_id) e2 where e1.department_id=e2.department_id and e1.salary>e2.avg(salary) --方法二(相关子查询) select last_name,department_id,salary,(select avg(salary) from employees group by department_id) avg_salary from employees e1 where salary>( select avg(salary) from employees e2 where e1.department_id=e2.department_id group by department_id ) --查询公司管理者的信息(exists) select * from employees e1 where exists ( select 'A' from employees e2 where e1.employee_id=e2.manage_id ) --相关更新 update zzznew set col1=( select key from AAA where id=zzznew.key ) select * from zzznew rollback --相关删除 delete zzznew where col1=( select key from AAA where id=zzznew.key ) delete zzznew where key in(select id from aaa) --with(with my_name as ()... select... 是一体的,不是单独写,这个很有用啊) with cxjj as (select min(key) from zzznew ) select * from zzznew where key=(select key from cxjj) --查询公司各部门的总工资大于公司按部门的工资的平均值的部门信息 with dept_costs as --每个部门的工资总额 (select depatertment_name ,sum(salary) dept_total from employees e,departments d where e.department_id=d.department_id group by depatertment_name ), avg_cost as--公司按部门的平均工资 (select sum(dept_total)/count(*) dept_avg from dept_costs ) select * from dept_costs where dept_total>(select dept_avg from avg_cost) order by depatertment_name with a as (select * from zzznew) , b as (select * from zzznew) select count(*) from (select * from a union select * from b) select * from zzznew minus select * from zzznew create table zzznew1 as select * from zzznew where 1=2 insert into zzznew1 select * from zzznew where key=1 select * from zzznew1 update zzznew1 set c=2 where key='001' select * from zzznew minus select * from zzznew1--由此可见minus去的是我查的列全部相同,若为*则代表全部列都相同会被去掉,否则保留 --我发现,到现在为止用到组函数都是,查询出来表的列才可以用,如果我直接sum(select ..)这样是不行的 --但是里面可以嵌套组函数如count(decode(to_char(hire_date,'yyyy'),'1995',1, null)) "1995" --count(case to_char(hire_date,'yyyy') when '1998' then 1 else null end) "1998" --count(distinct(col1)) --嵌套函数 --总之最内层一定是from表中的列 select sysdate,next_day(sysdate,7) from dual --7代表接下来的星期六 因为oracle索引从1开始,1为星期天 --with很重要,例子就是上面那个,谨记 --外键防止死锁加索引,是在加外键的那个字段加索引! --外键不加索引,多事务,无论是否设置外键为级联还是置空都会发生等待,就是等待除了本事务的该表的会话提交才执行。 select rn,key from (select rownum rn,key from (select * from zzznew order by key)) where rn<10 and rn>5