mysql去除重复数据
今天一个同学问我mysql去除重复数据,自己做了个测试顺便记录下:
查看表结构:

mysql> desc testdelete; +-------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+-------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | one | varchar(40) | YES | | NULL | | | two | varchar(40) | YES | | NULL | | | three | varchar(40) | YES | | NULL | | +-------+-------------+------+-----+---------+----------------+ 4 rows in set (0.10 sec)
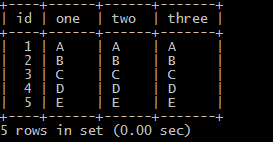
表的数据:
mysql> select * from testdelete; +----+------+------+-------+ | id | one | two | three | +----+------+------+-------+ | 1 | A | A | A | | 2 | B | B | B | | 3 | C | C | C | | 4 | D | D | D | | 5 | E | E | E | | 6 | A | A | B | | 12 | A | A | A | | 13 | A | A | A | | 14 | A | A | A | | 15 | A | A | A | +----+------+------+-------+ 10 rows in set (0.00 sec)
接下来进行测试:
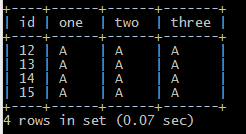
1.根据one列查询重复的数据(根据单列判断重复)
SELECT * FROM testdelete WHERE ONE IN (SELECT ONE FROM testdelete GROUP BY ONE HAVING COUNT(ONE) > 1)
结果:
2.删除表中的重复记录:(根据单列删除且保留ID最小的一条)
DELETE
FROM testdelete
WHERE ONE IN(SELECT
ONE
FROM testdelete
GROUP BY ONE
HAVING COUNT(ONE) > 1)
AND id NOT IN(SELECT
MIN(id)
FROM testdelete
GROUP BY ONE
HAVING COUNT(ONE) > 1)
报错:

原因:大概是因为不能直接在查询的语句中进行操作。
解决办法:将查询包装一层:
DELETE
FROM testdelete
WHERE ONE IN(SELECT
ONE
FROM (SELECT
ONE
FROM testdelete
GROUP BY ONE
HAVING COUNT(ONE) > 1) a)
AND id NOT IN(SELECT
*
FROM (SELECT
MIN(id)
FROM testdelete
GROUP BY ONE
HAVING COUNT(ONE) > 1) b)
结果:
(5 row(s) affected)
Execution Time : 00:00:00:094
Transfer Time : 00:00:00:000
Total Time : 00:00:00:094
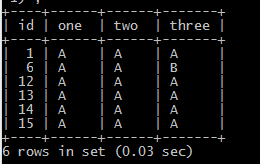
再次查看数据:

将数据还原。
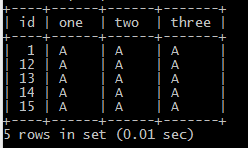
3.根据one,two,three判断重复:(根据单多判断重复)
SELECT * FROM testdelete a WHERE (a.one,a.two,a.three) IN (SELECT ONE,two,three FROM testdelete GROUP BY ONE,two,three HAVING COUNT(*) > 1)
结果;
4.删除表中的重复数据(根据多列进行删除且保留ID最小的一条)
DELETE
FROM testdelete
WHERE (ONE,two,three)IN(SELECT
ONE,
two,
three
FROM (SELECT
ONE,
two,
three
FROM testdelete
GROUP BY ONE,two,three
HAVING COUNT( * ) > 1) a)
AND id NOT IN(SELECT
MIN(id)
FROM (SELECT
MIN(id) AS id
FROM testdelete
GROUP BY ONE,two,three
HAVING COUNT( * ) > 1) b)
结果:
(4 row(s) affected)
Execution Time : 00:00:00:125
Transfer Time : 00:00:00:000
Total Time : 00:00:00:125
查看数据:
数据还原
5. 查找表中多余的重复记录(多个字段),不包含id最小的记录 (根据多个字段查重复不包含id最小的)
SELECT *
FROM testdelete a
WHERE (a.one,a.two,a.three)IN(SELECT
ONE,
two,
three
FROM testdelete
GROUP BY ONE,two,three
HAVING COUNT( * ) > 1)
AND id NOT IN(SELECT
MIN(id) AS id
FROM testdelete
GROUP BY ONE,two,three
HAVING COUNT( * ) > 1)
结果: