最近突然有了时间,想研究一下 p2p 网络,先做一个较容易实现的 bt 下载实现,尽量少的使用第3方库。
先写第一篇 种子的解析:
种子文件,不是全是 asc2 可见字符,有些是二进制编码,不能直接看所以需要解析。
Bencode 编码
https://zh.wikipedia.org/wiki/Bencode
Bencode(发音为Bee-Encode)是BitTorrent用在传输数据结构的编码方式。这种编码方式支持四种资料类型:
字符串
整数
串列
字典表
Bencode最常被用在.torrent档中,文件里的元数据都是Bencode过的字典表。其也被用在tracker返回响应时使用。
虽然比用纯二进制编码效率低,但由于结构简单而且不受字节存储顺序影响(所有数字以十进制编码)——这对于跨平台性非常重要。而且具有较好的灵活性,即使存在故障的字典键,只要将其忽略并更换新的就能兼容补充。
编码方法
Bencode使用ASCII字符进行编码。
一个整型数会以十进制数编码并括在i和e之间,不允许前导零(但0依然为整数0),负数如十进制表示一样使用前导负号,不允许负零。如整型数“42”编码为“i42e”,数字“0”编码为“i0e”,“-42”编码为“i-42e”。
一个以字节为单位表示的字符串(字符串的字为一个字节,不一定是一个字符)会以(长度):(内容)编码,长度的值和数字编码方法一样,只是不允许负数;内容就是字符串的内容,如字符串“spam”就会编码为“4:spam”,本规则不能处理ASCII以外的字符串,为了解决这个问题,一些BitTorrent程序会以非标准的方式将ASCII以外的字符以UTF-8编码转化后再编码。
线性表会以l和e括住来编码,其中的内容为Bencode四种编码格式所组成的编码字符串,如包含和字符串“spam”数字“42”的线性表会被编码为“l4:spami42ee”,注意分隔符要对应配对。
字典表会以d和e括住来编码,字典元素的键和值必须紧跟在一起,而且所有键为字符串类型并按字典顺序排好。如键为“bar”值为字符串“spam”和键为“foo”值为整数“42”的字典表会被编码为“d3:bar4:spam3:fooi42ee”。
对于线性表和字典的取值范围并没有限制,他们通常会包含其他元素,这样就允许对很复杂的数据结构进行编码。
多文件Torrent的结构的树形图为:
Multi-file Torrent
├─announce:Tracker的主服务器
├─announce-list:Tracker服务器列表
├─comment:种子文件的注释
├─comment.utf-8:种子文件注释的utf-8编码
├─creation date:种子文件建立的时间,是从1970年1月1日00:00:00到现在的秒数。
├─encoding:种子文件的默认编码,比如GB2312,Big5,utf-8等
├─info:所有关于下载的文件的信息
│ ├─files:表示文件的名字
│ │ ├─length:文件的大小(Byte)
│ │ ├─path:文件的名字,在下载时不可更改
│ │ └─path.utf-8:文件名的UTF-8编码,同上
│ ├─name:推荐的文件夹名,此项可于下载时更改
│ ├─name.utf-8:推荐的文件夹名的utf-8编码,同上
│ ├─piece length:每个文件块的大小(Byte)
│ ├─pieces:文件的特征信息(将所有文件按照piece length的字节大小分成块,每块计算一个SHA1值,然后将这些值连接起来所组成)
│ ├─publisher:文件发布者的名字
│ ├─publisher-url:文件发布者的网址
│ ├─publisher-url.utf-8:文件发布者网址的utf-8编码
│ └─publisher.utf-8:文件发布者的名字的utf-8编码
└─nodes:这个字段包含一系列ip和相应端口的列表,是用于连接DHT初始node
单文件Torrent的结构的树形图为:
(各个字段含义同多文件Torrent一样,只是单文件Torrent没有files字段)
Single-File Torrent
├─announce:Tracker的主服务器
├─announce-list:Tracker服务器列表
├─comment:种子文件的注释
├─comment.utf-8:种子文件注释的utf-8编码
├─creation date:种子文件建立的时间,是从1970年1月1日00:00:00到现在的秒数。
├─encoding:种子文件的默认编码,比如GB2312,Big5,utf-8等
├─info:所有关于下载的文件的信息
│ ├─length:文件的大小(Byte)
│ ├─name:推荐的文件夹名,此项可于下载时更改
│ ├─name.utf-8:推荐的文件夹名的utf-8编码,同上
│ ├─piece length:每个文件块的大小(Byte)
│ ├─pieces:文件的特征信息(将所有文件按照piece length的字节大小分成块,每块计算一个SHA1值,然后将这些值连接起来所组成)
│ ├─publisher:文件发布者的名字
│ ├─publisher-url:文件发布者的网址
│ ├─publisher-url.utf-8:文件发布者网址的utf-8编码
│ └─publisher.utf-8:文件发布者的名字的utf-8编码
└─nodes:这个字段包含一系列ip和相应端口的列表,是用于连接DHT初始node
比较关键的数据:
Tracker服务器列表 文件名 文件大小 文件块sha1值 都可以直接解析出来
特征码:SHA1 虽然是20字节 但是显示的时候,是按16进制显示就变成了40个字符
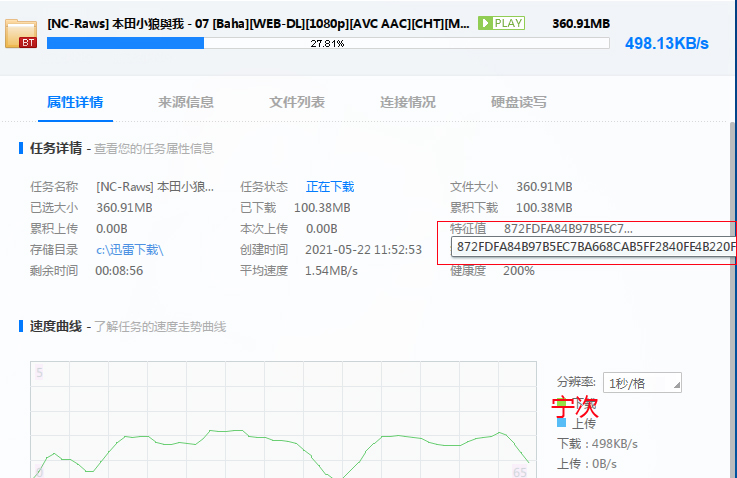
特征值 :872FDFA84B97B5EC7BA668CAB5FF2840FE4B220F
下面看 Wireshark 抓包的特征值
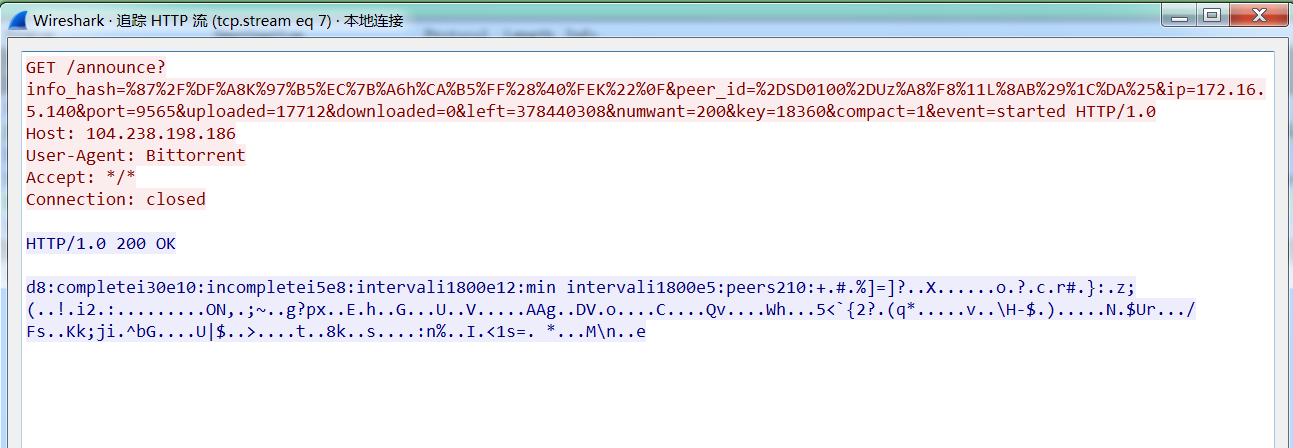
是原始20字节的二进制,经过 urlencode 编码后:%87%2F%DF%A8K%97%B5%EC%7B%A6h%CA%B5%FF%28%40%FEK%22%0F
下面试着 url 解码看看,结果是乱码。

关键的问题 info_hash 怎么计算出来?
通过上面的介绍,应该明白了,先计算出来 info 字典的 SHA1 的值,然后在进行 urlencode 编码就能得到这个值,所以要用到2个库 openssl 中含加密库 curl 中含 url 功能。
其实,我很轻松的就解码出来了仅有一个文件的 bt 种子: [NC-Raws] 本田小狼與我 _ Super Cub - 07 [Baha][WEB-DL][1080p][AVC AAC][CHT][MP4].torrent
但是又找了另外2个种子,含多个文件的种子,也含有 DTH 网络的信息的种子解析失败,原因后面会说。
DTH 网络信息,放到种子文件的 nodes 里面,重点来了。
专业的事必须使用专业的工具
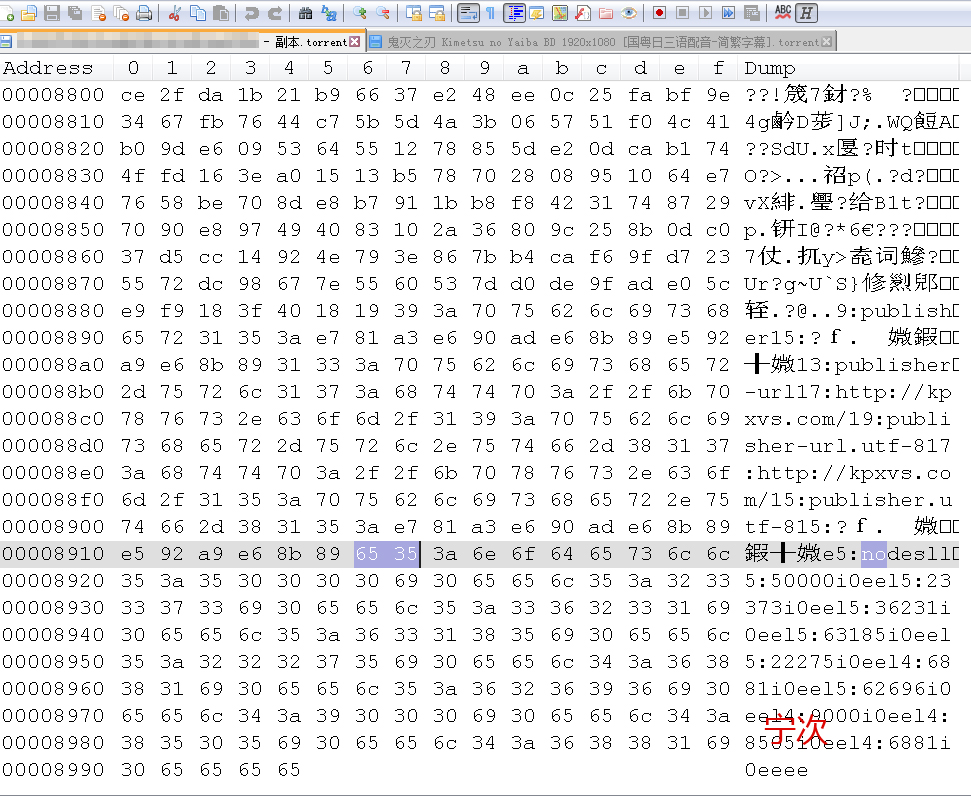
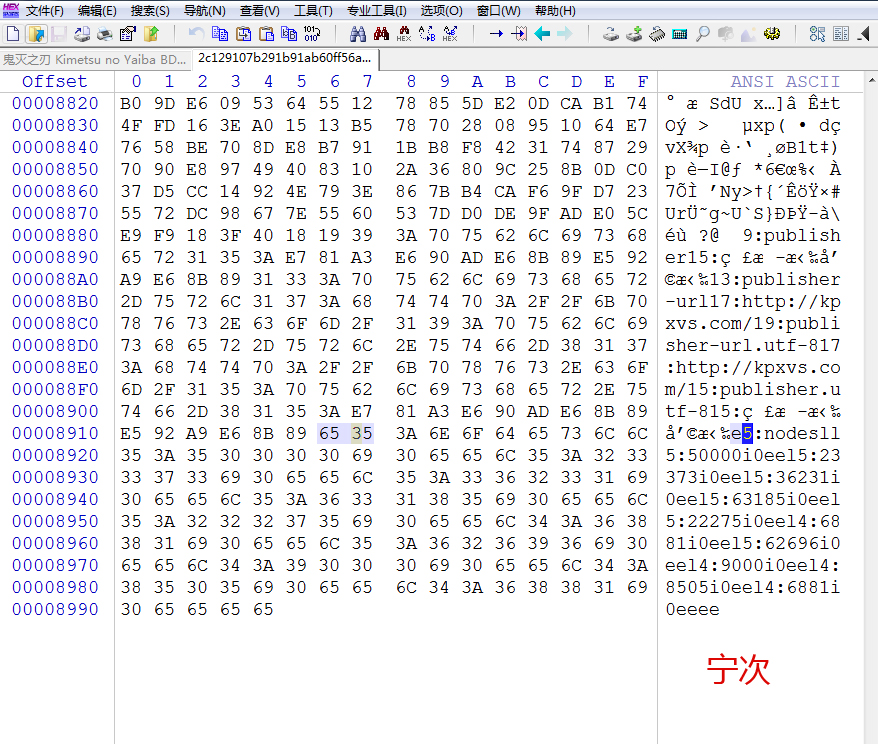
SHA1 的计算方式,就是从 info 开始,到 nodes 这里,含 0x65 0x35 对应字符 e5 结束的 SHA1 的值,在转 url 编码就对了。
找了好几个种子每次看位置都不一样,感觉很奇怪,原来是因为 notepad++ hex 这个插件 十六进制和 显示的 asc2 字符根本对不上,后来换了专业的 winhex 终于确定了是这个位置。
代码已开源到 github 可以到置顶的贴里面去找。
解析文件列表并计算大小:
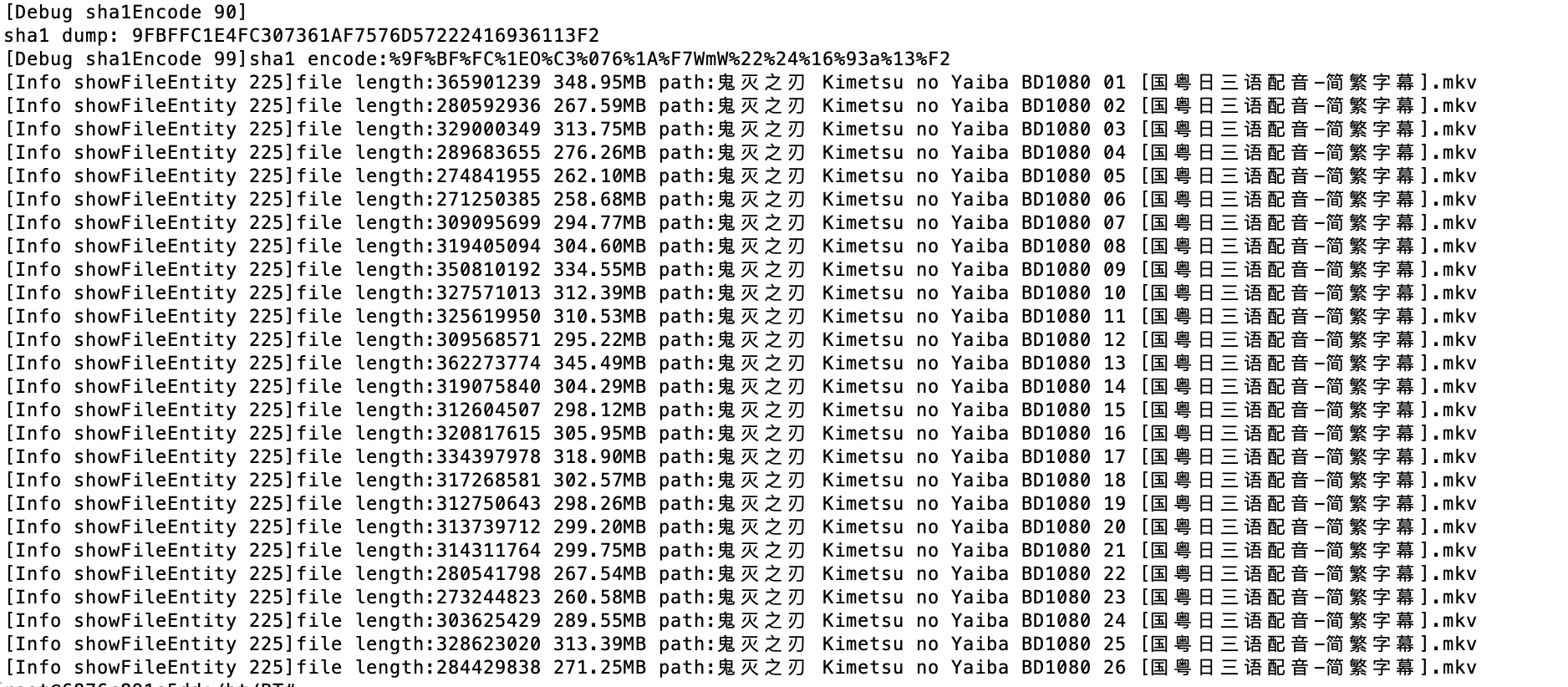
讯雷显示:
1 void Bencode::showFileEntity() 2 { 3 int file_length = 0; 4 std::string file_path = ""; 5 6 for ( auto &file : file_entity_list ) 7 { 8 file_length = file.getLength(); 9 file_path = file.getPath(); 10 11 //filter _____padding_file_0_如果您看到此文件,请升级到BitComet(比特彗星)0.85或以上版本____ 12 13 if ( file_path.find("_____padding_file_" ) ) 14 { 15 LOG_INFO("file length:%d %d.%dMB path:%s", file_length, file_length/1024/1024, 16 (file_length - (file_length/1024/1024 * 1024 * 1024))*1000/1024/1024/10, 17 file_path.c_str()); 18 } 19 } 20 }