tags: 数据结构
插入排序、选择排序、希尔排序、快速排序、堆排序、归并排序、基数排序。
主要内容
10.1 概述
10.2 插入排序
10.2.1 直接插入排序
10.2.2 折半插入排序
10.4.1 简单选择排序
10.4.3 堆排序
10.5 归并排序
10.6 基数排序
10.7 各种排序方法的比较讨论
概述
排序定义
将一个数据元素(或记录)的任意序列,重新排列成一个按关键字有序的序列叫~
排序分类
-
按待排序记录所在位置 内部排序:待排序记录存放在内存 外部排序:排序过程中需对外存进行访问的排序
-
按排序依据原则 插入排序:直接插入排序、折半插入排序、希尔排序 交换排序:冒泡排序、快速排序 选择排序:简单选择排序、堆排序 归并排序:2-路归并排序 基数排序
-
按排序所需工作量 简单的排序方法:T(n)=O(n²) 先进的排序方法:T(n)=O(logn) 基数排序:T(n)=O(d.n)
-
排序基本操作 比较两个关键字大小 将记录从一个位置移动到另一个位置
-
稳定排序与不稳定排序 关键码相同的数据对象在排序过程中是否保持前后次序不变。如 2, 2,1,排序后若为1, 2, 2 则该排序方法是不稳定的。
插入排序
直接插入排序
整个排序过程为n-1趟插入,即先将序列中第1个记录看成是一个有序子序列,然后从第2个记录开始,逐个进行插入,直至整个序列有序。
算法实现
Void InsertSort(SqList & L){
for (i= 2; i< L.Length; ++i )
if LT(L.r[i].key,L.r[i-1].key){
//需将L.r[i] 插入有序表)
L.r[0]= L.r[i]; //设置监视哨
L.r[i]= L.r[i-1];
for (j=i-2;LT(L.r[0].key,L.r[j].key);--j)
L.r[j+1]=L.r[j] ;//记录向后移动
L.r[j+1]= L.r[0];//将L.r[i]插入正确位置
}
} InsertSort
算法评价
时间复杂度:T(n)=O(n^2^) 空间复杂度:S(n)=O(1) 直接插入排序是一种稳定的排序方法。因为关键码相同的两个对象,在整个排序过程中,不会通过比较而相互交换。
折半插入排序
用折半查找方法确定插入位置的排序叫折半插入排序。
算法实现
Void BInsertSort(SqList & L) {
for (i=2; i<= L.length;++i){
L.r[0]=L.r[i]; (将L. r [i]暂存到L. r [0])
low=1;
high=i–1;
while(low<= high) { (在子表中查找插入位置)
m=(low+high)/2;
if LT(L.r[0].key,L.r[m].key)
high=m-1;(插入点在低半区)
else low=m+1; (插入点在高半区)
} //while
for(j=i-1;j>=high+1;--j)
L.r[j+1] = L.r[j] ;(记录后移)
L.r[high+1] = L.r[0]; (插入记录)
} //for
}
算法评价
时间复杂度:T(n)=O(n²) 空间复杂度:S(n)=O(1) 折半插入排序是一种稳定的排序方法。
希尔排序(缩小增量法)
它属于插入排序类的方法。
基本思想
先将整个待排序的记录分割成若干子序列分别进行直接插入排序,待整个序列中的记录”基本有序“时,再对全体记录进行一次直接插入排序。
排序过程 先取一个正整数d1<n,把所有相隔d1的记录放一组,组内进行直接插入排序;然后取d2<d1,重复上述分组和排序操作;直至di=1,即所有记录放进一个组中排序为止。
算法实现
Void ShellInsert(SqList &L,int dk){
//dk为跨度,r[0]是暂存单元,j<=0,插入位置已找到
for(i=dk+1;i<=L.length;++i)
if LT(L.r[i].key,L.r[i–dk].key){//L.r[i]为待排序记录
L.r[0]=L.r[i];//将L.r[i]暂存到L.r[0]
for(j=i–dk;j>0&<(L.r[0].key,L.r[j].key);j-=dk)
L.r[j+dk]=L.r[j];//将大于插入值的记录向后移动
L.r[j+dk]=L.r[0];//插入
}
}ShellInsert
void ShellSort(SqList &L,int dita[], int t){
//dita[0…t-1]存放跨度的数组
for(k=0;k<t;++k)
ShellInsert(L,dita[k]);//由dita[k]得到跨度
}ShellSort
希尔排序特点
-
子序列的构成不是简单的“逐段分割”, 而是将相隔某个增量的记录组成一个子序列
-
希尔排序可提高排序速度,因为
-
分组后n值减小,n²更小,而T(n)=O(n²),所以T(n)从总体上看是减小了
-
关键字较小的记录跳跃式前移,在进行最后一趟增量为1的插入排序时,序列已基本有序
-
增量序列取法
-
无除1以外的公因子
-
最后一个增量值必须为1
交换排序
冒泡排序
基本思想
将第一个记录的关键字与第二个记录的关键字进行比较,若为逆序r[1].key>r[2].key,则交换;然后比较第二个记录与第三个记录;依次类推,直至第n-1个记录和第n个记录比较为止——第一趟冒泡排序,结果关键字最大的记录被安置在最后一个记录上
对前n-1个记录进行第二趟冒泡排序,结果使关键字次大的记录被安置在第n-1个记录位置
重复上述过程,直到“在一趟排序过程中没有进行过交换记录的操作”为止
算法评价
时间复杂度:T(n)=O(n²) 空间复杂度:S(n)=O(1)
快速排序
基本思想
通过一趟排序,将待排序记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录进行排序,以达到整个序列有序。 排序过程 对r[s……t]中记录进行一趟快速排序,附设两个指针i和j,设枢轴记录rp=r[s],x=rp.key。
-
初始时令i=s,j=t
-
首先从j所指位置向前搜索第一个关键字小于x的记录,并和rp交换
-
再从i所指位置起向后搜索,找到第一个关键字大于x的记录,和rp交换
-
重复上述两步,直至i==j为止
-
再分别对两个子序列进行快速排序,直到每个子序列只含有一个记录为止
算法实现
Int Partition( SqList & L, int low, int high){
L.r[0]=L.r[low];
pivotkey=L.r[low].key;
while(low<high){
while(low<high&&L.r[high].key>=piotkey)
--high;
L.r[low]=L.r[high];
while (liw<high&&L.r[low].key<=pivotkey)
++low;
L.r[high]=L.r[low];
}
L.r[high]=L.r[0];
return low;
}
算法评价
时间复杂度 最好情况(每次总是选到中间值作枢轴)T(n)=O(nlogn) 最坏情况(每次总是选到最小或最大元素作枢轴)T(n)=O(n²) 空间复杂度 需栈空间以实现递归 最坏情况:S(n)=O(n) 一般情况:S(n)=O(logn)
选择排序
是每一趟在n-i+1(i= 1,2,3…n-1)个记录中选择关键字最小的记录作为有序序列中第i个记录。
简单选择排序
排序过程
首先通过n-1次关键字比较,从n个记录中找出关键字最小的记录,将它与第一个记录交换 再通过n-2次比较,从剩余的n-1个记录中找出关键字次小的记录,将它与第二个记录交换 重复上述操作,共进行n-1趟排序后,排序结束。
算法实现
void SelectSort(SqList&L )
for(i=1;i<L.length;++i) {
j =SelectMinkey(L,i);
if (i!=j)
L.r[i]↔L.r[j];
}
}
堆排序
堆的定义
n个元素的序列(k1,k2,……kn),当且仅当满足下列关系时,称之为堆 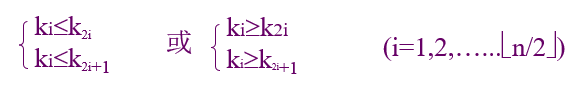
 可将堆序列看成完全二叉树,则堆顶元素(完全二叉树的根)必为序列中n个元素的最小值或最大值。
可将堆序列看成完全二叉树,则堆顶元素(完全二叉树的根)必为序列中n个元素的最小值或最大值。
堆排序基本思想
将无序序列建成一个堆,得到关键字最小(或最大)的记录;输出堆顶的最小(大)值后,使剩余的n-1个元素重又建成一个堆,则可得到n个元素的次小值;重复执行,得到一个有序序列,这个过程叫堆排序。 堆排序需解决的两个问题: 1.如何由一个无序序列建成一个堆?
方法:从无序序列的第floor(n/2)个元素(即此无序序列对应的完全二叉树的最后一个非终端结点)起,至第一个元素止,进行反复筛选
2.如何在输出堆顶元素之后,调整剩余元素,使之成为一个新的堆?
筛选 方法:输出堆顶元素之后,以堆中最后一个元素替代之;然后将根结点值与左、右子树的根结点值进行比较,并与其中小者进行交换;重复上述操作,直至叶子结点,将得到新的堆,称这个从堆顶至叶子的调整过程为“筛选”。
堆排序的算法
Type SqList HeapType;
Void HeapAdjust(HeapType & H, int s,int m) {
rc = H.r[s];
for (j=2*s;j<=m;j*=2){
if (j<m&<(H.r[j].key,H.r[j+1].key ))
++j;
if( !LT( rc.key, H.r[j].key))
break;
H.r[s]=H.r[j];
s=j;
}
H.r[s]=rc;
}
Void HeapSort(HeapType & H ){
for (i= H.length/2; i>0 ;--i)(从最下层的分支结点向上)
HeapAdjust (H,i,H.length);
for (i= H.length; i>1 ; --i ){
H.r[1] ↔ H.r[i] ;
HeapAdjust( H, 1, i-1);(从根结点向下)
}
}
算法评价
时间复杂度:最坏情况下T(n)=O(nlogn) 空间复杂度:S(n)=O(1)
归并排序
将两个或两个以上的有序表组合成一个新的有序表
2-路归并排序
排序过程
设初始序列含有n个记录,则可看成n个有序的子序列,每个子序列长度为1 两两合并,得到n/2个长度为2或1的有序子序列 再两两合并,……如此重复,直至得到一个长度为n的有序序列为止
算法实现
void Merge(RcdType SR[ ],RcdType &TR[ ],inti, int m, int n) {
for (j = m+1,k =i; i<= m && j<= n; ++ k){
(m为i的上限,m+1为j的下限)
if LQ(SR[i].key,SR[j].key) TR[K] = SR[i++];
else TR[k] = SR[j ++]
}
if (i<= m )TR[k…n] = SR[i…m];
if (j<= n )TR[k…n] = SR[j…n];
}
Void Msort (RcdType SR[ ],RcdType&TR1[ ],int s,int t) {
if (s = t) TR1[s] = SR[s];
else {
m = (s + t )/2; ( 将SR[s…t ]平分为 SR[s…m]和 SR[m+1…t ] )
Msort( SR,TR2,s,m); (递归地将SR[s…m] 归并为有序的TR 2[s…m]
Msort( SR,TR2, m+1,t ); (递归地将SR[m+1…t ]归并为有序的TR2[m+1…t] )
Merge(TR2,TR1,s,m,t); (将TR2[m+1..t] 和 TR2[M+1..T]归并到TR1[s..t] )
}
}
Void MergeSort( SQList & L){
Msort (L.r,L.r, 1, L.length);
}
算法评价
MergeSort调用 log2n 次,总的时间复杂度为O(n log2n) 空间开销为需要一个与原待排序对象数组同样大小的辅助数组。
迭代的归并排序是稳定的排序方法。
基数排序
多关键字排序方法
最高位优先法(MSD) 先对最高位关键字k1(如花色)排序,将序列分成若干子序列,每个子序列有相同的k1值;然后让每个子序列对次关键字k2(如面值)排序,又分成若干更小的子序列;依次重复,直至就每个子序列对最低位关键字kd排序;最后将所有子序列依次连接在一起成为一个有序序列
最低位优先法(LSD) 从最低位关键字kd起进行排序,然后再对高一位的关键字排序,……依次重复,直至对最高位关键字k1排序后,便成为一个有序序列