地址:http://pic.haibao.com/hotimage/
网页元素分析:
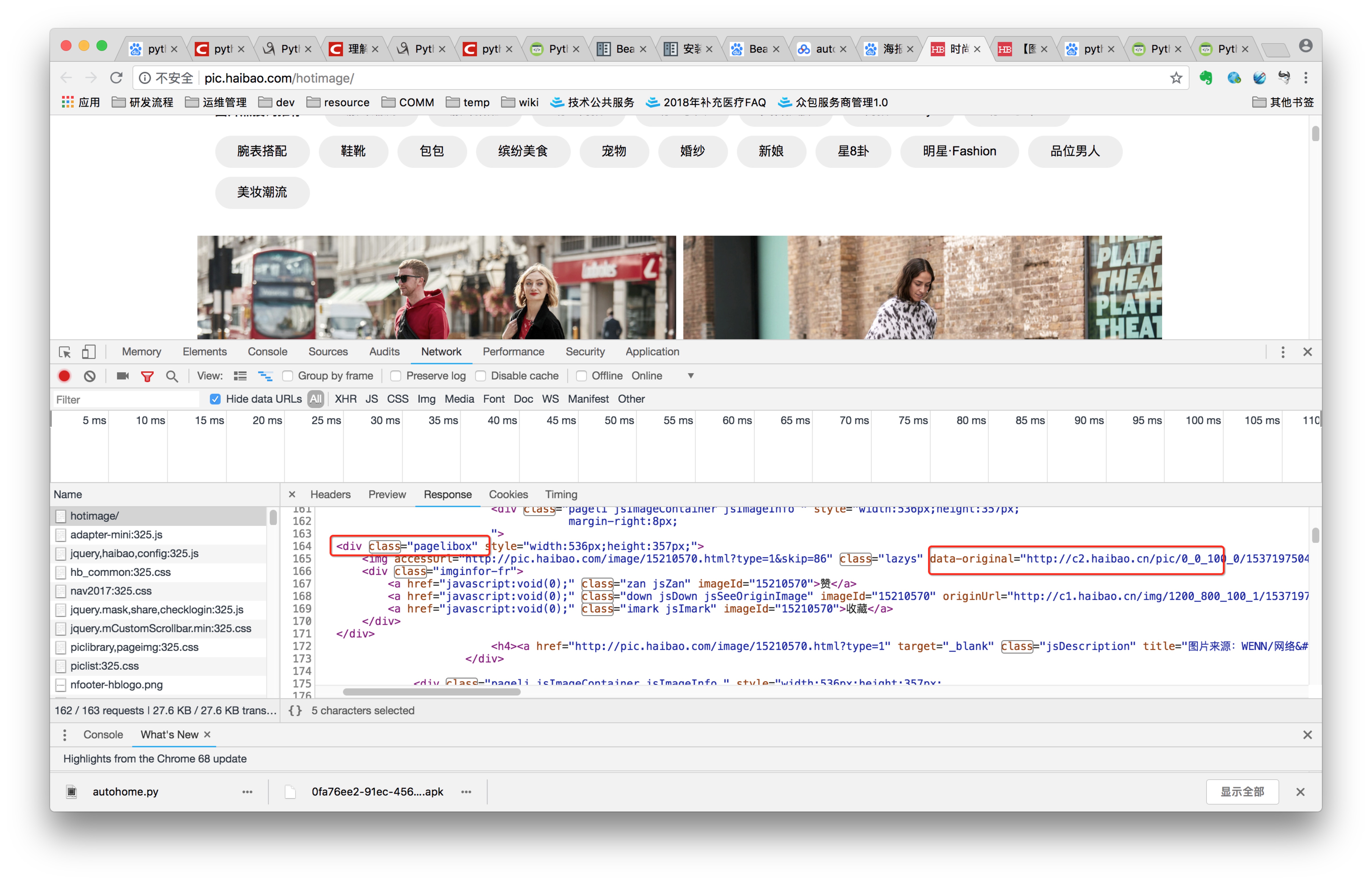
结果
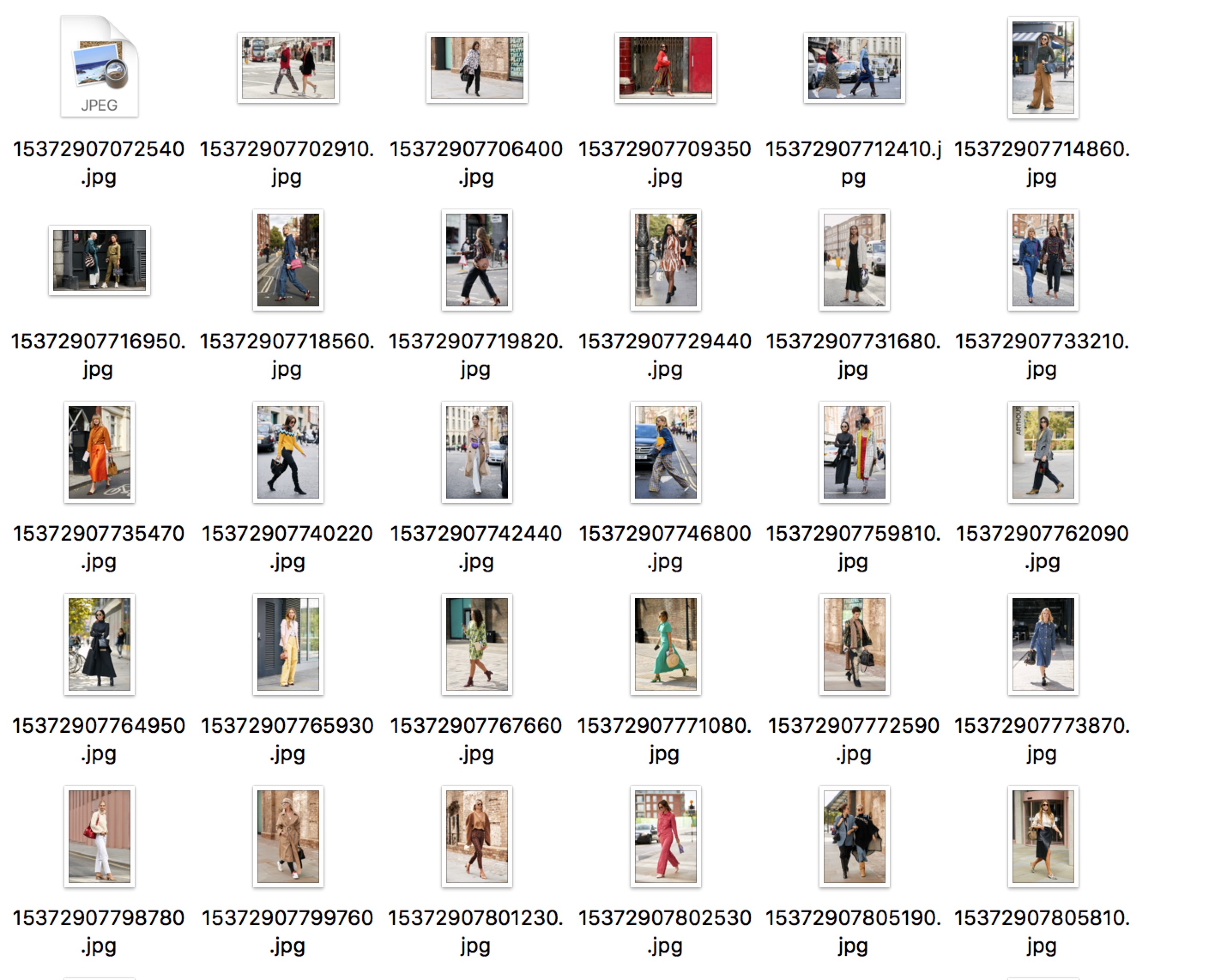
源码
import requests from bs4 import BeautifulSoup import os import time def getHotImgs(): topPage = requests.get("http://pic.haibao.com/hotimage/").content topPageParse = BeautifulSoup(topPage,"html5lib") allLiTags = topPageParse.find_all('div', class_="pagelibox") imgs = [] for liTag in allLiTags: imgTag = liTag.img imgSource = imgTag['data-original'] if imgSource : imgs.append(imgSource) return imgs def saveHotImgs(imgs): if not os.path.exists('haibaoHotImg'): os.mkdir('haibaoHotImg') i = 0 for img in imgs: image = requests.get(img).content timestamp = timeMillis() fileName = str(timestamp)+str(i) imgPar = img.rpartition('.') fileExt = imgPar[len(imgPar)-1] with file("haibaoHotImg"+'/'+fileName+'.'+fileExt,'w') as imgFile: imgFile.write(image) def timeMillis(): return int(round(time.time() * 1000)) if __name__ == "__main__": imgs = getHotImgs() saveHotImgs(imgs) print "finished"