ASCII
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
共有128个字符(十进制:0-127, 二进制:00000000-01111111)
在计算机中,所有的数据在存储和运算时都要使用二进制数表示(因为计算机用高电平和低电平分别表示1和0),例如,像a、b、c、d这样的52个字母(包括大写)、以及0、1等数字还有一些常用的符号(例如*、#、@等)在计算机中存储时也要使用二进制数来表示,而具体用哪些二进制数字表示哪个符号,当然每个人都可以约定自己的一套(这就叫编码),而大家如果要想互相通信而不造成混乱,那么大家就必须使用相同的编码规则,于是美国有关的标准化组织就出台了ASCII编码,统一规定了上述常用符号用哪些二进制数来表示。
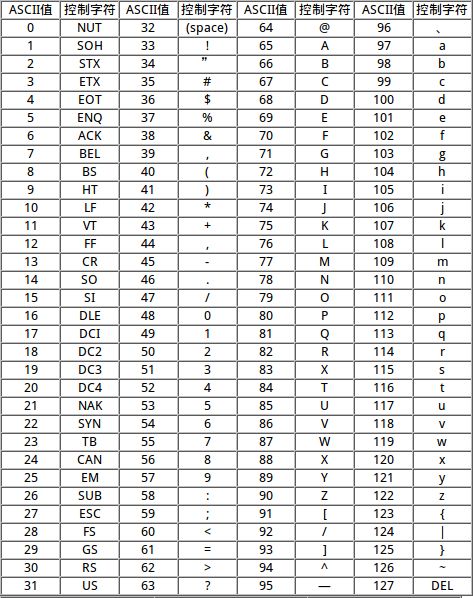
从128 到255这一页的字符集被称”扩展字符集“;
GB2312
GB2312 是对 ASCII 的中文扩展。
两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,我们还把数学符号、罗马希腊的字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的”全角”字符,而原来在127号以下的那些就叫”半角”字符了。
GBK
只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。结果扩展之后的编码方案被称为 GBK 标准,GBK包括了GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
GB18030
后来少数民族也要用电脑了,于是我们再扩展,又加了几千个新的少数民族的字,GBK扩成了 GB18030
Unicode
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
UTF-8
|
Unicode编码(十六进制)
|
UTF-8 字节流(二进制)
|
|
000000-00007F
|
0xxxxxxx
|
|
000080-0007FF
|
110xxxxx 10xxxxxx
|
|
000800-00FFFF
|
1110xxxx 10xxxxxx 10xxxxxx
|
| 010000-10FFFF | 11110xxx10xxxxxx10xxxxxx10xxxxxx |
UTF-8的特点是对不同范围的字符使用不同长度的编码。对于0x00-0x7F之间的字符,UTF-8编码与ASCII编码完全相同。UTF-8编码的最大长度是6个字节。从上表可以看出,6字节模板有31个x,即可以容纳31位二进制数字。Unicode的最大码位0x7FFFFFFF也只有31位。
Unicode和UTF-8的区别:
简单来说:
- Unicode 是「字符集」
- UTF-8 是「编码规则」
其中:
- 字符集:为每一个「字符」分配一个唯一的 ID(学名为码位 / 码点 / Code Point)
- 编码规则:将「码位」转换为字节序列的规则(编码/解码 可以理解为 加密/解密 的过程)