0403-Tensor内部存储结构
pytorch完整教程目录:https://www.cnblogs.com/nickchen121/p/14662511.html
一、Tensor内部存储结构
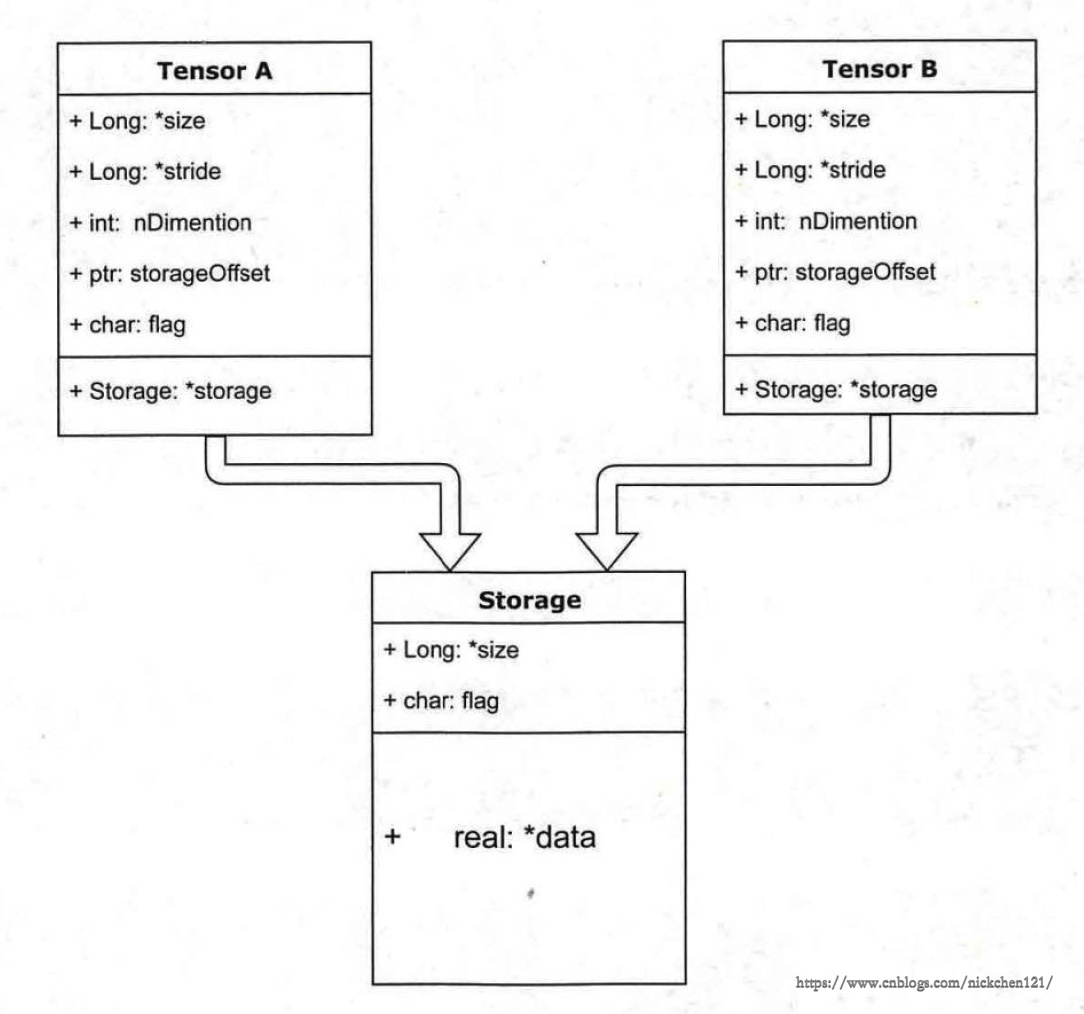
tensor的数据存储结构如上图所示,它分为信息区(Tensor)和存储区(Storage),信息区主要保存tensor的形状、数据类型等信息;而真正的数据则保存成连续数组存放在存储区。
一个tensor有着一个与之对应的storage,storage是在data之上封装的接口,便于使用。不同的tensor的头信息一般不同,但却有可能使用相同的storage。
a = t.Tensor([0, 1, 2, 3, 4, 5])
b = a.view(2, 3)
id(a.storage()), id(b.storage()), id(a.storage()) == id(b.storage())
(140397108640200, 140397108640200, True)
a[1] = 100 # a改变,b进而随之改变,因为它们共享内存
b
tensor([[ 0., 100., 2.],
[ 3., 4., 5.]])
c = a[2:]
# data_ptr返回tensor首元素的地址
c.data_ptr() - a.data_ptr() # 相差16,这是因为2*8=16相差两个元素,每个元素占8个字节
8
c[0] = -100 # c和a共享内存
a
tensor([ 0., 100., -100., 3., 4., 5.])
c.storage()
0.0
100.0
-100.0
3.0
4.0
5.0
[torch.FloatStorage of size 6]
d = t.Tensor(c.storage()) # 使用a的存储数据建立d
d[0] = 666
a
tensor([ 666., 100., -100., 3., 4., 5.])
id(a.storage()) == id(b.storage()) == id(c.storage()) == id(d.storage())
True
# storage_offset是数据在storage中的索引,a和d从sotrage的第一个元素开始找,c是从第三个元素开始查找
a.storage_offset(), c.storage_offset(), d.storage_offset()
(0, 2, 0)
e = b[::2, ::2] # 从0开始,每隔2行/列取一个元素
e
tensor([[ 666., -100.]])
b
tensor([[ 666., 100., -100.],
[ 3., 4., 5.]])
e.storage()
666.0
100.0
-100.0
3.0
4.0
5.0
[torch.FloatStorage of size 6]
# stride是storage中对应于tensor的相邻维度间第一个索引的跨度
# 对于b,第一行第一个元素到第二行第一个元素的索引差距为3,第一列第一个元素到到第二列第一个元素的索引差距为1
# 对于e,第一行第一个元素到第二行第一个元素(空)的索引差距为6,第一列第一个元素到到第二列第一个元素的索引差距为2
b.stride(), e.stride()
((3, 1), (6, 2))
e.is_contiguous()
False
id(d.storage()), id(e.storage())
(140397108641736, 140397108641736)
e.contiguous()
id(e.storage())
140397108699912
从上可见大多数操作并不会修改tensor的数据,只是修改tensor的头信息,这种做法减少了内存的占用,并且更加节省了时间。但是有时候这种操作会导致tensor不连续,此时可以通过contiguous方法让其连续,但是这种方法会复制数据到新的内存空间,不再和原来的数据共享内存。