Facebook是美国的一个社交网络服务网站,至今注册用户已超越20亿,月活用户更是惊人的突破3亿。
这样庞大的一个社交类网站,每日产生的社交数据当然也是非常可观,而这些社交数据,更接近口语,所以是比较好的一些英文语料数据。
然而,面对这样好的一个语料来源,它的下载难度也是超越了我的预期。
起初,因为使用facebook需要翻墙的原因,我们放弃了从app端解析数据的方式。
因为这种方式需要手机app端和电脑连接在同一个网络下,并且手机端需要设置代理为电脑ip。然而经过测试,这样设置以后手机端不能正常翻墙,这个问题有待进一步解决。
除了app端,这边便打算通过网页端直接去获取数据。
分析发现,通过https://www.facebook.com/profile.php?id=5这种形式的链接可以直接跳转到用户的主页,https://www.facebook.com/ChrisHughes
主页下面有以下信息
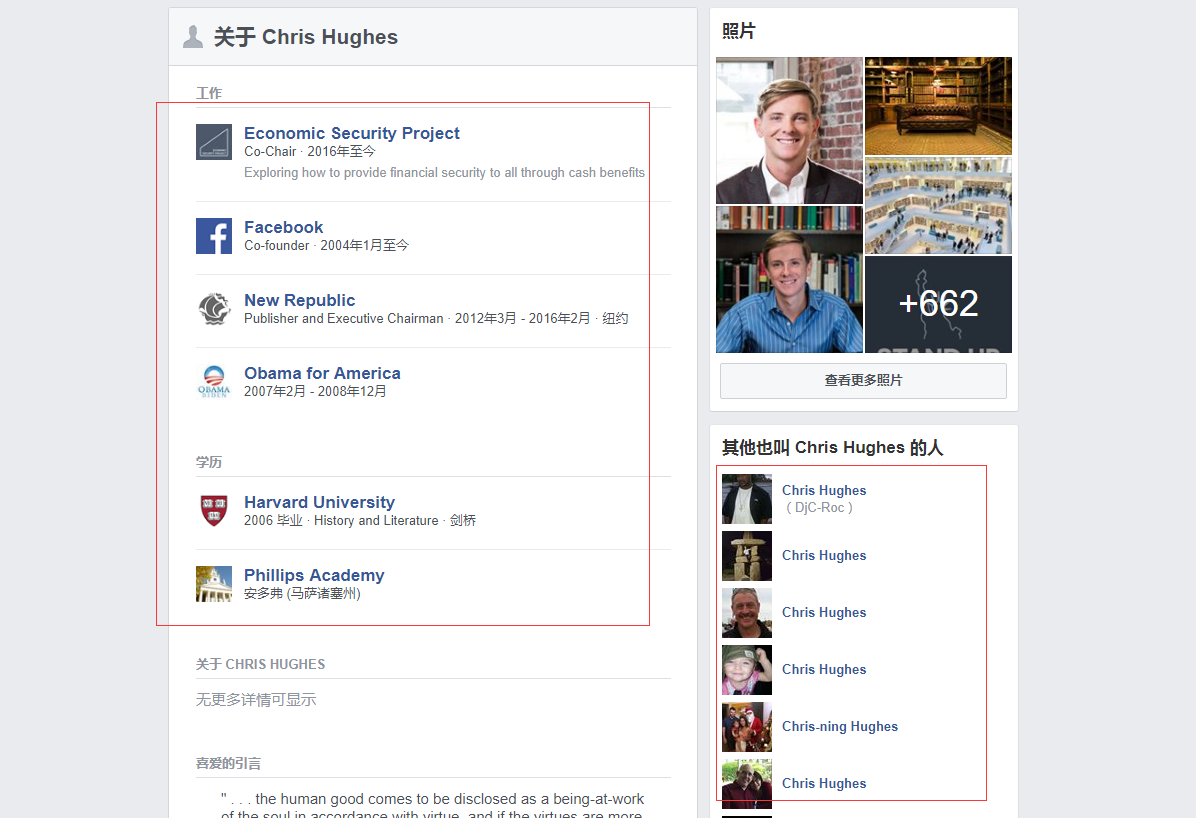
点击左边框内的链接,可以获得以下语料数据,右边框内则是该用户的一些关联用户。

这样一来,我们便有了第一个版本的下载策略。
通过遍历用户id的方式,访问到用户的主页下,然后根据用户的一些关联信息获取一些名人和营销帐号下的帖子信息以及该用户关联的用户信息。
这样一来,就能形成一个循环下载,循环中我们能够不断的扩充自己的facebook用户数据和帖子数据。
于是,通过这种方式,我们编写好了初步的下载程序,实际一下载,傻眼了。
facebook会封ip,就是出现验证码来需要输入,类似以下这样的:
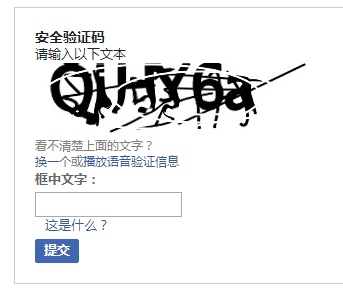
显然,这样的验证码,我们这边暂时还解决不了。
既然解决不了验证码,那只能选择放弃被封ip,启用新的ip方法。
这边估算是平均一个ip只能下载1Mb左右的语料数据,然后就会被封,这样一来,如果需要每天下载1g数据的话就需要1000多个ip。
虽然目前我们这边有代理ip库,但因为是免费的,所以稳定性和可用性都还是比较差的。
再加上Facebook需要翻墙的缘故,经过测试,实际可用的代理ip只有不到5个,显然,这样肯定行不通。
经过讨论,这边想通过使用付费代理的方式来提高ip的可用性,想着付费的ip应该会好很多把。
然后,经过两天的查找,得到的回答几乎是一样的,能够翻墙的ip是没有的。
好奇,自己这边使用的免费收集的代理都有能用的,收费的怎么会没有呢。
经过考虑,认为国外的ip应该是可以实现翻墙的,但是估计实际的翻墙可用率不太高。
于是这边购买了一些网站的代理ip来实际测试,发现果然如此,实际的可用率比我们这边的免费代理高的不多,也就维持在10个左右,但是稳定性确实比我们的高。
这样一来,每天的下载速度也就10Mb左右,这样肯定是不行的。
(备注:这里发现并不是贵的代理质量就比较好,测试发现http://www.66ip.cn/和http://www.daxiangdaili.com/这两家还是比较好用的,也比较便宜。当然这边测试的是能够用来翻墙的ip,可能具体使用时需要具体分析把)
通过网页直接获取数据的方式行不通,因此,这种方式只能选择放弃。
因此,现在只剩下最后一种方式,通过facebook官方提供的api来获取。
这种方式其实之前也尝试过,但是发现api需要一些用户信息,而且只能看关注的用户信息,所以当时就没有继续深究下去。
但是现在一想,比起其他的方式一天只能获取10MB左右的数据,api的方式肯定会多一点(因为实在是没什么别的办法了)。
花了一天时间,好好的看了一下facebook的api,https://developers.facebook.com/docs/graph-api/reference/
找到了一些可用的api接口:
https://graph.facebook.com/v2.9/{用户id}/feed?access_token={开发者access_token} 获取用户发的帖子,通过此接口得到语料数据
https://graph.facebook.com/v2.9/{用户id}/likes?access_token={开发者access_token} 获取用户感兴趣的人,通过此接口得到关联用户
https://graph.facebook.com/v2.9/{用户id}/comments?access_token={开发者access_token} 获取用户帖子的评论,通过此接口得到具体某一个帖子的评论,也就是语料数据
想到的下载策略是:先找一个用户,然后通过关联用户接口获取第一批用户,再通过用户id循环获取用户的帖子和关联的用户即可实现下载。
因此这里的重点就是开发者access_token,这个可以通过注册开发者来获取,因此这里就不在赘述了。
以上,就是此次facebook下载的一些总结和记录。