1. 背景
Hadoop支持Java以及C/C++开发,其中Hadoop Pipes(C++)支持MapReduce,而Hadoop libhdfs(C)支持HDFS的访问。但Python的解决方案仅能支持Hadoop部分功能,具体如下。
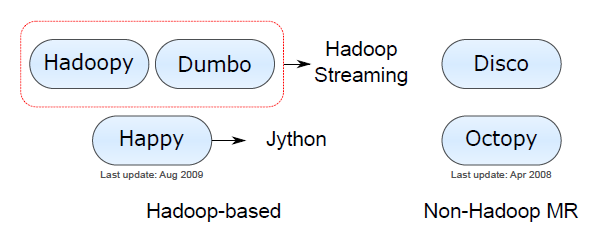
Hadoop Streaming:1. Awkward编程风格;2.仅能编写Mapper和Reducer脚本,不能编写RecordReader/Writer,Partitioner脚本;3. 不能访问HDFS;4. 仅能处理文本数据流;
Jython:1.支持不完整的标准库;2.大多数第三方包仅兼容CPython;3.不能使用C/C++扩展;
Hadoop-based类:局限性类似于Hadoop Streaming/Jython。
Non-Hadoop MR类:不成熟。
以上Python方案只支持hadoop部分功能,不能完全同时支持MapReduce/HDFS。因此CRS4提出了Pydoop 方案,用Python封装Hadoop Pipes和libhdfs,实现MapReduce和HDFS的访问。
2. Pydoop特性
Pydoop的特性如下:
支持访问多数MR组件(RecordReader/Writer/Partitioner);
获取configuration,设置counter和report status;
Like Java编程;
支持CPython,支持Python模块;
支持Hadoop HDFS API。
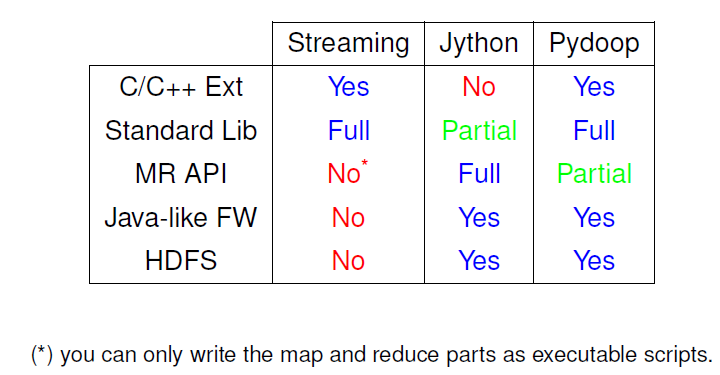
综上所述,归纳了Hadoop Streaming-Jython-Pydoop类的特性,如下图。
3. Pydoop架构
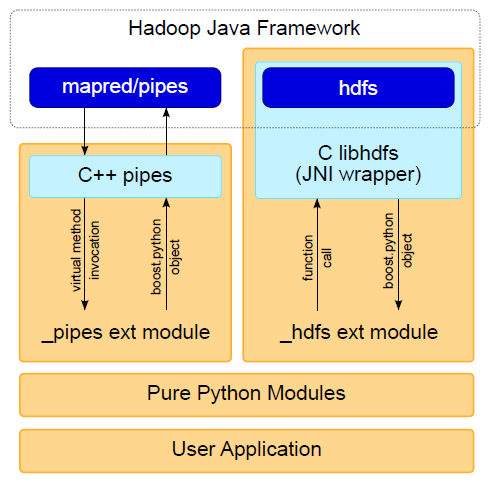
Pydoop架构如下图所示,包括整合Pipes和整合C libhdfs两部分。
整合Pipes:方法调用流从Hadoop Framework开始,通过C++ Pipes和Python API,最后到达用户自定义的方法;Boost封装结果后,返回至Hadoop Framework。
整合C libhdfs: 与Pipes相反,函数调用由Pydoop触发,通过C libhdfs,到达Hadoop framework; Boost封装结果后返回Pydoop端。
4. Pydoop模块包
Pydoop包括pydoop.hdfs、pydoop.pipes、pydoop.utils、pydoop.hadut等模块包,包的详细功能如下:
Hdfs:hdfs api模块,包括hdfs.path、hdfs.fs、 hdfs.file子包。主要有访问HDFS,读写文件,获取文件/目录/文件系统属性的信息功能。
Pipes:mapreduce模块包,用于编写Mapreduce程序,编写mapreduce组件(Mapper, Reducer, RecordReader/Writer, Partitioner,etc.)。
Utils: utility函数模块包。
Hadut:hadoop shell命令模块包。
参考资料