这一套环境搭完,你有可能碰到无数个意想不到的情况.
用了1周的时间,解决各种linux菜鸟级的问题,终于搭建好了。、
沿途的风景,甚是历练。
环境介绍:
系统:win7
内存:16G(最低4G,不然跑多个虚拟机会比较慢)
虚拟机:VMware Workstation 12 ,Linux安装的 CentOs 64位
一、准备工作:
1.安装 Vmware WorkStation 虚拟机
2.在虚拟机上安装 linux系统
hadoop一般运行在linux平台之上的,如果在windows安装hadoop集群,估计在安装过程中面对的各种问题会让人更加崩溃。
在虚拟机上安装的linux操作系统为CentOd 64位 完整版,当然 redhat, fedora等其它 版本完全没有问题。
3.卸载虚拟机自带的openJdk
批量卸载所有带有Java的文件 : rpm -qa | grep java | xargs rpm -e --nodeps
4.安装jdk,配置环境
安装成功后,用 echo $JAVA_HOME 检查JDK运行目录

上图为我的实例,我安装的是java 8,你要嗵安装的是其它版本的,但 !!! 请 记住这个地址,在配置hadoop时用得到。
5.克隆新的虚拟机
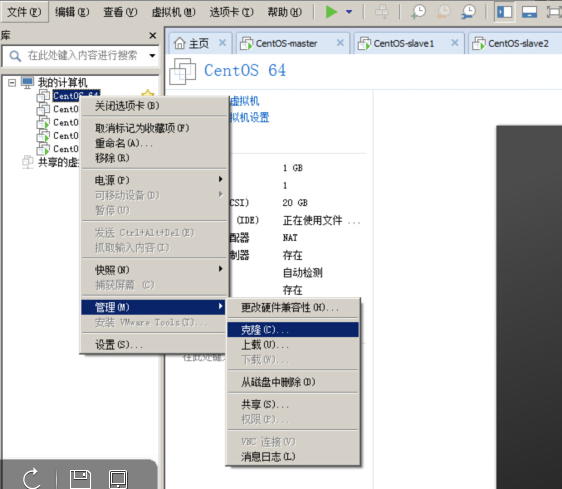
后面的步骤就用克隆出来的3个新的虚拟机(原装的就别动了,万一搞不好,想重新来过,可以再从原装的那个再克隆)
6.修改虚拟机主机名
分别将三台虚拟机的主机名修改为 master,node1,node2 !!!
首先: 切换到root账号
然后: vi /etc/sysconfig/network

第一台修改为: 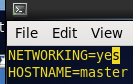
第二台修改为: HOSTNAME=node1
第三台修改为: HOSTNAME=node2



【全部用root 会不会权限太高了(新手最好这样,减少权限带来的悲剧)】
二、正式开始搭建 hadoop 集群
1.配置hosts文件
先检查 每台虚拟机的IP
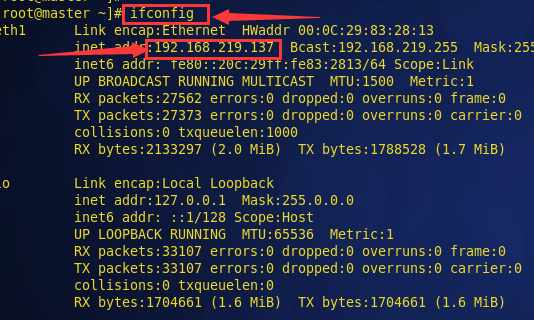
也可以通过ifconfig命令更改结点的物理IP地址,示例如下:

通过上面命令,可以将每个节点的IP地址修改,(也可以不用修改,直接用每个节点为的ip)再配置hosts文件
命令:vi /etc/hosts
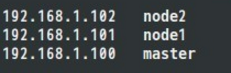
2.配置ssh免密码连接
by the way :
SSH主要通过RSA算法来产生公钥与私钥,在数据传输过程中对数据进行加密来保障数
据的安全性和可靠性,公钥部分是公共部分,网络上任一结点均可以访问,私钥主要用于对数据进行加密,以防他人盗取数据.
首先:每个节点分别 产生公、私密钥
键入命令: ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa

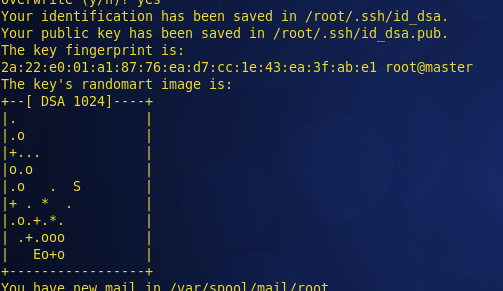
以上命令是产生公私密钥,产生目录在用户主目录下的.ssh目录中,如下命令查看生成的密钥文件:

出现 id_dsa.pub 、 id_dsa 说明生成密钥成功。
id_dsa.pub为公钥,id_dsa为私钥,紧接着将公钥文件复制成authorized_keys文件,这个步骤是必须的,过程如下:
命令:cat id_dsa.pub >> authorized_keys

用上述同样的方法在剩下的两个结点中如法炮制即可。
其次:集群结点ssh免密码
分别在node1、node2[重要!!!]节点上操作:


如上过程显示了node1结点通过scp命令远程登录master结点,并复制master的公钥文件到当前的目录下,
这一过程需要密码验证。接着,将master结点的公钥文件追加至authorized_keys文件中,通过这步操作,
如果不出问题,master结点就可以通过ssh远程免密码连接node1结点了。在master结点中操作如下:
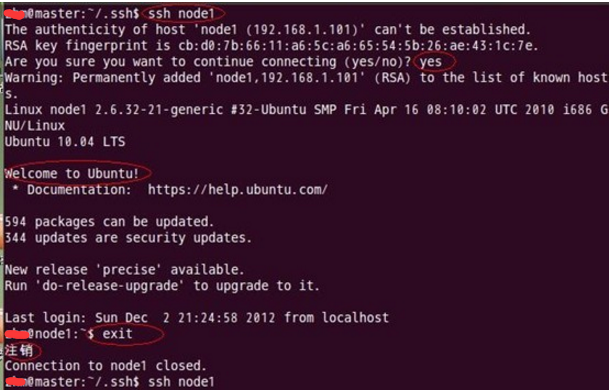
Master通过ssh免密码登录至node1、node2 结点测试:
第一次登录 (node1与node2相同)
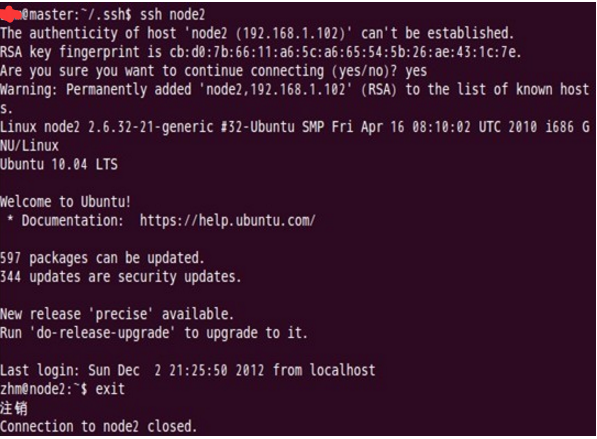
第二次登录
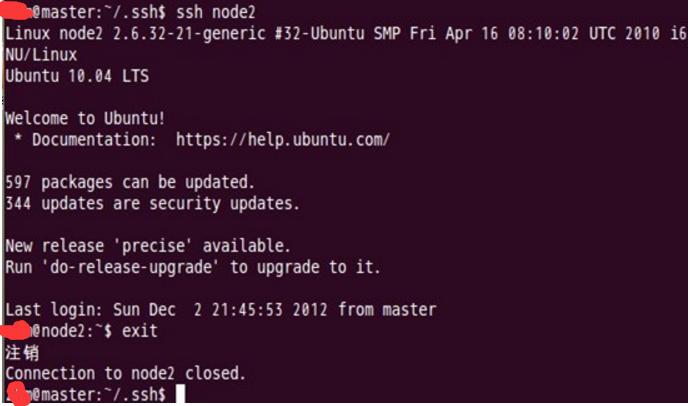
这两个结点的ssh免密码登录已经配置成功,但是我们还需要对主结点master也要进行上面的同样工作,
这一步有点让人困惑,但是这是有原因的,具体原因现在也说不太好,据说是真实物理结点时需要做这项工作,
因为jobtracker有可能会分布在其它结点上,jobtracker有不存在master结点上的可能性。
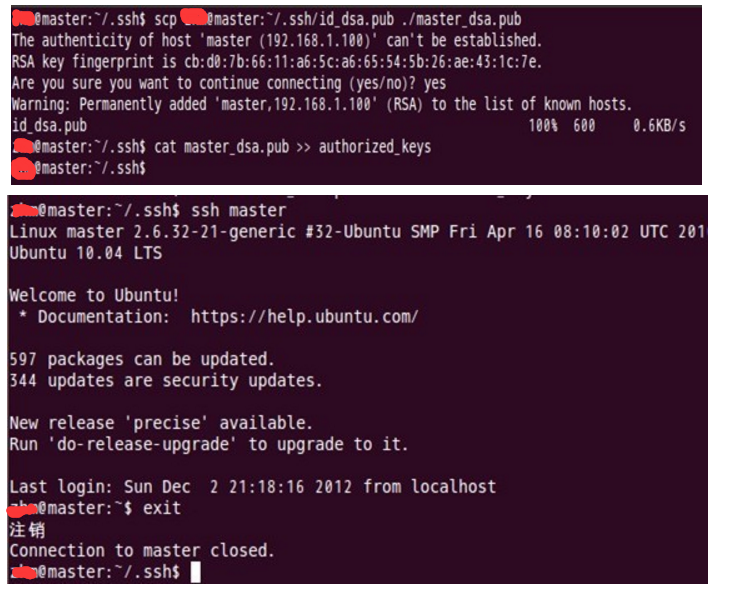
截图中手红色莫抹线,请替换成你的账户。
3.安装hadoop
下载hadoop 任意版本,将文件解压到 /home/hadoop下
命令: vi /etc/profile
在profile文件中添加如下几行代码:
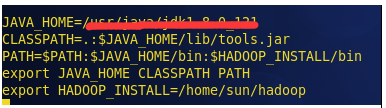
这是我的配置文件,
JAVA_HOME= (本文章第一大点,4 小点 ) 用 echo $JAVA_HOME 检查JDK运行目录
HADOOP_INSTALL = 你的hadoop文件路径
以上完成后,让配置文件生效命令:source /etc/profile
上面配置过程每个结点都要进行一遍。
下面开始修改hadoop的配置文件了,文件存放在/hadoop/conf下,主要配置core-site.xml、hdfs-site.xml、mapred-site.xml这三个文件。
Core-site.xml配置如下:
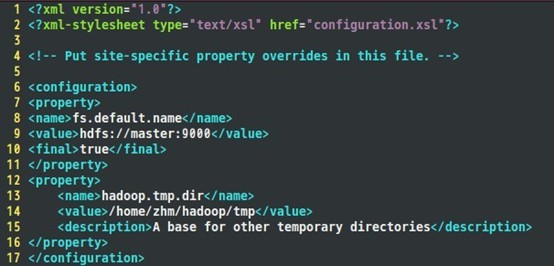
Hdfs-site.xml配置如下:
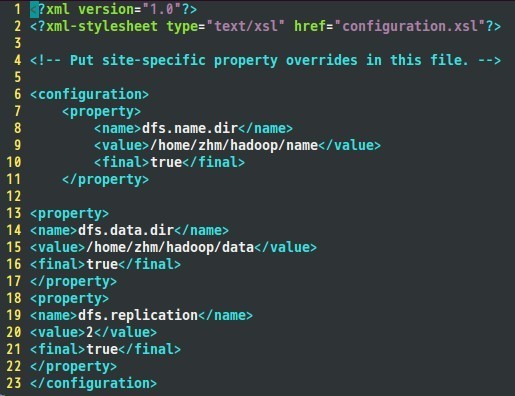
接着是mapred-site.xml文件:
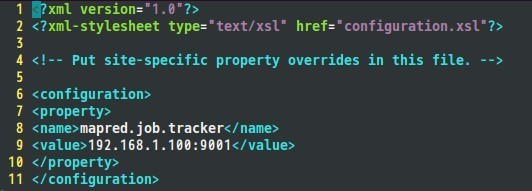
配置hadoop-env.sh文件
这个需要根据实际情况来配置。

以上文件涉及到jdk、hadoop路径,请修改成你自己jdk、hadoop的路径
在hadoop文件夹下找到master node文件
在masters文件中填入:

在slaves文件中填入:
向node1节点复制hadoop:

向node2节点复制hadoop:

这一步在主结点master上进行操作:
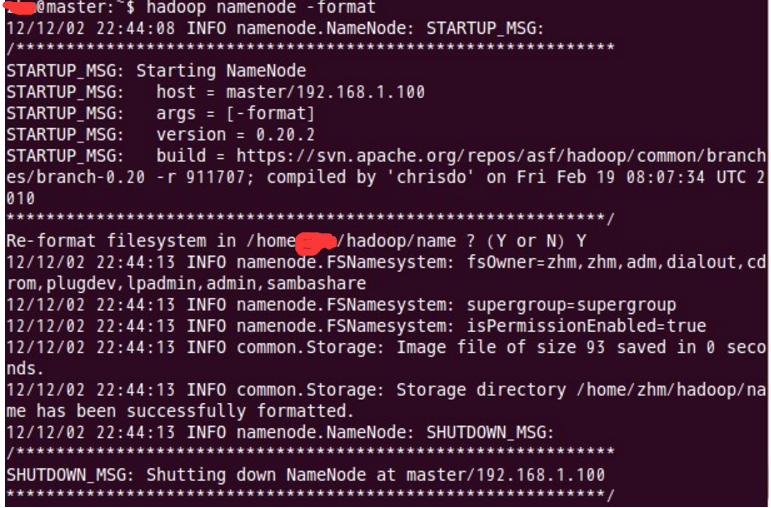
注意:上面只要出现“successfully formatted”就表示成功了。
5. 启动hadoop
在master上操作
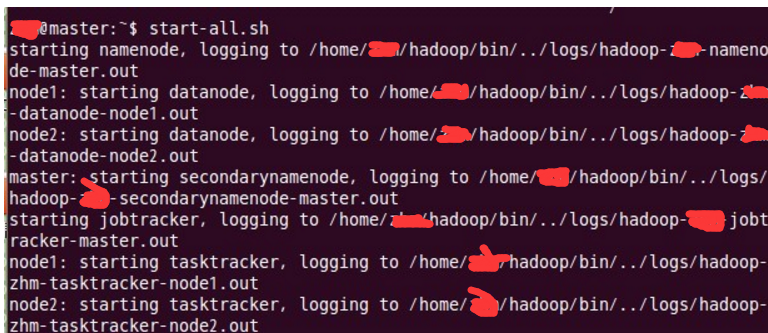
用jps检验各后台进程是否成功启动
在主结点master上查看namenode,jobtracker,secondarynamenode进程是否启动。
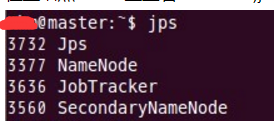
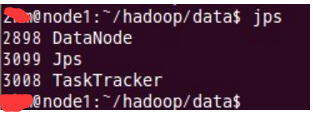
在node1和node2结点了查看tasktracker和datanode进程是否启动。
先来node1的情况:
下面是node2的情况:
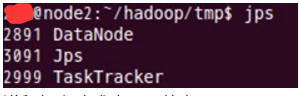
进程都启动成功了。恭喜~~~
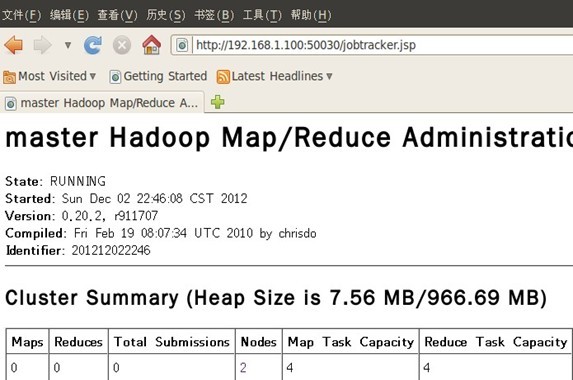
通过网站查看集群情况
在浏览器中输入:http://192.168.1.100:50030,网址为master结点所对应的IP:

在浏览器中输入:http://192.168.1.100:50070,网址为master结点所对应的IP:
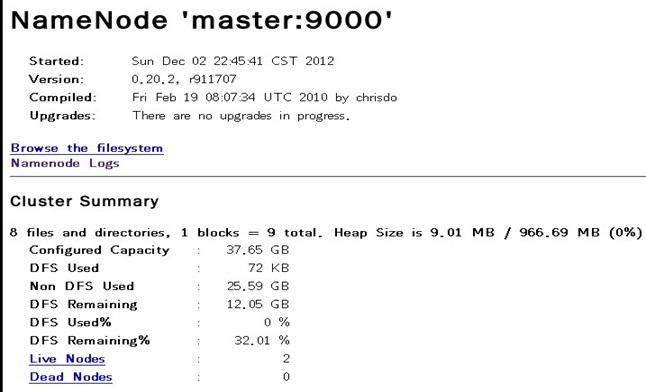
至此,不容易啊~