|
项目名称 |
Crawling is going on |
|
项目版本 |
Beta版本 |
|
负责人 |
北京航空航天大学计算机学院 newbe软件团队 |
|
联系方式 |
http://www.cnblogs.com/newbe |
|
要求发布日期 |
2014-12-27 |
1 更新内容
1.1 修复缺陷
a)之前没有考虑爬取过程中,出现异常会导致爬取线程非正常终止,但是资源被占用。随着异常线程的增加,导致可利用资源全部被占用,整个软件停止工作;在新版本考虑了发生异常释放资源,保证爬取的不间断性。
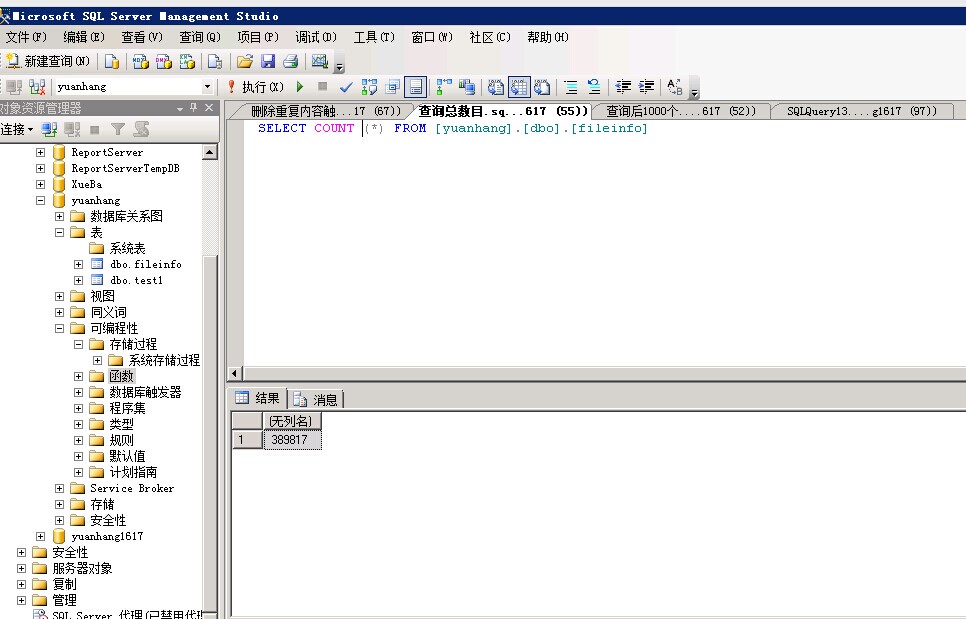
b)将更新数据库的方法改为异步互斥更新方式,保证了同一时间只有一个线程占用数据库,保证了数据库数据的正确性,同时避免了SQLException。
c)精确定位目标网页,减少了爬取失败率和太太率,保证了爬虫的效率和正确性。
d)修改命名方式解决了过去因为重命名而导致文件无法删除或者打开的情况。
e)修复爬取过程中可能爬到具有重复URL的网页的缺陷。
1.2 新增功能
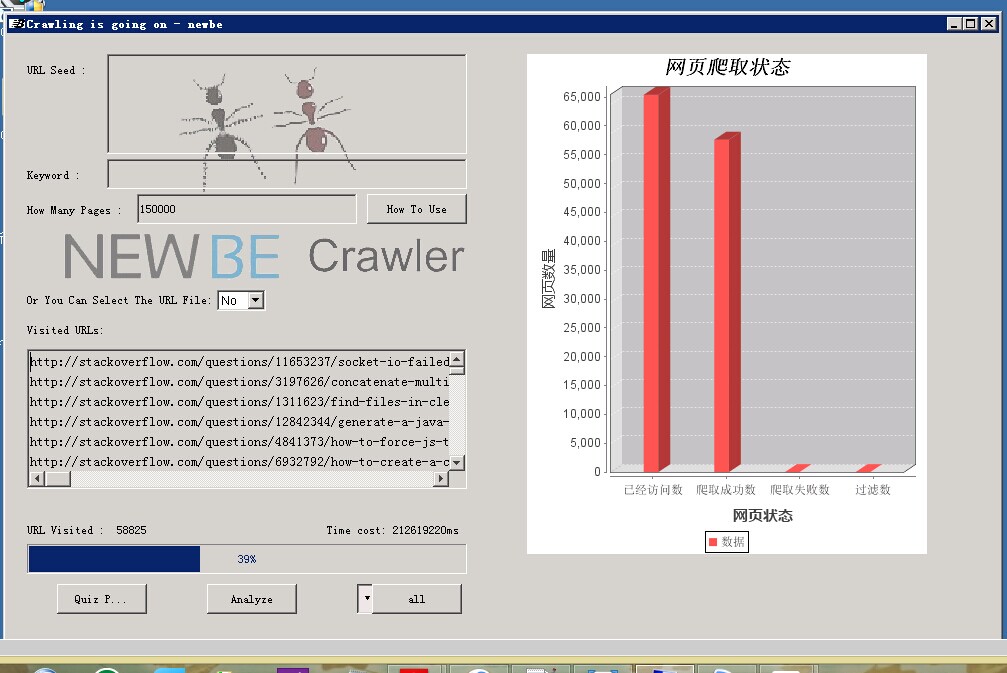
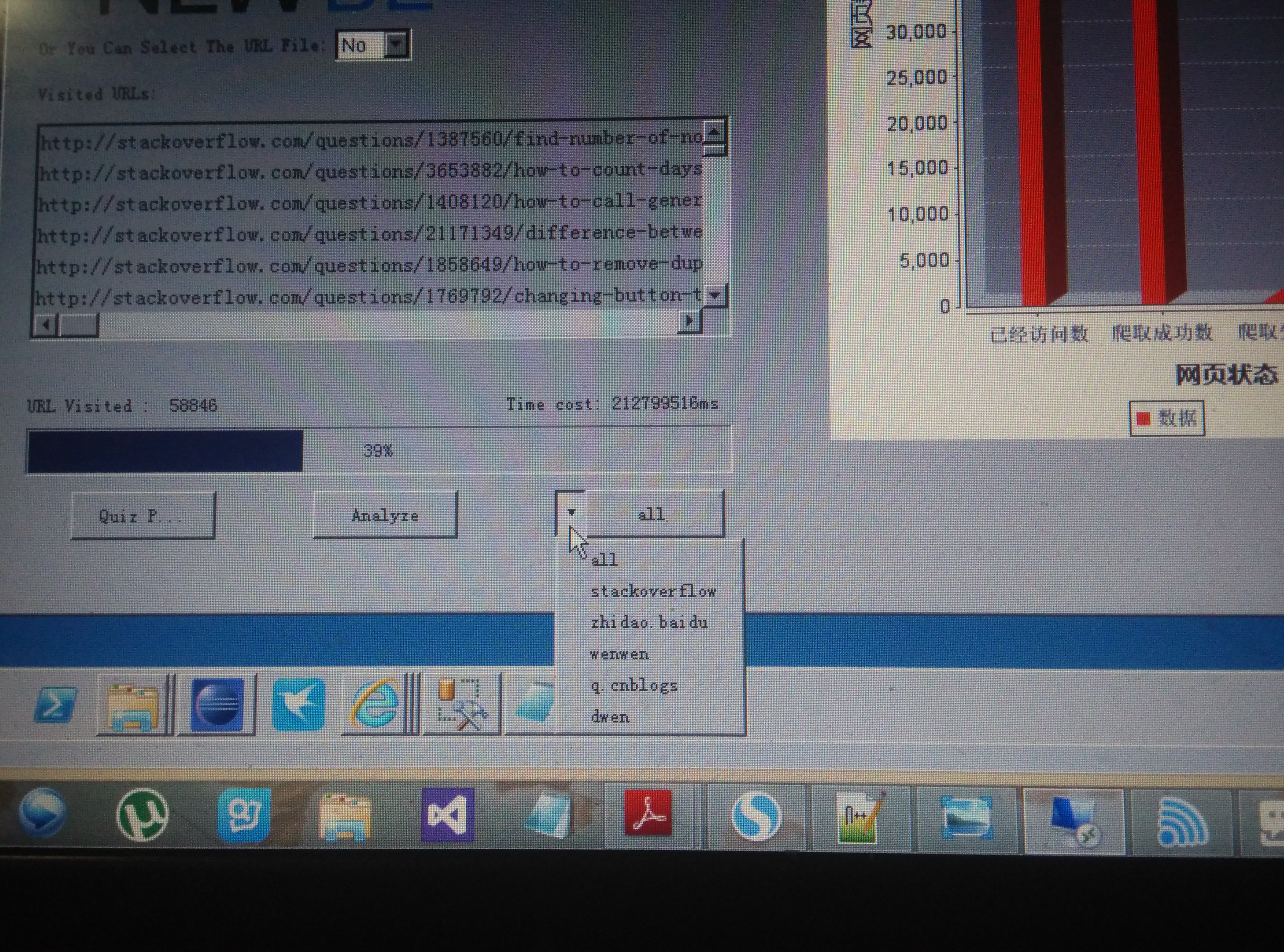
a) 专门爬取问答网页,用户可根据自己兴趣选择爬取不同的网站或者从当前版本给定的所有网站爬取满足流水线组需求。
b) 专门爬取pdf功能。
c) 专门爬取doc功能。
d) 专门爬取ppt功能。
e) 界面进行了排版和优化
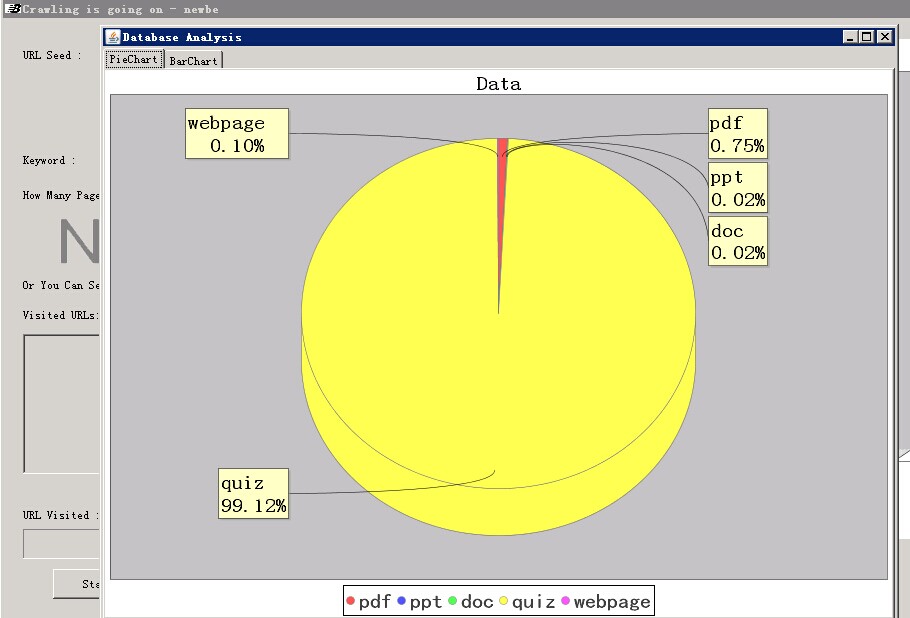
f) 相应修改了分析功能,对数据库内爬取文件的类型和数量进行统计,以饼状图的形式展示。同时以动态的柱状图形式显示爬取过程。

2 环境要求
|
操作系统需求 |
WINDOWS XP,WINDOWS 7,WINDOWS 8 |
|
运行环境需求 |
需安装最新版本的JRE |
|
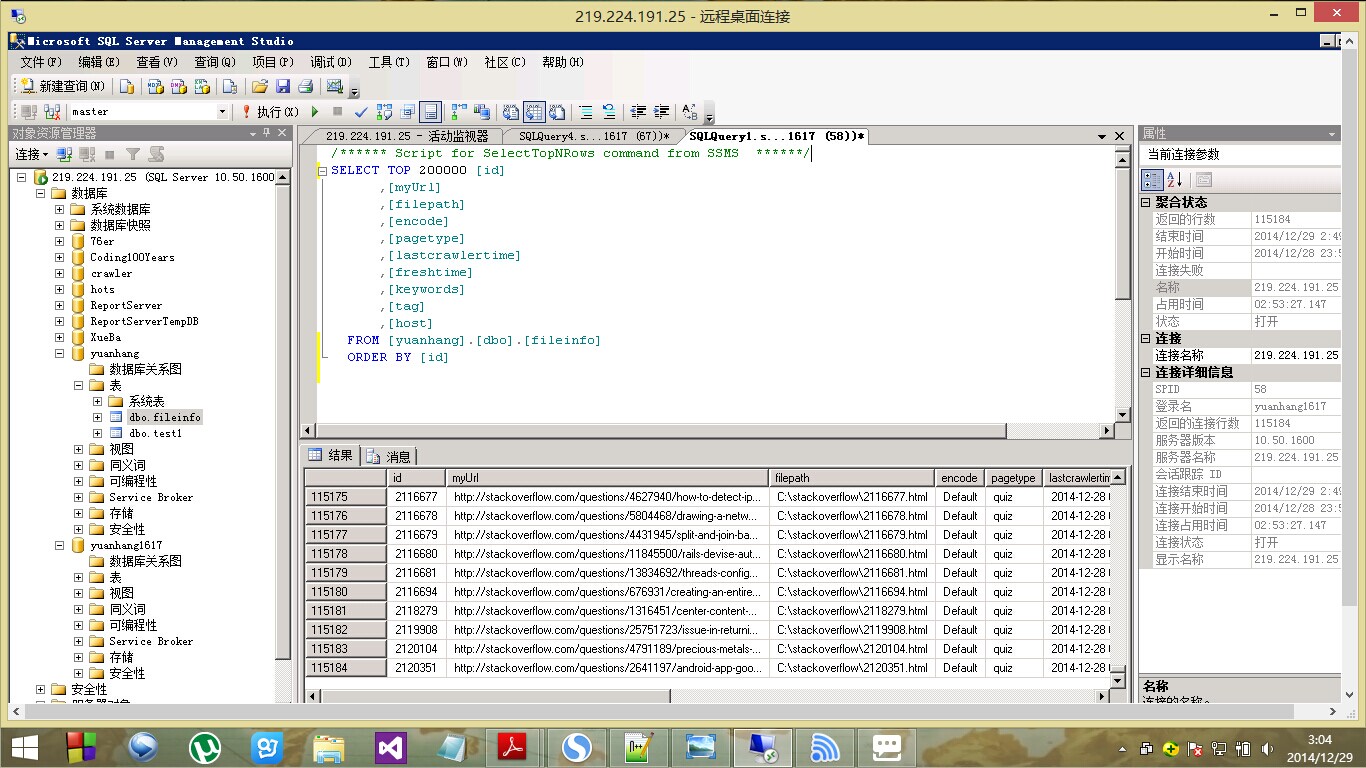
数据库需求 |
在联网的环境下可以直接连接服务器的数据库,本地数据库没有特殊要求 |
3 安装说明
将jar软件复制到本地,运行即可。
4 已知缺陷和限制
爬取问答网站时,部分网站数量较少,全部页面爬取完毕后,仍然阻碍其它网站线程占用资源,会导致爬取速度渐渐变慢。
5 发布地址
该版本代码及程序发布在服务器219.224.191.25上,可自行下载试用。