背景介绍:
小爬我最近给部门开发了一系列OA的爬虫工具,从selenium前端模拟进化到纯requests后台post请求爬取,效率逐步提升。刚开始能维持在0.5秒/笔。可惜当数据超过2000笔后,爬取速度逐渐变慢,最终稳定在1-1.2秒/笔。(此处有较大的坑,原则上在万行数据这个量级上,速度不应该有肉眼可见的衰减幅度的,后期再来填坑)这个速度,我们部门领导表示“满意”。但是我个人不满意这种“从无到有”、“慢总好过纯手工”论调。好多不懂的人总是调侃一句:“可以了,比人手工的速度还是快些的,毕竟是自动爬取,无人值守!”也有开发人员看了之后直摇头:“你这么个爬法,我还不如直接抽出时间修改底层代码,让平台原生支持”,一副对爬虫的无限鄙夷的神情。

由于爬取速度比较慢,为了提升用户体验,我还用selenium载入JS脚本来渲染了一个进度条,效果如下:

体验效果是提升了不少,至少用户不用等待的时候过分焦躁。同事见了面也总是跟我打趣:“可以了,又进步了,这不从黑黑的dos界面进化到web、JS了吗?“,然而我自己清楚自身不足,本质上这个进度条并不会真正让爬虫效率提升。我知道,最终小爬我得去熟悉和掌握多进程、多线程、协程等编程知识,并用到爬虫中,以提升效率。
看了崔庆才的多线程、多进程文章,对比过python多线程、多进程等技术的优劣,这里不做赘述。传送门:https://cuiqingcai.com/3363.html
小爬的工具中用到的多线程模块是mulitiprocessing模块,然后要用到GIL进程锁Lock。没有进程锁的话,数据相互写入的时候会产生排列不规则和乱码。PS:加上进程锁后,程序速度会有一定下滑,但是存储的数据则非常工整有序。
工具的主要思路和步骤:
————————————————————————————————————————————————————————————————————
1、模拟登陆,拿到网页session会话,存储会话中的cookies;
2、后台构造data,发送post请求(携带步骤1提到的cookies),得到json文件,提取出需要爬取的url网址列表,并得到程序的总计算量;
3、利用多进程模块multiprocessing中的Pool(进程池)以及map(可迭代)、partial(偏函数)方法,进行传参,构造多进程,爬取步骤2提到的urls列表,直到爬取完毕,同时保存到txt或者csv文件中;
4、利用tkinter模块构造简单GUI,提高可视化程度,并利用pyinstaller打包为exe文件(此步骤待后续再完善)。
需要注意的要点:
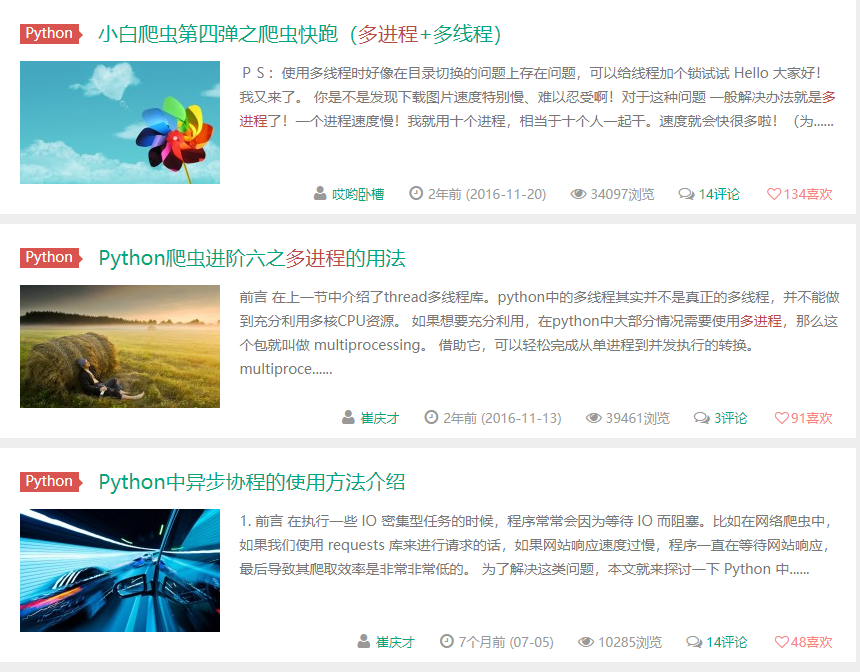
1、多进程的代码需要都写到”if __name__ == '__main__':“语句下方,否则每个进程都会执行头部文件。如果头部代码涉及登陆窗口,则不好意思,程序会瞬间弹出跟进程数匹配的登陆窗口,电脑会崩溃的,亲!!!
模拟个错误范例让诸位引以为戒,不要踩坑,请看下图:
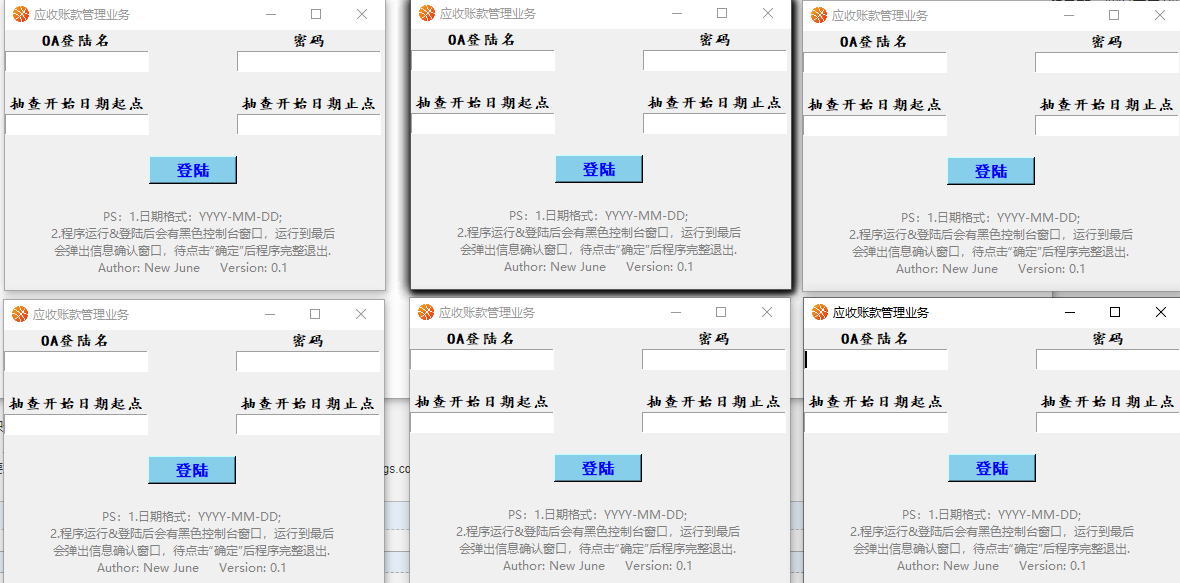
或者这样看更加壮观(恐怖):

2、虽然进程Lock非常有必要,但是锁不是随便加,最好是在涉及IO(数据保存)的代码段添加,以免严重拖慢程序速度,白白牺牲多进程带来的性能提升。
3、这个Lock要设置成全局变量,可以在各个进程间通信和传递;
4、需要将步骤1拿到的cookies(这个就相当于拿到用户权限)挂到步骤3每个进程process的get请求中,做成全局变量,而pool.map(函数名,urlList)方法虽然通俗易懂,但不能直接接收多个可迭代的参数,此时需要利用partial偏函数的知识来传递多个参数;
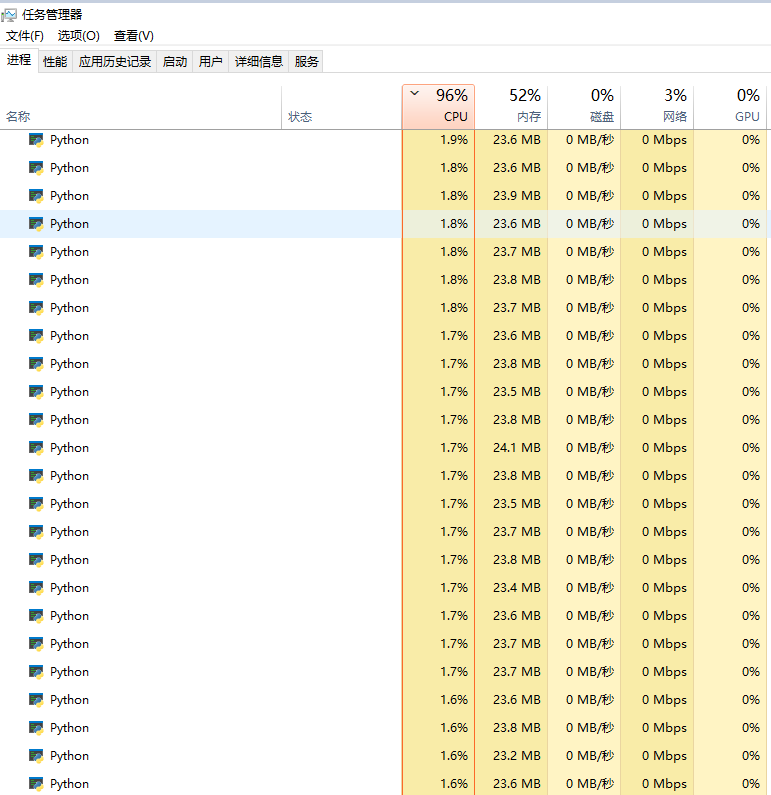
5、进程的数量原则上没有特别的限制,但是计算机的CPU性能和内存大小都会限制网页爬取和解析的速度。所以,进程数并非越大越好。在小爬我的个人电脑上,当进程数开到15时,CPU就基本维持在90%的利用率,再提升进程数到100,速度的提升都不明显,反而
电脑会因CPU满载而导致大概率卡死。所以,务必根据实际情况选择程序的进程数。多进程的python再任务管理器中是这样的:
下面为小爬上面的工具提到的详细的代码,供参考:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2019/1/25 17:15 # @Author : New June # @Desc : # @Software: PyCharm from multiprocessing import Process, Lock, Queue,Pool import time,re,datetime,csv,loginInfo,requests,json from requests.exceptions import ConnectionError from lxml import etree from math import ceil from bs4 import BeautifulSoup from functools import partial def get_urls(cookies): bpmDefNames=['采购订单结算'] startDate="2018-09-01" endDate="2018-12-01" urls=[] data_search={ 'page':1, 'rows':10, 'condition': """[ {"column":"BPM_DEF_NAME","exp":"in","value":"""+str(bpmDefNames)+"""}, {"column":"DELETE_STATUS","exp":"=","value":0}, {"column":"TO_CHAR(TO_DATE(CREATE_DATE,'YYYY-MM-DD HH24:MI:SS'),'YYYY-MM-DD')","exp":">=","value":"%s"}, {"column":"TO_CHAR(TO_DATE(CREATE_DATE,'YYYY-MM-DD HH24:MI:SS'),'YYYY-MM-DD')","exp":"<=","value":"%s"}, {"column":"CHECK_TYPE","exp":"like","value":"2"}, {"column":"LOCKED_STATUS","exp":"=","value":0}, {"column":"DELETE_STATUS","orderType":"default","orderKey":"","direction":"ASC"} ]"""%(startDate,endDate), 'additionalParams':'{}' } s=requests.session() s.cookies=cookies #登陆,然后拿到session中的cookies,供后续使用 try: response=s.post(url=url1,data=data_search) if response.status_code==200: pageContent = response.json() except requests.ConnectionError as e: print('Error',e.args) maxNum=ceil(pageContent['total']/400) #maxNux即表单翻页的总页数 for i in range(1,maxNum+1): data_search['page']=i data_search['rows']=400 response=s.post(url=url2,data=data_search) pageContent = response.json() listlen=len(pageContent['rows']) for num in range(listlen): dataId = pageContent['rows'][num]['dataId'] #每个表单的dataID号 urls.append(url3+dataId) #print("urlLength:",len(urls)) return urls def get_content(settlement_href,cookies): '''获取源码解析网页并保存到txt''' operatorName1="" operatorName2="" #作业人员 变量初始化 operateTime1="" operateTime2="" s=requests.session() s.cookies=cookies res = s.get(url=settlement_href,timeout=60) #print(res.encoding) soup=BeautifulSoup(res.content,"lxml") haf=str(soup.select('script')[6]) #得到字段,再进行后续提取 flowHiComments=re.search('.*?flowHiComments":(.*?),"flowHiNodeIds.*?',haf,re.S) flowHiComments=json.loads(flowHiComments.group(1)) #得到页面评论信息 applyerName=re.search('.*?applyerName":"(.*?)".*?',haf,re.S).group(1) #申请人姓名 applyerId=soup.find(id="afPersonId")['value'] #申请人编号 afFormNumber=soup.find(id="afFormNumber")['value'] #申请单号 totalAmount=str(soup.find(id="totalMoneyPlustax")["value"])#含税金额 supplierName=soup.find(id="supplierName")["value"]#供应商名称 settlementCategoryName=soup.find(id="settlementCategoryName")["value"].strip()#结算类别 companyCode=soup.find(id="companyCode")["value"]#公司代码 flowHiComments=json.loads(re.search('.*?flowHiComments":(.*?),"flowHiNodeIds.*?',str(soup.select('script')[6]),re.S).group(1)) for comment in range(len(flowHiComments)-1,-1,-1): #从审批流后往前数 if operatorName1=="" and flowHiComments[comment]['subOperateType']=='submit' and flowHiComments[comment]['nodeName']== '角色B': operatorName1=flowHiComments[comment]['operaterName'] operateTime1=flowHiComments[comment]['operateTime'] continue elif operatorName2=="" and flowHiComments[comment]['subOperateType']=='submit'and flowHiComments[comment]['nodeName']== "角色A": operatorName2 = flowHiComments[comment]['operaterName'] operateTime2 = flowHiComments[comment]['operateTime'] break lock.acquire() #添加锁 with open("abc.txt",'a',encoding='utf-8') as f: f.write("%s %s %s %s %s %s %s %s %s %s %s "%(afFormNumber,companyCode,settlementCategoryName,applyerName,applyerId,totalAmount,supplierName,operatorName1,operateTime1,operatorName2,operateTime2)) lock.release()#释放锁 def init(l): global lock #定义lock为全局变量,供所有进程用 lock = l # print("申请人:%s;申请人ID:%s;申请单号:%s;含税金额:%s;供应商名称:%s "%(applyerName,applyerId,afFormNumber,totalAmount,supplierName)) if __name__ == '__main__': """登陆,拿到登陆后的session""" loginData={'redirect':'','username':loginInfo.username,'password':loginInfo.password} session=requests.session() session.post(login_url,loginData) cookies=session.cookies totalStartTime = datetime.datetime.now() #所有业务的起始时间 urls=get_urls(cookies) with open("abc.txt","w",encoding="utf-8") as t: t.write("表单号 公司码 结算类别 申请人 申请人ID 含税金额 供应商名称 角色A 角色A提交时间 角色B 角色B提交时间 ") lock = Lock() pool = Pool(processes=20,initializer=init, initargs=(lock,)) #设定进程数为20 pool.map(partial(get_content,cookies=cookies),urls) #利用偏函数传递多个参数给get_content函数 pool.close() pool.join() endtime=datetime.datetime.now() print("time consuming:%d seconds"%(endtime-totalStartTime).seconds)
最终是需要导出csv、txt还是xlsx文件,则根据实际的业务需求来即可。小爬我导出的txt长这样:
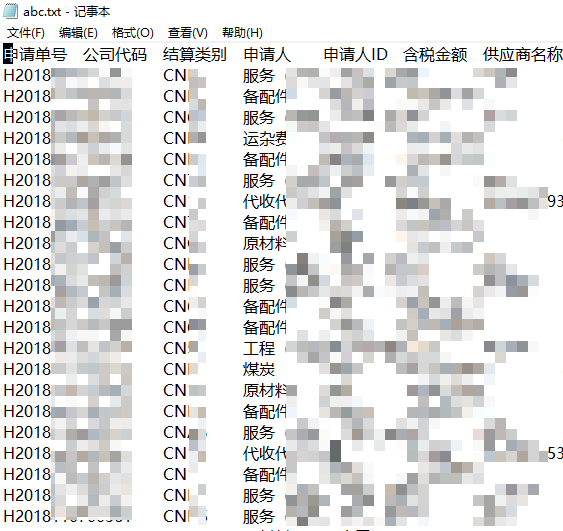
经测算,通过引入多进程(进程数大于10),平均速度提升到0.1秒/笔,较原先的爬虫速度提升了一个数量级。小爬我这才长吁一口气,总算让爬虫从”爬“到”飞“!猴嗨森~
