转自:http://blog.csdn.net/liumaolincycle/article/details/50471289#t0
综述:
http://blog.csdn.net/sunbaigui/article/details/50807362
googlenet和vgg是2014年imagenet竞赛的双雄,这两类模型结构有一个共同特点是go deeper。跟vgg不同的是,googlenet做了更大胆的网络上的尝试而不是像vgg继承了lenet以及alexnet的一些框架,该模型虽然 有22层,但大小却比alexnet和vgg都小很多,性能优越。
具体网络配置如链接:https://github.com/BVLC/caffe/blob/master/models/bvlc_googlenet/train_val.prototxt
文章提出获得高质量模型最保险的做法就是增加模型的深度(层数)或者是其宽度(层核或者神经元数),但是这里一般设计思路的情况下会出现两个缺陷(1.参 数太多,容易过拟合,若训练数据集有限;2.网络越大计算复杂度越大,难以应用;3.网络越深,梯度越往后穿越容易消失,难以优化模型)。 googlenet的主要思想就是围绕这两个思路去做的:
1.深度,层数更深,文章采用了22层,为了避免上述提到的梯度消失问题,googlenet巧妙的在不同深度处增加了两个loss来保证梯度回传消失的现象。
2.宽度,增加了多种核 1x1,3x3,5x5,还有直接max pooling的,但是如果简单的将这些应用到feature map上的话,concat起来的feature map厚度将会很大,所以在googlenet中为了避免这一现象提出的inception具有如下结构,在3x3前,5x5前,max pooling后分别加上了1x1的卷积核起到了降低feature map厚度的作用。
综上googlent有两个最重要的创新点分别是为了解决深度和宽度受限来设计的,由于googlenet的两个辅助loss的限制,很多文章拿base model的时候比较偏向与vgg。
优点:
把整个Inception的网络架构画出来,更直观感受网络结构
1.宽度。总共是9个Inception的模块,每个模块除了num_output的个数不一样之外,其他的都是相同的。每一个卷积后都要做relu操作。
2.深度。除了在最后的全连接计算了loss和top_1,top_5的准确率之外,还在inception_4a/output和inception_4d/output之后进行池化卷积全连接,最后计算loss和top_1,top_5。
个人感觉这种方式,一方面可以比较不同深度下的loss和准确率,同时,这些中间层的backward computation会对整个起到调整梯度的作用,这样防止当层次过深时的梯度消失的问题。
Overview
本文提出了一种深度卷积神经网络架构, 代号为Inception(是不是让人想到《盗梦空间》中一层层的梦境呢),获得了ILSVRC14比赛的冠军,刷新了图像分类与检测的性能记录。该网络 的特点是提升了计算资源的利用率,可以在保持网络计算资源不变的前提下,通过工艺上的设计来增加网络的宽度和深度,基于Hebbian法则和多尺度处理来 优化性能。在ILSVRC2014中提交的版本叫GoogLeNet,共有22层。
GoogLeNet用的参数比ILSVRC2012的冠军AlexNet少12倍,但准确率更高。现在的目标检测例如R-CNN,结合了深度架构和传统计算机视觉方法进行目标检测。
由于移动设备和嵌入式计算的发展,算法的效率很重要,一个好的算法,不仅要具有学术性,也要能用于实际中。
Motivation and High Level Considerations
直接提升深度卷积网络性能的方法是从深度与宽度两方面增加尺寸,但大尺寸的网络需要更多参数,容易导致过拟合,尤其是数据集不够大的时候,直接增加 尺寸的另一个弊端是需要大量计算资源。根本的解决办法是将全连接层变为稀疏链接层,而非均匀稀疏网络的弊端是计算效率不高,可以采用将多个稀疏矩阵合并成 相关的稠密子矩阵的方法来解决。
Architectural Details
Inception架构的主要思想是找出如何让已有的稠密组件接近与覆盖卷积视觉网络中的最佳局部稀疏结构。现在需要找出最优的局部构造,并且重复 几次。之前的一篇文献提出一个层与层的结构,在最后一层进行相关性统计,将高相关性的聚集到一起。这些聚类构成下一层的单元,且与上一层单元连接。假设前 面层的每个单元对应于输入图像的某些区域,这些单元被分为滤波器组。在接近输入层的低层中,相关单元集中在某些局部区域,最终得到在单个区域中的大量聚 类,在下一层通过1x1的卷积覆盖。

也可以通过在更大的patch上卷积,覆盖少量的在空间上更大的聚类,区域越来越大,patch数越来越少。



为了避免patch校准问题,现在的滤波器大小限制在1x1,3x3和5x5,主要是为了方便,不是必要的。这样的Inception模块如下:

另外,在pooling层添加一个额外的并行pooling路径用于提高效率。

Inception模块之间互相堆放,它们的输出相关性统计一定会改变:高层次提取高抽象性的特征,空间集中性会降低,因此3x3和5x5的卷积核在更高层会比较多。
采用上面的模块有一个大问题是在卷积层顶端由于滤波器太多,即使是5x5的卷积都会让计算开销过分昂贵。当pooling单元加入之后这个问题更加明显:输出滤波器的数量等于前一步中滤波器的数量。pooling层的输出和卷积层的输出融合会导致输出数量逐步增长。即使这个架构可能包含了最优的稀疏结构,还是会非常没有效率,导致计算没经过几步就崩溃。
因此有了架构的第二个主要思想:在计算要求增加很多的地方应用维度缩减和预测。即,在3x3和5x5的卷积前用一个1x1的卷积用于减少计算,还用于修正线性激活。如下图所示,左边是加入维度缩减之前的,右边是加入维度缩减之后的。
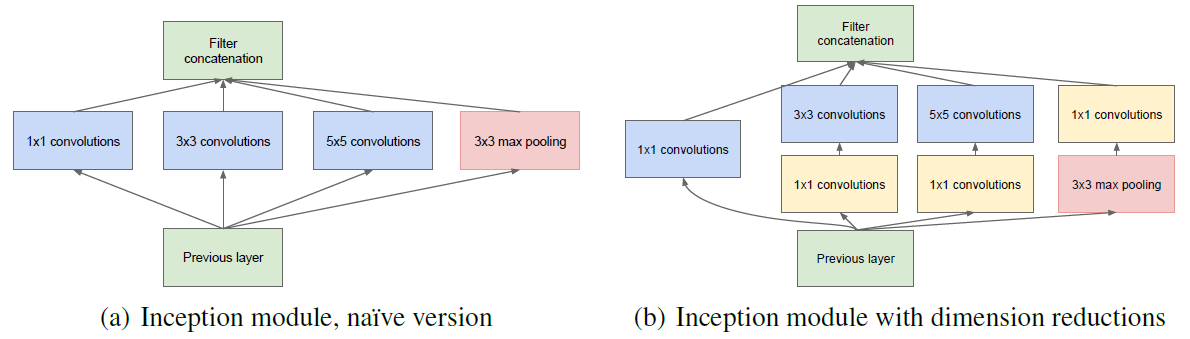
技术上的做法是,保持低层为传统卷积方式不变,只在较高的层开始用Inception模块。
这种架构的两个主要优点:一是允许显著增加每一步的单元数目,计算复杂性不会不受控制。降维的普遍使用能保护最后一步到下一层的大量输入滤波器,在对它们用大的patch size卷积前首先降维。二是视觉信息在不同的尺度上进行处理然后聚合,这样下一步可以同时从不同尺度提取特征。
采用了Inception模块的网络要比没有采用Inception模块的同样架构的网络快2~3倍。
GoogLeNet
采用Inception架构的GoogLeNet如下所示:
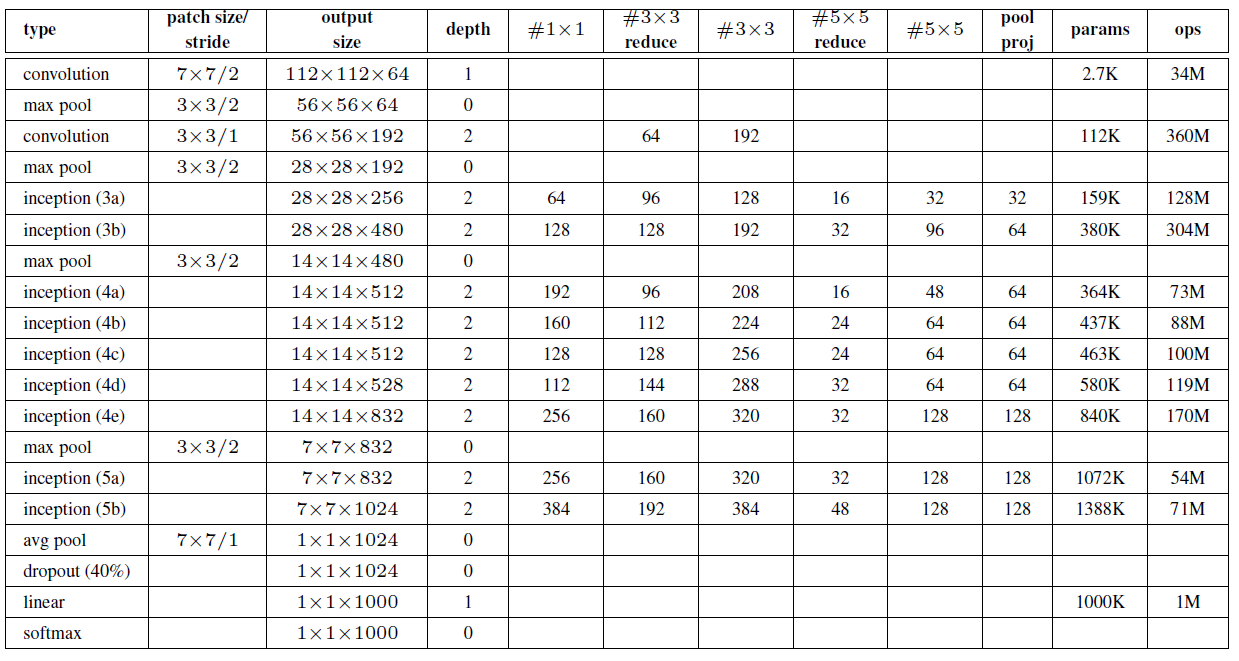
总体结构:
1.包括Inception模块的所有卷积,都用了修正线性单元(ReLU);
2.网络的感受野大小是224x224,采用RGB彩色通道,且减去均值;
3.#3x3 reduce和#5x5 reduce分别表示3x3和5x5的卷积前缩减层中1x1滤波器的个数;pool proj表示嵌入的max-pooling之后的投影层中1x1滤波器的个数;缩减层和投影层都要用ReLU;
4.网络包含22个带参数的层(如果考虑pooling层就是27层),独立成块的层总共有约有100个;
5.网络中间的层次生成的特征会非常有区分性,给这些层增加一些辅助分类器。这些分类器以小卷积网络的形式放在Inception(4a)和Inception(4b)的输出上。在训练过程中,损失会根据折扣后的权重(折扣权重为0.3)叠加到总损失中。
GoogLeNet 网络结构图:

辅助分类器的具体细节:
1.均值pooling层滤波器大小为5x5,步长为3,(4a)的输出为4x4x512,(4d)的输出为4x4x528;
2.1x1的卷积有用于降维的128个滤波器和修正线性激活;
3.全连接层有1024个单元和修正线性激活;
4.dropout层的dropped的输出比率为70%;
5.线性层将softmax损失作为分类器(和主分类器一样预测1000个类,但在inference时移除)。
Training Methodology
利用分布式机器学习系统和数据并行来训练网络,虽然实现时只用了CPU,但是是可以用个别高端的GPU一周达到收敛的。采用异步随机梯度下降,动量为0.9,学习率每8个epoch下降4%。用Polyak平均来创建最后的模型。
图像采样的patch大小从图像的8%到100%,选取的长宽比在3/4到4/3之间,光度扭曲也有利于减少过拟合,还使用随机插值方法结合其他超参数的改变来调整图像大小。
ILSVRC 2014 Classification Challenge Setup and Results
ILSVRC 2014的分类任务有1000个子类,120万训练图像,5万验证图像,10万测试图像,每个图像中有一个ground truth,性能测量是基于得分最高的分类器预测,常用指标为top-1准确率和top-5错误率。
测试时的一些小技巧:
1.训练了7个网络,初始化和权重都相同,只是采样方法和随机输入图像不同;
2.将图像的短边分别缩放成256、288、320、352这样4种尺度。取图像的左中右块(或上中下块)。每块取四个角和中间的224x224的裁剪,和将这个块缩放到224x224,以及它们的镜像。这样每个图像有4x3x6x2=144个,但可能实际中不需要这么多;
3.softmax概率在多个裁剪和在所有分类器上取平均来获得最后的预测,简单的平均结果最好。
最终的top-5错误率在验证集和测试集上都是6.67%,获得了第一。与其他方法相比的提高如下所示:

以及分析了多种测试选项:

ILSVRC 2014 Detection Challenge Setup and Results
检测任务的标准是检测出来的bounding box与groundtruth的交叠比大于50%且是正确的,图像中可能包含多个目标或者不包含目标,尺度可能很大可能很小,采用的结果报告方式是mAP。
采用的目标检测方法与R-CNN很像,但增加了Inception模块作为区域分类器。结合了用multi-box的方法和Selective Search来提高bounding box的召回率,没有用bounding box回归。
下图是一些比赛结果:

下图是单个模型的性能比较:
