生产者消费者模式下的可覆盖环形数据缓冲结构
1、简介
生产者—消费者模式是软件架构中最常用到的模式,在实际的软件开发过程中,经常会碰到如下场景:某个模块负责产生数据,这些数据由另一个模块来负责处理(此处的模块是广义的,可以是类、函数、线程、进程等)。产生数据的模块,就形象地称为生产者;而处理数据的模块,就称为消费者。
单单抽象出生产者和消费者,还够不上是生产者/消费者模式。该模式还需要有一个缓冲区处于生产者和消费者之间,作为一个中介。生产者把数据放入缓冲区,而消费者从缓冲区取出数据。大概的结构如下图。

生产者不停的将数据放入缓冲区,即是物理内存,如果生产者产生数据的速度过快以至于消费者来不及将数据读出,这个缓冲区就会产生溢出的现象,解决这个问题最好的办法就是采用环形缓冲区。先在物理内存开辟一块单独的空间,采用链表的形式将这块内存连接成环状,产生的数据和将要被读取的数据都在这个环状的内存缓冲区中,于是不会出现内存溢出的问题。
但是这种缓冲结构也有一个缺点,当写入数据的速度远远大于读取的速度时,写入位已经经过一圈到达读出位前一个数据单元,这时通常的做法是让写入等待,这有读取完一个单元,才能空出这个单元用以写入,实际生产过程中对于一些数据是可以舍弃掉的,同时,舍弃掉的必须是最老也就是最早写入的数据,而必须将最新的数据保存下来,按照传统做法是不能实现这种要求的,这也是本文可覆盖环形缓冲区的由来。
2、概述
思考下面一种场景,软件设计中有两个线程,线程1用来接收网卡中的数据包,并将这些数据包解析后写入同样结构的结构体中,而另外一个线程2则需要将结构体中的数据写入数据库。这是一个非常典型的生产者消费者模式,我们需要在这两个线程中间架设一个环形缓冲区,线程1将网卡数据写入缓冲区,线程2在这个缓冲区中读取数据,这样两个线程不直接依赖,耦合程度降低,易于进行处理。
在这个软件结构中,理想的情况下,写入缓冲区的速度与读缓冲区的速度保持着某种均衡,线程2总是可以将缓冲区的数据读完,而线程1不会领先线程2一圈以至于线程1只有等待,大概结构如下图所示:
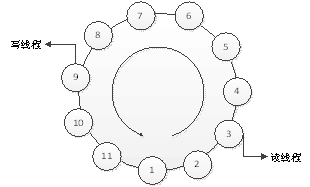
看着这个结构可以想象得到,此时写线程和读线程保持一定距离,如果距离保持这样,那么读线程永远追不上写线程,这是一个稳定的读写过程。但是写线程的速度如果大于读的速度,例如读线程在读取3号节点的数据,而写线程已经经过一圈写到2号节点,当写完2号节点时,如果按照传统流程,写线程将处于等待状态,但是由于我们更加关注网卡最新的数据,如果这时写线程等待,那么大量的最新数据将会被丢弃掉,这不是我们想看到的,于是我们选择丢弃掉老的数据,用新数据来对老节点进行覆盖,那么这时写线程将从4号节点开始写入,依次向下。
当有老的未读的数据被新的数据覆盖的时候,例如,写线程这时已经覆盖掉4号和5号节点的数据,而这时读线程刚好读完3号节点的数据,由于4、5号节点的数据都是最新的,按照逻辑,这两个节点的数据应该最后读取,所以这时读线程应该读取6号节点的数据,依次向下。
以上就是可覆盖缓冲区的逻辑结构,下一节描述整个过程的具体实现。
3、实现
3.1 写部分
写线程从网卡拿到数据后,经过处理分析,存储到环形缓存的结构体中,当对一个节点进行写操作时,锁住这个节点,这样,读线程会绕过这个节点读取下一个。
while(Nethead->next->lock) //Nethead为将要写入数据的节点 Nethead=Nethead->next; Nethead=Nethead->next; Nethead->lock=true;
每写完一个节点,解锁这个节点,同时将这个节点的地址放入一个任务队列中,如果写入队列的节点地址和队列头部的节点地址相同,则将头部地址弹出写入队尾。
if(t==m_TaskQueue.front()) //m_TaskQueue是将要读取数据的任务队列 { p=m_TaskQueue.front(); m_TaskQueue.pop_front(); m_TaskQueue.push_back(p); } else { m_TaskQueue.push_back(t); }
3.2 读部分
读线程从任务队列中弹出头节点的地址,再在这个地址的节点中取出想要的数据,读取这个节点的时候从锁住这个节点,同时在任务队列中弹出头结点。
while(!m_TaskQueue.empty()) { p=m_TaskQueue.front(); m_TaskQueue.pop_front(); if(p->lock) p=NULL; else { p->lock=true; break; } }
3.3 总结
这个结构最关键的地方在于,写完节点后放入任务队列中,这里增加了一个判断,即如果写入队列的节点地址和队列头部的节点地址相同,则将头部地址弹出写入队尾。
如果写入队列的节点地址和队列头部的节点地址相同意味着写线程已经超过读线程一圈然后开始写入读线程节点的下一个节点,那么,这个新写入的节点则必然放入任务队列的尾部,这样才能保证逻辑正确。