一.常用的设计模式
1.单例模式
确保一个类只有一个实例,并提供一个访问它的全局访问点。
比如说我们在系统运行时候,就需要加载一些配置和属性,这些配置和属性是一定存在了,又是公共的,同时需要在整个生命周期中都存在,所以只需要一份就行,这个时候如果需要我再需要的时候new一个,再给他分配值,显然是浪费内存并且再赋值没什么意义,所以这个时候我们就需要单例模式或静态方法去维持一份且仅这一份拷贝,但此时这些配置和属性又是通过面向对象的编码方式得到的,我们就应该使用单例模式,或者不是面向对象的,但他本身的属性应该是面对对象的,我们使用静态方法虽然能同样解决问题,但是最好的解决方案也应该是使用单例模式。
从功能上讲:单例模式可以控制单例数量;可以进行有意义的派生;对实例的创建有更自由的控制;
如果我们考虑不需要继承和多态的时候,就可以使用静态方法,但就算不考虑继承和多态,就一概使用静态方法也不是好的编程思想。
从另一个角度考虑,如果一个方法和他所在类的实例对象无关,那么它就应该是静态的,否则就应该是非静态。因此像工具类,一般都是静态的。
对于每个线程都会对线程辅助对象locker加锁之后再判断实例是否存在,对于这个操作完全没有必要的,因为当第一个线程创建了该类的实例之后,后面的线程此时只需要直接判断(uniqueInstance==null)为假,此时完全没必要对线程辅助对象加锁之后再去判断,所以上面的实现方式增加了额外的开销,损失了性能,为了改进上面实现方式的缺陷,我们只需要在lock语句前面加一句(uniqueInstance==null)的判断就可以避免锁所增加的额外开销,这种实现方式我们就叫它 “双重锁定”
/// <summary> /// 单例模式的实现 /// </summary> public class Singleton { // 定义一个静态变量来保存类的实例 private static Singleton uniqueInstance; // 定义一个标识确保线程同步 private static readonly object locker = new object(); // 定义私有构造函数,使外界不能创建该类实例 private Singleton() { } /// <summary> /// 定义公有方法提供一个全局访问点,同时你也可以定义公有属性来提供全局访问点 /// </summary> /// <returns></returns> public static Singleton GetInstance() { // 当第一个线程运行到这里时,此时会对locker对象 "加锁", // 当第二个线程运行该方法时,首先检测到locker对象为"加锁"状态,该线程就会挂起等待第一个线程解锁 // lock语句运行完之后(即线程运行完之后)会对该对象"解锁" // 双重锁定只需要一句判断就可以了 if (uniqueInstance == null) { lock (locker) { // 如果类的实例不存在则创建,否则直接返回 if (uniqueInstance == null) { uniqueInstance = new Singleton(); } } } return uniqueInstance; } }
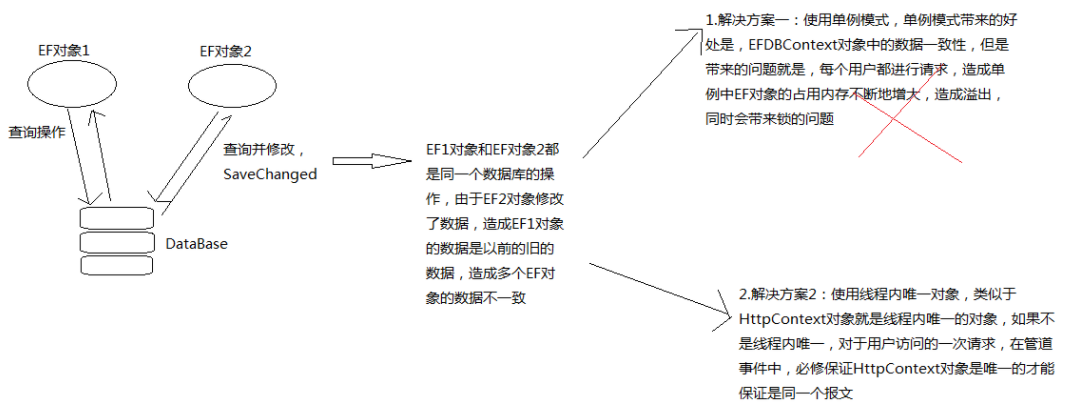
上下文对象的创建问题。
这里首先想到单例模式,不过在这里,不适合用,原因是使用单例模式,会使EF对象得不到及时的资源释放。想象一下,无数个请求对数据库的访问,DbContext对象容器无数次增加对Model对象的Attach监控,内存就爆了。
优化就是折中的过程,所以第二种方式考虑保证在线程内对象唯一,对于每一个请求使用同一个上下文。如何保证呢,通过微软ASP机制线程相关的HttpContext对象以及CallContext对象。前面一篇文章中说过,HttpContext机制其实就是依靠CallContext对象实现的。先来看使用CallContext解决这个问题
/// <summary> /// 用来创建EF上下文对象,且保证线程内唯一。 /// </summary> public class DbContextFactory { //DbContext在System.Data.Entity;中,不过这里直接只引用这一个不行,还有EF其他的一些NameSpace所以直接添加一个实体模型,所有引用都进来了,然后再把模型删了 public static DbContext GetDbContext() { DbContext dbContext = (DbContext)CallContext.GetData("dbContext"); if (dbContext == null) { dbContext = new WebEntities(); CallContext.SetData("dbContext", dbContext); } return dbContext; } }
2.工厂模式
工厂模式细分的话有简单工厂模式、抽象工厂模式等。它最核心的就是如何通过 Factory new 一个 对象出来。在ASP.NET MVC 消息处理实现过程中工厂模式运用的非常多。
1.简单工厂模式
简单工厂模式:考虑用独单的类来创建实例的过程,这就是工厂,简单工厂模式我们也可以理解为负责生产对象的一个类, 我们平常编程中,当使用"new"关键字创建一个对象时,此时该类就依赖与这个对象,也就是他们之间的耦合度高,当需求变化时,我们就不得不去修改此类的源码,此时我们可以运用面向对象(OO)的很重要的原则去解决这一的问题,该原则就是——封装改变,既然要封装改变,自然也就要找到改变的代码,然后把改变的代码用类来封装
简单工厂模式的优点:
- 简单工厂模式解决了客户端直接依赖于具体对象的问题,客户端可以消除直接创建对象的责任,而仅仅是消费产品。简单工厂模式实现了对责任的分割。
- 简单工厂模式也起到了代码复用的作用,因为之前的实现(自己做饭的情况)中,换了一个人同样要去在自己的类中实现做菜的方法,然后有了简单工厂之后,去餐馆吃饭的所有人都不用那么麻烦了,只需要负责消费就可以了。此时简单工厂的烧菜方法就让所有客户共用了。(同时这点也是简单工厂方法的缺点——因为工厂类集中了所有产品创建逻辑,一旦不能正常工作,整个系统都会受到影响,也没什么不好理解的,就如事物都有两面性一样道理)
简单工厂模式的缺点:
- 工厂类集中了所有产品创建逻辑,一旦不能正常工作,整个系统都会受到影响(通俗地意思就是:一旦餐馆没饭或者关门了,很多不愿意做饭的人就没饭吃了)
- 系统扩展困难,一旦添加新产品就不得不修改工厂逻辑,这样就会造成工厂逻辑过于复杂。
简单工厂的应用场景:
- 当工厂类负责创建的对象比较少时可以考虑使用简单工厂模式()
- 采用静态方法实现类的创建,好处是可以减少工厂类本身的创建,但缺点是失去了工厂类进行继承扩展的优点.
- 客户如果只知道传入工厂类的参数,对于如何创建对象的逻辑不关心时可以考虑使用简单工厂模式


/// <summary> /// 顾客充当客户端,负责调用简单工厂来生产对象 /// 即客户点菜,厨师(相当于简单工厂)负责烧菜(生产的对象) /// </summary> class Customer { static void Main(string[] args) { // 客户想点一个西红柿炒蛋 Food food1 = FoodSimpleFactory.CreateFood("西红柿炒蛋"); food1.Print(); // 客户想点一个土豆肉丝 Food food2 = FoodSimpleFactory.CreateFood("土豆肉丝"); food2.Print(); Console.Read(); } } /// <summary> /// 菜抽象类 /// </summary> public abstract class Food { // 输出点了什么菜 public abstract void Print(); } /// <summary> /// 西红柿炒鸡蛋这道菜 /// </summary> public class TomatoScrambledEggs : Food { public override void Print() { Console.WriteLine("一份西红柿炒蛋!"); } } /// <summary> /// 土豆肉丝这道菜 /// </summary> public class ShreddedPorkWithPotatoes : Food { public override void Print() { Console.WriteLine("一份土豆肉丝"); } } /// <summary> /// 简单工厂类, 负责 炒菜 /// </summary> public class FoodSimpleFactory { public static Food CreateFood(string type) { Food food = null; if (type.Equals("土豆肉丝")) { food= new ShreddedPorkWithPotatoes(); } else if (type.Equals("西红柿炒蛋")) { food= new TomatoScrambledEggs(); } return food; } }
2.工厂模式
工厂方法模式之所以可以解决简单工厂的模式,是因为它的实现把具体产品的创建推迟到子类中,此时工厂类不再负责所有产品的创建,而只是给出具体工厂必须实现的接口,这样工厂方法模式就可以允许系统不修改工厂类逻辑的情况下来添加新产品,这样也就克服了简单工厂模式中缺点。
/// <summary> /// 肉末茄子这道菜 /// </summary> public class MincedMeatEggplant : Food { /// <summary> /// 重写抽象类中的方法 /// </summary> public override void Print() { Console.WriteLine("肉末茄子好了"); } } /// <summary> /// 肉末茄子工厂类,负责创建肉末茄子这道菜 /// </summary> public class MincedMeatEggplantFactory : Creator { /// <summary> /// 负责创建肉末茄子这道菜 /// </summary> /// <returns></returns> public override Food CreateFoddFactory() { return new MincedMeatEggplant(); } } /// <summary> /// 客户端调用 /// </summary> class Client { static void Main(string[] args) { // 如果客户又想点肉末茄子了 // 再另外初始化一个肉末茄子工厂 Creator minceMeatEggplantFactor = new MincedMeatEggplantFactory(); // 利用肉末茄子工厂来创建肉末茄子这道菜 Food minceMeatEggplant = minceMeatEggplantFactor.CreateFoddFactory(); minceMeatEggplant.Print(); Console.Read(); } }
3.抽象工厂模式
提供一个创建产品的接口来负责创建相关或依赖的对象,而不具体明确指定具体类抽象工厂允许客户使用抽象的接口来创建一组相关产品,而不需要知道或关心实际生产出的具体产品是什么。这样客户就可以从具体产品中被解耦 扩展起来非常简便
抽象工厂模式很难支持新种类产品的变化。这是因为抽象工厂接口中已经确定了可以被创建的产品集合,如果需要添加新产品,此时就必须去修改抽象工厂的接口,这样就涉及到抽象工厂类的以及所有子类的改变,这样也就违背了“开发——封闭”原则。
知道了抽象工厂的优缺点之后,也就能很好地把握什么情况下考虑使用抽象工厂模式了,下面就具体看看使用抽象工厂模式的系统应该符合那几个前提:
- 一个系统不要求依赖产品类实例如何被创建、组合和表达的表达,这点也是所有工厂模式应用的前提。
- 这个系统有多个系列产品,而系统中只消费其中某一系列产品
- 系统要求提供一个产品类的库,所有产品以同样的接口出现,客户端不需要依赖具体实现。
/// <summary> /// 如果绝味又想开一家湖南的分店时,因为湖南喜欢吃麻的 /// 所以这是有需要有一家湖南的工厂专门制作 /// </summary> public class HuNanFactory : AbstractFactory { // 制作湖南鸭脖 public override YaBo CreateYaBo() { return new HuNanYaBo(); } // 制作湖南鸭架 public override YaJia CreateYaJia() { return new HuNanYajia(); } } /// <summary> /// 湖南的鸭脖 /// </summary> public class HuNanYaBo : YaBo { public override void Print() { Console.WriteLine("湖南的鸭脖"); } } /// <summary> /// 湖南的鸭架 /// </summary> public class HuNanYajia : YaJia { public override void Print() { Console.WriteLine("湖南的鸭架子"); } }
4.策略模式
在下面的情况下可以考虑使用策略模式:
- 一个系统需要动态地在几种算法中选择一种的情况下。那么这些算法可以包装到一个个具体的算法类里面,并为这些具体的算法类提供一个统一的接口。
- 如果一个对象有很多的行为,如果不使用合适的模式,这些行为就只好使用多重的if-else语句来实现,此时,可以使用策略模式,把这些行为转移到相应的具体策略类里面,就可以避免使用难以维护的多重条件选择语句,并体现面向对象涉及的概念。
策略模式的主要优点有:
- 策略类之间可以自由切换。由于策略类都实现同一个接口,所以使它们之间可以自由切换。
- 易于扩展。增加一个新的策略只需要添加一个具体的策略类即可,基本不需要改变原有的代码。
- 避免使用多重条件选择语句,充分体现面向对象设计思想。
策略模式的主要缺点有:
- 客户端必须知道所有的策略类,并自行决定使用哪一个策略类。这点可以考虑使用IOC容器和依赖注入的方式来解决,关于IOC容器和依赖注入(Dependency Inject)的文章可以参考:IoC 容器和Dependency Injection 模式。
- 策略模式会造成很多的策略类。
namespace StrategyPattern { // 所得税计算策略 public interface ITaxStragety { double CalculateTax(double income); } // 个人所得税 public class PersonalTaxStrategy : ITaxStragety { public double CalculateTax(double income) { return income * 0.12; } } // 企业所得税 public class EnterpriseTaxStrategy : ITaxStragety { public double CalculateTax(double income) { return (income - 3500) > 0 ? (income - 3500) * 0.045 : 0.0; } } public class InterestOperation { private ITaxStragety m_strategy; public InterestOperation(ITaxStragety strategy) { this.m_strategy = strategy; } public double GetTax(double income) { return m_strategy.CalculateTax(income); } } class App { static void Main(string[] args) { // 个人所得税方式 InterestOperation operation = new InterestOperation(new PersonalTaxStrategy()); Console.WriteLine("个人支付的税为:{0}", operation.GetTax(5000.00)); // 企业所得税 operation = new InterestOperation(new EnterpriseTaxStrategy()); Console.WriteLine("企业支付的税为:{0}", operation.GetTax(50000.00)); Console.Read(); } } }
5.观察者模式
让多个观察者对象同时监听一个主题对象,这个主题对象发生状态变化时,通知所有观察者对象,使他们自动更新自己,什么是委托,委托就是一种引用方法的一种类型,当为委托分配了方法,委托与方法就有相同的行为了。
在下面的情况下可以考虑使用观察者模式:
- 当一个抽象模型有两个方面,其中一个方面依赖于另一个方面,将这两者封装在独立的对象中以使它们可以各自独立地改变和复用的情况下。从方面的这个词中可以想到,观察者模式肯定在AOP(面向方面编程)中有所体现,更多内容参考:Observern Pattern in AOP.
- 当对一个对象的改变需要同时改变其他对象,而又不知道具体有多少对象有待改变的情况下。
- 当一个对象必须通知其他对象,而又不能假定其他对象是谁的情况下
观察者模式有以下几个优点:
- 观察者模式实现了表示层和数据逻辑层的分离,并定义了稳定的更新消息传递机制,并抽象了更新接口,使得可以有各种各样不同的表示层,即观察者。
- 观察者模式在被观察者和观察者之间建立了一个抽象的耦合,被观察者并不知道任何一个具体的观察者,只是保存着抽象观察者的列表,每个具体观察者都符合一个抽象观察者的接口。
- 观察者模式支持广播通信。被观察者会向所有的注册过的观察者发出通知。
观察者也存在以下一些缺点:
- 如果一个被观察者有很多直接和间接的观察者时,将所有的观察者都通知到会花费很多时间。
- 虽然观察者模式可以随时使观察者知道所观察的对象发送了变化,但是观察者模式没有相应的机制使观察者知道所观察的对象是怎样发生变化的。
- 如果在被观察者之间有循环依赖的话,被观察者会触发它们之间进行循环调用,导致系统崩溃,在使用观察者模式应特别注意这点。
// 订阅号抽象类 public abstract class TenXun { // 保存订阅者列表 private List<IObserver> observers = new List<IObserver>(); public string Symbol { get; set; } public string Info { get; set; } public TenXun(string symbol, string info) { this.Symbol = symbol; this.Info = info; } #region 新增对订阅号列表的维护操作 public void AddObserver(IObserver ob) { observers.Add(ob); } public void RemoveObserver(IObserver ob) { observers.Remove(ob); } #endregion public void Update() { // 遍历订阅者列表进行通知 foreach (IObserver ob in observers) { if (ob != null) { ob.ReceiveAndPrint(this); } } } } // 具体订阅号类 public class TenXunGame : TenXun { public TenXunGame(string symbol, string info) : base(symbol, info) { } } // 订阅者接口 public interface IObserver { void ReceiveAndPrint(TenXun tenxun); } // 具体的订阅者类 public class Subscriber : IObserver { public string Name { get; set; } public Subscriber(string name) { this.Name = name; } public void ReceiveAndPrint(TenXun tenxun) { Console.WriteLine("Notified {0} of {1}'s" + " Info is: {2}", Name, tenxun.Symbol, tenxun.Info); } } // 客户端测试 class Program { static void Main(string[] args) { TenXun tenXun = new TenXunGame("TenXun Game", "Have a new game published ...."); // 添加订阅者 tenXun.AddObserver(new Subscriber("Learning Hard")); tenXun.AddObserver(new Subscriber("Tom")); tenXun.Update(); Console.ReadLine(); } }
6.中介者模式
一般在以下情况下可以考虑使用中介者模式:
- 一组定义良好的对象,现在要进行复杂的相互通信。
- 想通过一个中间类来封装多个类中的行为,而又不想生成太多的子类。
中介者模式具有以下几点优点:
- 简化了对象之间的关系,将系统的各个对象之间的相互关系进行封装,将各个同事类解耦,使得系统变为松耦合。
- 提供系统的灵活性,使得各个同事对象独立而易于复用。
然而,中介者模式也存在对应的缺点:
- 中介者模式中,中介者角色承担了较多的责任,所以一旦这个中介者对象出现了问题,整个系统将会受到重大的影响。例如,QQ游戏中计算欢乐豆的程序出错了,这样会造成重大的影响。
- 新增加一个同事类时,不得不去修改抽象中介者类和具体中介者类,此时可以使用观察者模式和状态模式来解决这个问题。
namespace MediatorPattern { // 抽象牌友类 public abstract class AbstractCardPartner { public int MoneyCount { get; set; } public AbstractCardPartner() { MoneyCount = 0; } public abstract void ChangeCount(int Count, AbstractMediator mediator); } // 牌友A类 public class ParterA : AbstractCardPartner { // 依赖与抽象中介者对象 public override void ChangeCount(int Count, AbstractMediator mediator) { mediator.AWin(Count); } } // 牌友B类 public class ParterB : AbstractCardPartner { // 依赖与抽象中介者对象 public override void ChangeCount(int Count, AbstractMediator mediator) { mediator.BWin(Count); } } // 抽象中介者类 public abstract class AbstractMediator { protected AbstractCardPartner A; protected AbstractCardPartner B; public AbstractMediator(AbstractCardPartner a, AbstractCardPartner b) { A = a; B = b; } public abstract void AWin(int count); public abstract void BWin(int count); } // 具体中介者类 public class MediatorPater : AbstractMediator { public MediatorPater(AbstractCardPartner a, AbstractCardPartner b) : base(a, b) { } public override void AWin(int count) { A.MoneyCount += count; B.MoneyCount -= count; } public override void BWin(int count) { B.MoneyCount += count; A.MoneyCount -= count; } } class Program { static void Main(string[] args) { AbstractCardPartner A = new ParterA(); AbstractCardPartner B = new ParterB(); // 初始钱 A.MoneyCount = 20; B.MoneyCount = 20; AbstractMediator mediator = new MediatorPater(A, B); // A赢了 A.ChangeCount(5, mediator); Console.WriteLine("A 现在的钱是:{0}", A.MoneyCount);// 应该是25 Console.WriteLine("B 现在的钱是:{0}", B.MoneyCount); // 应该是15 // B 赢了 B.ChangeCount(10, mediator); Console.WriteLine("A 现在的钱是:{0}", A.MoneyCount);// 应该是15 Console.WriteLine("B 现在的钱是:{0}", B.MoneyCount); // 应该是25 Console.Read(); } } }
二. 并发编程 (异步编程与多线程)
并发:同时做多件事情
多线程:并发的一种形式,它采用多个线程来执行程序。
并行处理:把正在执行的大量的任务分割成小块,分配给多个同时运行的线程。并行处理是多线程的一种,而多线程是并发的一种。
异步编程:并发的一种形式,它采用 future 模式或回调(callback)机制,以避免产生不必要的 线程,异步编程的核心理念是异步操作:启动了的操作将会在一段时间后完成。这个操作 正在执行时,不会阻塞原来的线程。启动了这个操作的线程,可以继续执行其他任务。当 操作完成时,会通知它的 future,或者调用回调函数,以便让程序知道操作已经结束,
async 和 await:这让异步编程变得几乎和同步(非并发)编程一样容易。await的作用:启动一个将会被执行的Task(该Task将会在新线程中执行),并立即返回,所以await所在的函数不会被阻塞,当Task完成后,继续执行await后面的代码。
通常情况下,一个并发程序要使用多种技术。大多数程序至少使用了多线程(通过线程 池)和异步编程
异步编程有两大好处。第一个好处是对于面向终端用户的 GUI 程序:异步编程提高了响应 能力。我们都遇到过在运行时会临时锁定界面的程序,异步编程可以使程序在执行任务时 仍能响应用户的输入。第二个好处是对于服务器端应用:异步编程实现了可扩展性。服务 器应用可以利用线程池满足其可扩展性,使用异步编程后,可扩展性通常可以提高一个数 量级。
现代的异步 .NET 程序使用两个关键字:async 和 await。async 关键字加在方法声明上, 它的主要目的是使方法内的 await 关键字生效(为了保持向后兼容,同时引入了这两个关 键字)。如果 async 方法有返回值,应返回 Task<T>;如果没有返回值,应返回 Task。这些 task 类型相当于 future,用来在异步方法结束时通知主程序。
不要用 void 作为 async 方法的返回类型! async 方法可以返回 void,但是这 仅限于编写事件处理程序。一个普通的 async 方法如果没有返回值,要返回 Task,而不是 void。

和其他方法一样,async 方法在开始时以同步方式执行。在 async 方法内部,await 关键字 对它的参数执行一个异步等待。它首先检查操作是否已经完成,如果完成了,就继续运行 (同步方式)。否则,它会暂停 async 方法,并返回,留下一个未完成的 task。一段时间后, 操作完成,async 方法就恢复运行。 不会阻塞UI线程 ,await方法完成自动的通知他 然后执行剩余的代码,异步是为了程序本身不卡 调用处还是异步的 调用处下面的代码还是会先执行 await实际上只是把主线程释放了,使用了其他线程代替他继续 异步不是为了让请求更快,而是为了可以处理更多请求
异步有一个核心,是Task。而Task有一个方法,就是Wait,写法是Task.Wait()。所以,很多人把这个Wait和await混为一谈,这是错的。
这个问题来自于Task。C#里,Task不是专为异步准备的,它表达的是一个线程,是工作在线程池里的一个线程。异步是线程的一种应用,多线程也是线程的一种应用。Wait,以及Status、IsCanceled、IsCompleted、IsFaulted等等,是给多线程准备的方法,跟异步没有半毛钱关系。当然你非要在异步中使用多线程的Wait或其它,从代码编译层面不会出错,但程序会。
尤其,Task.Wait()是一个同步方法,用于多线程中阻塞等待。
用Task.Wait()来实现同步方法中调用异步方法,这个用法本身就是错误的。 异步不是多线程,而且在多线程中,多个Task.Wait()使用也会死锁,也有解决和避免死锁的一整套方式。
Task.Wait()是一个同步方法,用于多线程中阻塞等待,不是实现同步方法中调用异步方法的实现方式。
在异步中,await表达的意思是:当前线程/方法中,await引导的方法出结果前,跳出当前线程/方法,从调用当前线程/方法的位置,去执行其它可能执行的线程/方法,并在引导的方法出结果后,把运行点拉回到当前位置继续执行;直到遇到下一个await,或线程/方法完成返回,跳回去刚才外部最后执行的位置继续执行。
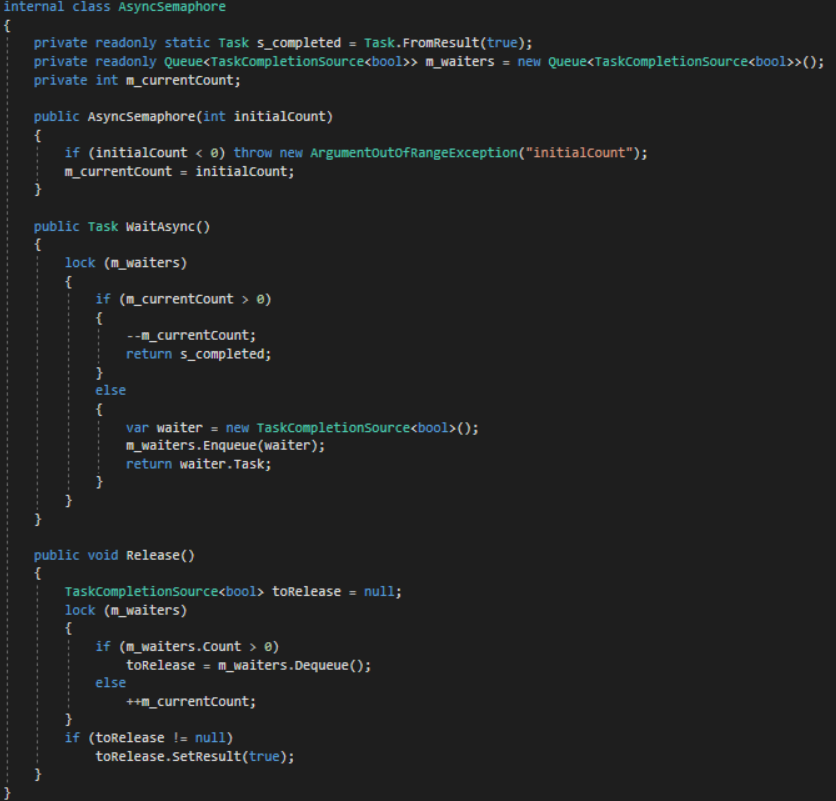
1.异步锁
从 .NET Framework 4.5 开始,任何使用 async/await 进行修饰的方法,都会被认为是一个异步方法;实际上,这些异步方法都是基于队列的线程任务,从你开始使用 Task 去运行一段代码的时候,实际上就相当于开启了一个线程,默认情况下,这个线程数由线程池 ThreadPool 进行管理的。
线程安全的访问方式可以通过lock来进行唯一线程限定,但如果使用await等待Task完成,则Task中不允许使用lock。
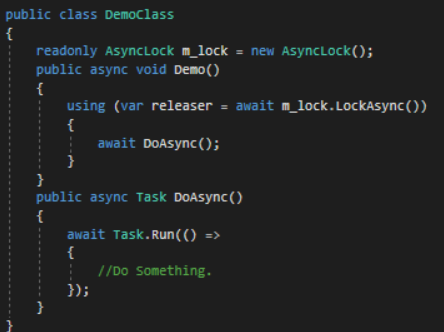
因此采用另外一种方式完成

调用方法
2.线程 多线程 Task
线程:
Thread,由CLR提供,可以提供细粒度的线程控制,但是在返回值、多个线程并行/串行时候显得功能不足,需要进一步封装才行,而且线程的开启、停止都需要时间开销,乱用的话还造成浪费。
线程池:
ThreadPool,由CLR提供,提供粗粒度的线程控制,主要用来执行短时间内执行的代码片段,一个进程有一个线程池,由CLR统一调度。它对线程的控制力较少,而且在返回值、多个线程并行/串行时候显也是功能不足。
任务:
Task.Run(()=>{})相当于 Task.Factory.StartNew
Task,对ThreadPool和Thread的包装,可以根据任务时间长短选择使用线程池还是新的线程,通过进一步扩展,增加了返回值、多个线程并行/串行等功能。它的核心是一个调度器,默认是ThreadPoolTaskScheduler。Task使用的是异步操作一个线程池线程
ThreadPool是Thread基础上的一个线程池,目的是减少频繁创建线程的开销。线程很贵,要开新的stack,要增加CPU上下文切换,所以ThreadPool适合频繁、短期执行的小操作。调度算法是自适应的,会根据程序执行的模式调整配置,通常不需要自己调度线程。另外分为Worker和IO两个池。IO线程对应Native的overlapped io,Win下利用IO完成端口实现非阻塞IO。
Task或者说TPL是一个更上层的封装,NB之处在于continuation。continuation的意义在于:高性能的程序通常都是跑在IO边界或者UI事件的边界上的,TPL的continuation可以更方便的写这种高scalability的代码。Task会根据一些flag,比如是不是long-running来决定底层用Thread还是ThreadPool,另外也做了些细节优化,比如同一个线程跑好几个Task,比如continuation时根据情况让CPU空转几毫秒来等待前置Task结束,都是为了减少CPU上下文切换。
结论:能用Task就用Task,底下都是用的Thread或者ThreadPool。但是要注意细节,比如告诉Task是不是long-running;比如尽量别Wait;再比如IO之后的continuation要尽快结束然后把线程还回去,有事开个Worker做,要不然会影响后面的IO,等等。
Task的使用
/// <summary> /// 最简单的使用方式 /// </summary> /// <returns></returns> [HttpGet] [Route("GetTask")] public IActionResult GetTask() { Console.ForegroundColor = ConsoleColor.Red; // 执行一个无返回值的任务 Task.Run(() => { Console.WriteLine("runing ..."); }); // 执行一个返回 int 类型结果的任务 var res1 = Task.Run<int>(() => { return 483; }); // 声明一个任务,仅声明,不执行 Task t = new Task(() => { Console.WriteLine("声明"); }); Console.ResetColor(); return Ok("test"); } /// <summary> /// 使用 TaskFactory 工厂开始异步任务 ///使用 TaskFactory 创建并运行了两个异步任务,同时把这两个任务加入了任务列表 tasks 中 ///然后立即迭代此 tasks 获取异步任务的执行结果,使用 TaskFactory 工厂类,可以创建一组人物,然后依次执行它们 /// </summary> /// <returns></returns> [HttpGet] [Route("GetTask2")] public IActionResult GetTask2() { Console.ForegroundColor = ConsoleColor.Red; List<Task<int>> tasks = new List<Task<int>>(); TaskFactory factory = new TaskFactory(); tasks.Add(factory.StartNew<int>(() => { Console.WriteLine("t1"); return 1; })); tasks.Add(factory.StartNew<int>(() => { Console.WriteLine("t2"); return 2; })); tasks.Add(factory.StartNew<int>(() => { Console.WriteLine("t3"); return 3; })); tasks.ForEach(t => Console.WriteLine("Task:{0}", t.Result)); Console.ResetColor(); return Ok("test2"); } /// <summary> /// 处理 Task 中的异常 ///异步任务中发生异常会导致任务抛出 TaskCancelException 的异常,仅表示任务退出,程序应当捕获该异常;然后,立即调用 Task 进行状态判断,获取内部异常 上面的代码模拟了 Task 内部发生的异常,并捕获了异常 ///通常情况下,推荐使用 Task 的任务状态判断以进行下一步的任务处理(如果需要),如果仅仅是简单的执行一个异步任务,直接捕获异常即可,这里使用了状态判断,如果任务已完成,则打印一则消息:IsCompleted;很明显,在上面的代码中,此 “IsCompleted” 消息并不会被打印到控制台 ///注意,这里使用了 task.IsCompletedSuccessfully 而不是 task.IsCompleted,这两者的区别在于,前者只有在任务正常执行完成,无异常,无中途退出指令的情况下才会表示已完成,而 task.IsCompleted 则仅仅表示“任务完成” /// </summary> /// <returns></returns> [HttpGet] [Route("GetTask3")] public IActionResult GetTask3() { Console.ForegroundColor = ConsoleColor.Red; var task = Task.Run(() => { Console.WriteLine("SimpleTask"); Task.Delay(1000).Wait(); throw new Exception("SimpleTask Error"); }); try { task.Wait(); } catch (Exception ex) { Console.WriteLine(ex.Message); } if (task.IsCompletedSuccessfully)//任务成功 { Console.WriteLine("IsCompletedSuccessfully"); } if (task.IsCompleted)//任务完成 { Console.WriteLine("IsCompleted"); } Console.ResetColor(); return Ok("test2"); }
线程的使用
Thread t = new Thread(()=> { Console.WriteLine("Starting..."); for (int i = 0; i < 10; i++) { Console.WriteLine(i); } }); t.Start(); static void Main(string[] args) { int b = 10; string c = "主线程"; Thread t = new Thread(()=> PrintNumbers(b,c)); t.Start(); } static void PrintNumbers(int count,string name) { for (int i = 0; i < count; i++) { Console.WriteLine("name:{0},i:{1}",name,i); } }
线程池的使用
class Program { static void Main(string[] args) { WaitCallback wc1 = s =>{ Console.WriteLine("线程ID:{0},开始执行", Thread.CurrentThread.ManagedThreadId); Stopwatch stw = new Stopwatch(); stw.Start(); long result = SumNumbers(10000000); stw.Stop(); Console.WriteLine("线程ID:{0},执行完成,执行结果:{1},执行用时{2},",Thread.CurrentThread.ManagedThreadId,result,stw.ElapsedMilliseconds); }; WaitCallback wc2 = s => { Console.WriteLine("线程ID:{0},开始执行", Thread.CurrentThread.ManagedThreadId); Stopwatch stw = new Stopwatch(); stw.Start(); long result = SumNumbers(10000000); stw.Stop(); Console.WriteLine("线程ID:{0},执行完成,执行结果:{1},执行用时{2},", Thread.CurrentThread.ManagedThreadId, result, stw.ElapsedMilliseconds); }; WaitCallback wc3 = s => { Console.WriteLine("线程ID:{0},开始执行", Thread.CurrentThread.ManagedThreadId); Stopwatch stw = new Stopwatch(); stw.Start(); long result = SumNumbers(10000000); stw.Stop(); Console.WriteLine("线程ID:{0},执行完成,执行结果:{1},执行用时{2},", Thread.CurrentThread.ManagedThreadId, result, stw.ElapsedMilliseconds); }; ThreadPool.QueueUserWorkItem(wc1); ThreadPool.QueueUserWorkItem(wc2); ThreadPool.QueueUserWorkItem(wc3); Console.ReadKey(); } static long SumNumbers(int count) { long sum = 0; for (int i = 0; i < count; i++) { sum += i; } Thread.Sleep(1000); return sum; } } //等待线程池的线程执行 class Program { static void Main(string[] args) { using (ManualResetEvent m1 = new ManualResetEvent(false)) using (ManualResetEvent m2 = new ManualResetEvent(false)) using (ManualResetEvent m3 = new ManualResetEvent(false)) { ThreadPool.QueueUserWorkItem( s =>{ Console.WriteLine("线程ID:{0},开始执行", Thread.CurrentThread.ManagedThreadId); Stopwatch stw = new Stopwatch(); stw.Start(); long result = SumNumbers(10000000); stw.Stop(); m1.Set(); Console.WriteLine("线程ID:{0},执行完成,执行结果:{1},执行用时{2},", Thread.CurrentThread.ManagedThreadId, result, stw.ElapsedMilliseconds); }); ThreadPool.QueueUserWorkItem( s =>{ Console.WriteLine("线程ID:{0},开始执行", Thread.CurrentThread.ManagedThreadId); Stopwatch stw = new Stopwatch(); stw.Start(); long result = SumNumbers(10000000); stw.Stop(); m2.Set(); Console.WriteLine("线程ID:{0},执行完成,执行结果:{1},执行用时{2},", Thread.CurrentThread.ManagedThreadId, result, stw.ElapsedMilliseconds); }); ThreadPool.QueueUserWorkItem( s =>{ Console.WriteLine("线程ID:{0},开始执行", Thread.CurrentThread.ManagedThreadId); Stopwatch stw = new Stopwatch(); stw.Start(); long result = SumNumbers(10000000); stw.Stop(); m3.Set(); Console.WriteLine("线程ID:{0},执行完成,执行结果:{1},执行用时{2},", Thread.CurrentThread.ManagedThreadId, result, stw.ElapsedMilliseconds); }); //等待线程池的线程执行 m1.WaitOne(); m2.WaitOne(); m3.WaitOne(); Console.WriteLine("所有线程执行完成"); } Console.ReadKey(); } static long SumNumbers(int count) { long sum = 0; for (int i = 0; i < count; i++) { sum += i; } Thread.Sleep(3000); return sum; } }
三.集合
System.Collenctions和System.Collenctions.Generic 中提供了很多列表、集合和数组。例如:List<T>集合,数组Int[],String[] ......,Dictory<T,T>字典等等。但是这些列表、集合和数组的线程都不是安全的,不能接受并发请求。
1.数组
优点:数组在内存中是连续存储的、所以它的索引速度是非常快的、时间复杂度为O(1)、而且它的赋值/修改/获取元素也是非常简单的。
缺点:1、定义数组的时候需要指定数组的长度(过长会造成内存浪费、过短会导致程序异常System.IndexOutOfRangeException:"索引超出数组界限")
2、插入和删除元素效率低、也比较麻烦。
在不清楚数组长度的时候、就很尴尬了。 所以C#提供了ArrayList了来处理这些问题...
2.arrayList
优点:1、ArrayList大小会根据需要动态增加的数组。
2、实现了IList接口、可以方便的对数据进行添加、插入和删除。
缺点:1、ArrayList会把插入的数据都当做object类型来存储、在操作数据的时候可能会因为类型不匹配而出现异常、它是非类型安全的对象。
2、由于存储的是object类型、在使用的时候进行类型转换、会造成装箱拆箱、从而损耗性能。
装箱:把值类型转换成引用类型;
拆箱:把引用类型转换成值类型。
3.List<T>
优点:由于泛型List是强类型、编译器会验证类型安全。这样就避免了类型的不安全、以及数据强制转换导致装箱拆箱损耗性能。
自C#2.0以来,LOCK是一直存在的。使用LOCK(互斥锁)是可以做到防止并发的,示例代码如下:
class Program { private static object o = new object(); private static List<Product> _Products { get; set; } /* coder:天才卧龙 * 代码中 创建三个并发线程 来操作_Products 集合 * System.Collections.Generic.List 这个列表在多个线程访问下,不能保证是安全的线程,所以不能接受并发的请求,我们必须对ADD方法的执行进行串行化 */ static void Main(string[] args) { _Products = new List<Product>(); /*创建任务 t1 t1 执行 数据集合添加操作*/ Task t1 = Task.Factory.StartNew(() => { AddProducts(); }); /*创建任务 t2 t2 执行 数据集合添加操作*/ Task t2 = Task.Factory.StartNew(() => { AddProducts(); }); /*创建任务 t3 t3 执行 数据集合添加操作*/ Task t3 = Task.Factory.StartNew(() => { AddProducts(); }); Task.WaitAll(t1, t2, t3); Console.WriteLine(_Products.Count); Console.ReadLine(); } /*执行集合数据添加操作*/ static void AddProducts() { Parallel.For(0, 1000, (i) => { lock (o) { Product product = new Product(); product.Name = "name" + i; product.Category = "Category" + i; product.SellPrice = i; _Products.Add(product); } }); } } class Product { public string Name { get; set; } public string Category { get; set; } public int SellPrice { get; set; } }
锁的引入,带来了一定的开销和性能的损耗,并降低了程序的扩展性,而且还会有死锁的发生(虽说概率不大,但也不能不防啊),因此:使用LOCK进行并发编程显然不太适用。
四.锁与死锁
锁的引入,带来了一定的开销和性能的损耗,并降低了程序的扩展性,而且还会有死锁的发生(虽说概率不大,但也不能不防啊),因此:使用LOCK进行并发编程显然不太适用。
还好,微软一直在更新自己的东西:
.NET Framework 4提供了新的线程安全和扩展的并发集合,它们能够解决潜在的死锁问题和竞争条件问题,因此在很多复杂的情形下它们能够使得并行代码更容易编写,这些集合尽可能减少使用锁的次数,从而使得在大部分情形下能够优化为最佳性能,不会产生不必要的同步开销。
ConcurrentQueue 队列
ConcurrentQueue 是完全无锁的,能够支持并发的添加元素,先进先出。下面贴代码,详解见注释:
class Program { private static object o = new object(); /*定义 Queue*/ private static Queue<Product> _Products { get; set; } private static ConcurrentQueue<Product> _ConcurrenProducts { get; set; } /* coder:天才卧龙 * 代码中 创建三个并发线程 来操作_Products 和 _ConcurrenProducts 集合,每次添加 10000 条数据 查看 一般队列Queue 和 多线程安全下的队列ConcurrentQueue 执行情况 */ static void Main(string[] args) { Thread.Sleep(1000); _Products = new Queue<Product>(); Stopwatch swTask = new Stopwatch();//用于统计时间消耗的 swTask.Start(); /*创建任务 t1 t1 执行 数据集合添加操作*/ Task t1 = Task.Factory.StartNew(() => { AddProducts(); }); /*创建任务 t2 t2 执行 数据集合添加操作*/ Task t2 = Task.Factory.StartNew(() => { AddProducts(); }); /*创建任务 t3 t3 执行 数据集合添加操作*/ Task t3 = Task.Factory.StartNew(() => { AddProducts(); }); Task.WaitAll(t1, t2, t3); swTask.Stop(); Console.WriteLine("List<Product> 当前数据量为:" + _Products.Count); Console.WriteLine("List<Product> 执行时间为:" + swTask.ElapsedMilliseconds); Thread.Sleep(1000); _ConcurrenProducts = new ConcurrentQueue<Product>(); Stopwatch swTask1 = new Stopwatch(); swTask1.Start(); /*创建任务 tk1 tk1 执行 数据集合添加操作*/ Task tk1 = Task.Factory.StartNew(() => { AddConcurrenProducts(); }); /*创建任务 tk2 tk2 执行 数据集合添加操作*/ Task tk2 = Task.Factory.StartNew(() => { AddConcurrenProducts(); }); /*创建任务 tk3 tk3 执行 数据集合添加操作*/ Task tk3 = Task.Factory.StartNew(() => { AddConcurrenProducts(); }); Task.WaitAll(tk1, tk2, tk3); swTask1.Stop(); Console.WriteLine("ConcurrentQueue<Product> 当前数据量为:" + _ConcurrenProducts.Count); Console.WriteLine("ConcurrentQueue<Product> 执行时间为:" + swTask1.ElapsedMilliseconds); Console.ReadLine(); } /*执行集合数据添加操作*/ /*执行集合数据添加操作*/ static void AddProducts() { Parallel.For(0, 30000, (i) => { Product product = new Product(); product.Name = "name" + i; product.Category = "Category" + i; product.SellPrice = i; lock (o) { _Products.Enqueue(product); } }); } /*执行集合数据添加操作*/ static void AddConcurrenProducts() { Parallel.For(0, 30000, (i) => { Product product = new Product(); product.Name = "name" + i; product.Category = "Category" + i; product.SellPrice = i; _ConcurrenProducts.Enqueue(product); }); } } class Product { public string Name { get; set; } public string Category { get; set; } public int SellPrice { get; set; } }
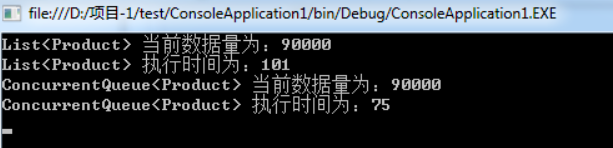
从执行时间上来看,使用 ConcurrentQueue 相比 LOCK 明显快了很多!
1.BlockingCollection 与经典的阻塞队列数据结构类似,能够适用于多个任务添加和删除数据,提供阻塞和限界能力。
2.ConcurrentBag 提供对象的线程安全的无序集合
3.ConcurrentDictionary 提供可有多个线程同时访问的键值对的线程安全集合
4.ConcurrentQueue 提供线程安全的先进先出集合
5.ConcurrentStack 提供线程安全的后进先出集合
1.死锁的产生
当两个( 最小二) 线程试图获取已经被另一个锁锁定的资源的锁时,就会发生死锁。 线程 1锁定资源 1尝试获取对资源 2的锁定。 同时,线程 2对资源 2有一个锁,它尝试获取对资源 1的锁。 两个线程永远不会放弃锁,因此发生死锁。
避免死锁的最简单方法是使用超时值。 Monitor类( system.threading.monitor ) 可以在获取锁期间设置超时。
if(Monitor.TryEnter(this, 500)) { //critical section } catch (Exception ex) { } finally { Monitor.Exit(); }
比如方法一中先lock(object1),在lock(object1)中lock(object2)。
方法二种则相反。
那么这时候可以看出,如果方法一中lock了object1,这时候请求object2。
方法二种lock了object2,这时候请求object1,那么这时候就出现问题了。
static void Main(string[] args) { object lock1 = new object(); object lock2 = new object(); new Thread(() => LockTooMuch(lock1, lock2)).Start(); lock (lock2) { Thread.Sleep(1000); Console.WriteLine("try to get lock1"); if (Monitor.TryEnter(lock1, TimeSpan.FromSeconds(5))) { Console.WriteLine("Acquired a protected resource succesfully"); } else { Console.WriteLine("Time out a resource"); } } Console.Read(); } static void LockTooMuch(object lock1, object lock2) { lock (lock1) { Thread.Sleep(1000); lock (lock2) { Console.WriteLine("enter lock2"); }; } }
主线程获取lock2,然后分支线程获取lock1,然后请求lock2。
这时候就堵塞了,可以拿上面代码运行一下,会堵塞5秒。
这个5秒怎么来的呢?if (Monitor.TryEnter(lock1, TimeSpan.FromSeconds(5))) 这时候是尝试去获取lock1,
因为lock1倍分支线程给获取了,那么获取不到,这时候等待5秒,5秒后获取不到就直接走了lese这条路,然后就释放了lock2,这时候分支线程就继续运行。