仓储(Repository)模式自2004年首次作为领域驱动模型DDD设计的一部分引入,仓储本质上是提供提供数据的抽象,以便应用程序可以使用具有接口的相似的简单抽象集合。从此集合中CURD是通过一些列直接的方法完成,无需处理连接、命令等问题,使用此种模式可帮助实现松耦合,并保持领域对象的持久性无知。
- 仓储模式是为了在程序的数据访问层和业务逻辑层之间创建的一个抽象层
- 仓储模式是一种数据访问模式,提供一种更松散耦合的数据访问方法
- 将创建数据访问的逻辑写在单独的类中即仓储
- 仓储负责和业务层进行持久化通信
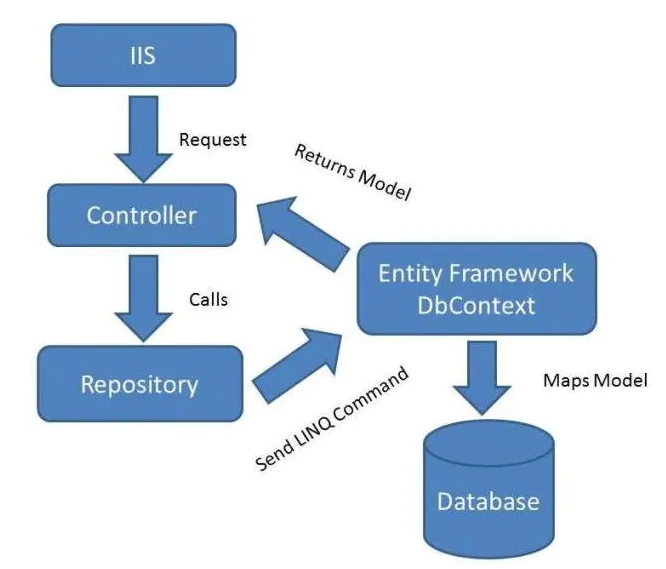
仓储(Repository)是存在于工作单元和数据库之间单独分离出来的一层,是对数据访问的封装。其优点是
- 业务层无需知道具体实现达到分离关注点
- 提高对数据库访问的维护,对于仓储的改变并不改变业务的逻辑。
首先为什么需要工厂Factory,因为有了聚合的概念,很多时候我们需要创建Aggregate整个聚合,创建过程很复杂,如果我们把这个创建职责分配给聚合里面的任何一个Entity来说都是不合适的,一个是暴露了聚合内部的结构破坏了边界,一个是聚合内的实体承担了本身不应该自己承担的职责。
因此应该将创建复杂对象的实例和聚合的职责转移给一个单独的对象,这个对象本身在领域模型中可能没有职责,但是它仍然是领域模型的一部分。提供一个封装所有复杂装配操作的接口,而且这个接口应该不需要客户引用要被实例化的对象的具体类。在创建Aggregate的时候要把它作为一个整体,并确保它满足固定规则。
而设计模式里面的工厂模式,则强调的是工厂提供一个公共的接口,可以根据我们的需求灵活的返回不同的实现该接口的对象实例。对象的创建和实例化由工厂来完成,而不是简单的由对象的构造函数完成。而实际领域模型里面的Factory往往并没有这么复杂,仅仅是接管复杂聚合对象的创建和实例化而已。因此对于简单的Entity,或者本身不存在聚合的时候是不需要再加上Factory类的。
对于仓储Repository需要说明两个方面的内容。一个是解决持久化的问题,一个是对数据层做屏蔽,避免应用或展现层直接跳过领域层对数据库进行操作而使领域模型最终无用。在有了Repository后,我们不再关心对象的存储和访问操作,而将重心真正转移到领域模型本身。或者叫使应用程序和领域设计与持久化技术解耦。
对于工厂和仓储的关系,工厂负责对象生命周期的开始,而仓储负责对象生命周期的中间或结束。当对象驻留在内存或对象数据库的时候很好理解。但是至少有一部分数据会持久化存在到类似关系型数据库或文件中,这样检索出来的数据就必须重建为对象形式。
对于工厂和仓储的协同,有些理解和书上有些不一致。个人理解工厂不仅仅应该关注复杂对象的创建,同时也应该关注复杂对象的保存。工厂不负责对象的持久化,工厂将持久化职责委托到仓储来完成。仓储不应该直接和应用层打交道,对于整个领域层来说。和应用层打交道的是Service接口,而和持久化层打交道的是Repository接口而已。和书里面理解最大的差异就是Repository没有保留给Client,也不是Repository委托Factory来重建对象。
举一个场景来说,根据订单号获取一个聚合复杂对象采购订单,对采购订单进行修改后再进行保存。这个时候和持久化层存在两次交互,第一次是数据的读取,第二次是修改后数据的存入。
对于数据读取,到领域层则是Factory需要实例化一个聚合对象并返回应用层。而Factory将该工作分解到聚合里美的每一个子实体,子实体通过Repository接口获取到ResultSet并进行OR转换后返回,Factory将拿到的所有实例化对象进行聚合返回一个完整的聚合对象实例。对于数据存储,仍然应该是Factory接管该操作,然后对数据进行分解后分别调用聚合中的每一个实体的仓储接口本身的保存方法,对数据进行持久化,在Factory层进行完整的事务控制并返回结果。
因此应该将创建复杂对象的实例和聚合的职责转移给一个单独的对象,这个对象本身在领域模型中可能没有职责,但是它仍然是领域模型的一部分。提供一个封装所有复杂装配操作的接口,而且这个接口应该不需要客户引用要被实例化的对象的具体类。在创建Aggregate的时候要把它作为一个整体,并确保它满足固定规则。
而设计模式里面的工厂模式,则强调的是工厂提供一个公共的接口,可以根据我们的需求灵活的返回不同的实现该接口的对象实例。对象的创建和实例化由工厂来完成,而不是简单的由对象的构造函数完成。而实际领域模型里面的Factory往往并没有这么复杂,仅仅是接管复杂聚合对象的创建和实例化而已。因此对于简单的Entity,或者本身不存在聚合的时候是不需要再加上Factory类的。
对于仓储Repository需要说明两个方面的内容。一个是解决持久化的问题,一个是对数据层做屏蔽,避免应用或展现层直接跳过领域层对数据库进行操作而使领域模型最终无用。在有了Repository后,我们不再关心对象的存储和访问操作,而将重心真正转移到领域模型本身。或者叫使应用程序和领域设计与持久化技术解耦。
对于工厂和仓储的关系,工厂负责对象生命周期的开始,而仓储负责对象生命周期的中间或结束。当对象驻留在内存或对象数据库的时候很好理解。但是至少有一部分数据会持久化存在到类似关系型数据库或文件中,这样检索出来的数据就必须重建为对象形式。
对于工厂和仓储的协同,有些理解和书上有些不一致。个人理解工厂不仅仅应该关注复杂对象的创建,同时也应该关注复杂对象的保存。工厂不负责对象的持久化,工厂将持久化职责委托到仓储来完成。仓储不应该直接和应用层打交道,对于整个领域层来说。和应用层打交道的是Service接口,而和持久化层打交道的是Repository接口而已。和书里面理解最大的差异就是Repository没有保留给Client,也不是Repository委托Factory来重建对象。
举一个场景来说,根据订单号获取一个聚合复杂对象采购订单,对采购订单进行修改后再进行保存。这个时候和持久化层存在两次交互,第一次是数据的读取,第二次是修改后数据的存入。
对于数据读取,到领域层则是Factory需要实例化一个聚合对象并返回应用层。而Factory将该工作分解到聚合里美的每一个子实体,子实体通过Repository接口获取到ResultSet并进行OR转换后返回,Factory将拿到的所有实例化对象进行聚合返回一个完整的聚合对象实例。对于数据存储,仍然应该是Factory接管该操作,然后对数据进行分解后分别调用聚合中的每一个实体的仓储接口本身的保存方法,对数据进行持久化,在Factory层进行完整的事务控制并返回结果。