linux 三剑客 之 sed
# sed 是什么? # sed : 字符流编辑器 Stream Editor; sed 擅长 替换、取行等 # sed 的功能与版本: 处理纯文本文件、日志、配置文件等 增加、删除、修改、查询 sed --version # 查看 sed 版本 # sed 语法格式: sed [选项] [sed指令] [输入文件] sed -i.bak 's#oldboy#oldgirl#g' oldboy.txt # -i --- sed命令的参数 ;sed --- sed命令,一个指令 ;g --- 小尾巴, 修饰
sed 命令的执行流程
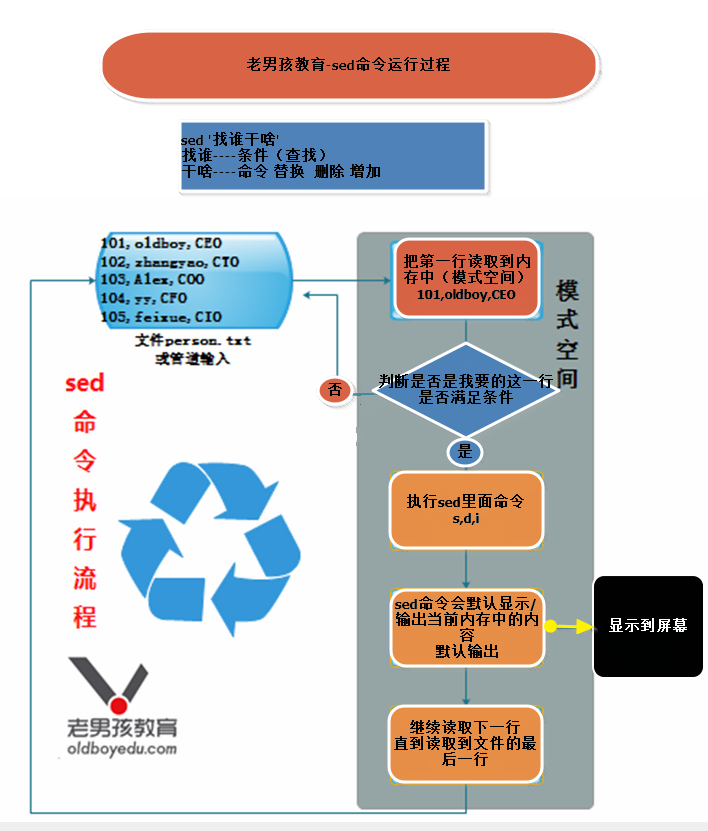
模式空间: sed 从文件读取一行文件后存入的缓冲区 (这个缓冲区是在内存中的)
sed 常用功能:
1. 查询 2. 增加 3. 删除 4. 替换 5. 拓展
1. sed 常用功能之显示 p (print)
# 创建测试环境: cat>person.txt<<EOF 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO EOF # cat>...<<EOF...EOF 表示创建文件 ; cat>>...<<EOF...EOF 表示向文件中追加内容 [root@NEO oldboy]# cat person.txt 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO [root@NEO oldboy]# # 1.1 显示某一行 [root@NEO oldboy]# sed -n '3p' person.txt # -n 表示 取消默认输出; '3p' 表示显示第3行 103,Alex,COO # 1.2 显示连续多行文本 # 显示第2行到第4行的内容,包含第2行和第4行 [root@NEO oldboy]# sed -n '2,4p' person.txt # '2,4p' 表示显示从第2行到第4行 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO # 1.3 显示包含 oldboy 的行到 包含104的行 [root@NEO oldboy]# sed -n '/oldboy/p' person.txt # '/oldboy/p' ---> 表示 包含 oldboy 的行 ;此时 该行命令 相当于 grep 'oldboy',但 grep 不能过滤范围 101,oldboy,CEO [root@NEO oldboy]# sed -n '/oldboy/,/104/p' person.txt # '/oldboy/,/104/p' ---> 包含 oldboy 的行 到 包含 104 的行 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO [root@NEO oldboy]# sed -n '/oldboy/,/^104/p' person.txt # '/oldboy/,/^104/p' ---> 表示从包含 oldboy 的行到 以104开头的行 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO # 1.4 过滤多个字符串 # 默认情况下,sed只支持基本正则表达式;sed 的 -r 参数,可以支持 扩展正则表达式 (| 和 ()) # 显示包含 oldboy 的行 或者 yy 的行 [root@NEO oldboy]# egrep 'oldboy|yy' person.txt 101,oldboy,CEO 104,yy,CFO [root@NEO oldboy]# sed -rn '/oldboy|yy/p' person.txt # -r '/oldboy|yy/p' ---> 表示 包含 oldboy 或者 yy 的行 101,oldboy,CEO 104,yy,CFO # sed 命令通过正则表达式进行过滤时,相当于 egrep # 1.5 查询指定多行 [root@NEO oldboy]# sed -n '1p;3p' person.txt # '1p;3p' ---> 第1行 和 第3行; 多行之间用 逗号 分隔 101,oldboy,CEO 103,Alex,COO [root@NEO oldboy]# sed -n '1p;2,4p;5p' person.txt # , 和 ; 搭配使用 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO [root@NEO oldboy]# sed -n '/oldboy/p;3,5p' person.txt 101,oldboy,CEO 103,Alex,COO 104,yy,CFO 105,feixue,CIO
2. sed 常用功能之增加
# 2.1 单行增加: # 在第3行后面增加一行内容 [root@NEO oldboy]# cat person.txt 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO [root@NEO oldboy]# sed '3a 103.5,Lee,UFO' person.txt # 3a 表示在第3行的后面增加一行内容,3a 后面的空格没有用,也可以不写 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 103.5,Lee,UFO 104,yy,CFO 105,feixue,CIO[root@NEO oldboy]# cat person.txt # sed '3a ' 命令并没有真正修改文件内容,如果想要真正修改文件内容,可以用 sed 的 -i 参数 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO [root@NEO oldboy]# sed '3i 103.5,Lee,UFO' person.txt # 3i 表示在第3行的前面再增加一行内容;同理, 该命令也没有真正修改文件内容,想要真正修改文件内容也是加上 -i 参数 101,oldboy,CEO 102,zhangyao,CTO 103.5,Lee,UFO 103,Alex,COO 104,yy,CFO 105,feixue,CIO # 增加单选文本: a 参数 :追加 append,在指定行后添加一行或多行文本 i 参数 :插入 insert,在指定行前添加一行或多行文本 # 在最后一行插入: [root@NEO oldboy]# sed -n '$p' person.txt # 在 sed 命令中, $ 表示最后一行 105,feixue,CIO [root@NEO oldboy]# sed '$a 103.5,Lee,UFO' person.txt # 在最后一行插入一行内容 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO 103.5,Lee,UFO [root@NEO oldboy]# sed '$a new,new,new old,old,old' person.txt # 在最后一行增加多行内容,用 分隔 (这种方法不常用;此命令已被 cat>>...<<EOF...EOF 替代,而且在最后一行的多行追加一般用 cat>> 方法) 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO new,new,new old,old,old
3. sed 常用功能之删除
# 去除空行实战:删除最后一行 [root@NEO oldboy]# cat person.txt 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO [root@NEO oldboy]# sed '$d' person.txt # 删除最后一行 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO [root@NEO oldboy]# sed '1,3d' person.txt # 删除第1行到第3行; d 表示 delete 104,yy,CFO 105,feixue,CIO # 企业案例:不显示文件中空行 [root@NEO oldboy]# vim person.txt [root@NEO oldboy]# cat -nA person.txt # cat 的 -n 参数表示显示 行号, -A 表示 显示结尾的 $ 1 101,oldboy,CEO$ 2 102,zhangyao,CTO$ 3 $ 4 103,Alex,COO$ 5 $ 6 104,yy,CFO$ 7 $ 8 105,feixue,CIO$ [root@NEO oldboy]# grep -v '^$' person.txt # grep -v 表示 排除 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO [root@NEO oldboy]# sed '/^$/d' person.txt # sed 的 /^$/ 表示空行 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO # 另一种方法: sed 的 ! 表示 取反; 在 p d 这些参数前面加 ! [root@NEO oldboy]# sed -n '/^$/p' person.txt # 显示空行 [root@NEO oldboy]# sed -n '/^$/!p' person.txt # 排除空行 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO [root@NEO oldboy]# [root@NEO oldboy]# sed '$!d' person.txt # '$!d' : 不删除最后一行 105,feixue,CIO
4. sed常用功能之替换
# 文本替换: sed -i 's#neo#NEO#g' oldboy.log # s 单独使用 ---> 将每一行中 第一处匹配的字符串进行替换 # g (global:全局) ---> 每一行进行全部替换 --> sed 指令 s 的替换标志之一(全局替换) # sed 的 -i 参数 ---> 用于修改文件; -i.ori ---> 自动备份;先备份源文件,然后修改文件的内容 [root@NEO oldboy]# cat person.txt 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO [root@NEO oldboy]# sed 's#o#AAAA#' person.txt 101,AAAAldboy,CEO 102,zhangyaAAAA,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO [root@NEO oldboy]# sed 's#o#AAAA#g' person.txt 101,AAAAldbAAAAy,CEO 102,zhangyaAAAA,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO
5. sed变量替换 (重点)
[root@NEO oldboy]# x=oldboy # oldboy 赋值给 x [root@NEO oldboy]# y=oldgirl # oldgirl 赋值给 y (中间不要有空格) [root@NEO oldboy]# sed 's#$x#$y#g' person.txt # '' ---> 所见即所得,所以 '' 中的内容没有被解析 101,oldboy,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO [root@NEO oldboy]# sed "s#$x#$y#g" person.txt # "" 中的特殊符号($ $() `` !)会被解析 ; $x 表示 x变量 101,oldgirl,CEO 102,zhangyao,CTO 103,Alex,COO 104,yy,CFO 105,feixue,CIO # sed 的反向引用 :参考以前的
linux 三剑客 之 awk --- 取列、取行、统计
1. 基本的awk 执行过程:
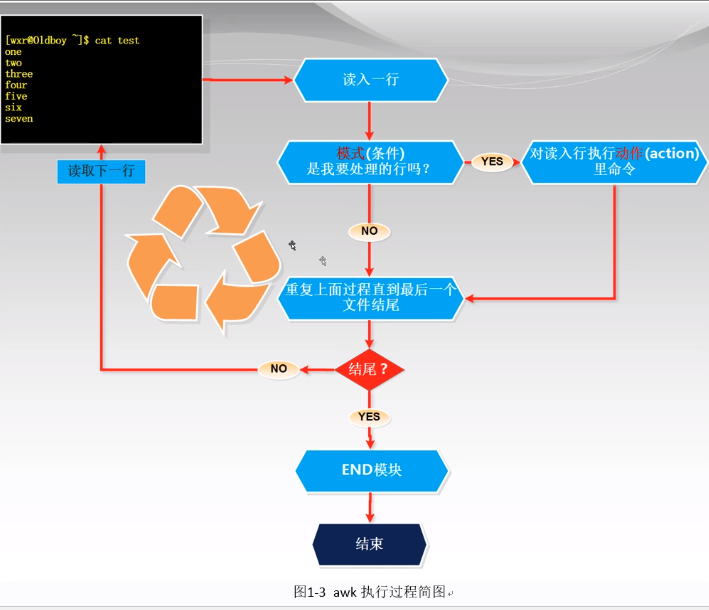
取出 passwd 文件的第二行的第一列和第二列
[root@NEO ~]# head -2 /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin [root@NEO ~]# awk -F ":" 'NR==2{print $1,$2}' /etc/passwd bin x # awk 语法格式: # awk 参数 '模式{动作}' 文件 ---> awk 参数 '条件(找谁){干啥}' 文件
2. 模式匹配:模式与动作
# 通过正则表达式作为模式 # awk 使用正则表达式作为模式 # 创建环境: mkdir -p /server/files/ cat >>/server/files/reg.txt<<EOF Zhang Dandan 41117397 :250:100:175 Zhang Xiaoyu 390320151 :155:90:201 Meng Feixue 80042789 :250:60:50 Wu Waiwai 70271111 :250:80:75 Liu Bingbing 41117483 :250:100:175 Wang Xiaoai 3515064655 :50:95:135 Zi Gege 1986787350 :250:168:200 Li Youjiu 918391635 :175:75:300 Lao Nanhai 918391635 :250:100:175 EOF # 第1表表示姓,第2列表示名字,第3列表示ID,第4列表示捐款金额 [root@NEO server]# cat /server/files/reg.txt Zhang Dandan 41117397 :250:100:175 Zhang Xiaoyu 390320151 :155:90:201 Meng Feixue 80042789 :250:60:50 Wu Waiwai 70271111 :250:80:75 Liu Bingbing 41117483 :250:100:175 Wang Xiaoai 3515064655 :50:95:135 Zi Gege 1986787350 :250:168:200 Li Youjiu 918391635 :175:75:300 Lao Nanhai 918391635 :250:100:175 [root@NEO server]# # 2.1 找出包含 111 的行: [root@NEO files]# pwd /server/files [root@NEO files]# awk '/111/' reg.txt Zhang Dandan 41117397 :250:100:175 Wu Waiwai 70271111 :250:80:75 Liu Bingbing 41117483 :250:100:175 # 其它的正则表达式的用法在 awk 没什么变化,但 ^ 和 $ 在 awk 中不太一样 ^ 表示 某一列中 以什么开头的字符串(以什么开头的列) : $3~/^oldboy/ 表示 第3列中 以 oldboy 开头的字符串, ~ 可理解成 包含 $ 表示 某一列中 以什么结尾的字符串(以什么结尾的列) : $3~/oldboy$/ 同理 # 2.2 显示Xiaoyu的姓名和ID号码 [root@NEO files]# awk '/Xiaoyu/' reg.txt # 只有模式(因为没有{});'/Xiaoyu/' 表示包含 Xiaoyu 的行,它相当于 '$0~/Xiaoyu/',即 把一整行当作一列, awk 的 $0 表示把一整行的内容放到了 $0 中(把一整行当作一列) Zhang Xiaoyu 390320151 :155:90:201 [root@NEO files]# awk '$0~/Xiaoyu/' reg.txt Zhang Xiaoyu 390320151 :155:90:201 [root@NEO files]# awk '/Xiaoyu/{print $1,$2,$3}' reg.txt # /Xiaoyu/ 表示包含 Xiaoyu 的行 Zhang Xiaoyu 390320151 [root@NEO files]# awk '$2~/Xiaoyu/{print $1,$2,$3}' reg.txt # $2~/Xiaoyu/ 表示 第2列(名字那一列)包含 Xiaoyu 的行 Zhang Xiaoyu 390320151 # 2.3 显示所有以41开头的ID号码的人的全名和ID号码 [root@NEO files]# awk '$3~/^41/{print $1,$2,$3}' reg.txt # $3~/^41/ ---> 第3列(ID那一列)以 41 开头 Zhang Dandan 41117397 Liu Bingbing 41117483 # 2.4 显示所有ID号码最后一位数字是1或5的人的全名 [root@NEO files]# awk '$3~/[15]$/{print $1,$2}' reg.txt # $3~/[15]$/ 表示模式( {}外面的就是模式 ), {print $1,$2} 表示动作 Zhang Xiaoyu Wu Waiwai Wang Xiaoai Li Youjiu Lao Nanhai # 2.5 显示Xiaoyu的捐款,每个值都以 $ 开头,如 $520$200$135 # 4. awk 里面进行替换的方法 --- gsub 函数 : '{gsub(/要找的内容(支持正则)/,"替换成的内容",$列号)}' [root@NEO files]# awk '{gsub(/:/,"$",$4)}' reg.txt # 没有输出是因为 awk 没有默认输出 [root@NEO files]# awk '{gsub(/:/,"$",$4);print}' reg.txt # 再加上 ;print 就会有输出 Zhang Dandan 41117397 $250$100$175 Zhang Xiaoyu 390320151 $155$90$201 Meng Feixue 80042789 $250$60$50 Wu Waiwai 70271111 $250$80$75 Liu Bingbing 41117483 $250$100$175 Wang Xiaoai 3515064655 $50$95$135 Zi Gege 1986787350 $250$168$200 Li Youjiu 918391635 $175$75$300 Lao Nanhai 918391635 $250$100$175 # 第4列的 : 替换成了 $ # gsub(/目标/,"替换为什么",第几列) # gsub(/目标/,"替换为什么") === gsub(/目标/,"替换为什么",$0) ---> 整行替换 [root@NEO files]# awk '$2~/Xiaoyu/{gsub(/:/,"$",$4);print}' reg.txt Zhang Xiaoyu 390320151 $155$90$201 [root@NEO files]# awk '$2~/Xiaoyu/{gsub(/:/,"$",$4);print $4}' reg.txt $155$90$201 [root@NEO files]# # gsub() 是awk 的一个函数
3. awk 数组 --- 统计与计算
# 特殊模式: BEGIN 和 END BEGIN{} ---> BEGIN里面的内容,会在 awk 读取文件内容之前运行 # 一般用于测试、计算等 END{} ---> END里面的内容,会在 awk 读取文件的最后一行之后运行 (END很常用) # 用来显示最终结果(前面一直在计算,最后END显示结果) [root@NEO files]# awk 'BEGIN{print "this is beginning"}' # 只写了个BEGIN ,后面就不用接文件了 this is beginning [root@NEO files]# awk 'BEGIN{print "this is beginning"} {print NR,$0}' reg.txt # {print NR,$0} ---> NR 表示 行号 this is beginning # BEGIN的内容 1 Zhang Dandan 41117397 :250:100:175 2 Zhang Xiaoyu 390320151 :155:90:201 3 Meng Feixue 80042789 :250:60:50 4 Wu Waiwai 70271111 :250:80:75 5 Liu Bingbing 41117483 :250:100:175 6 Wang Xiaoai 3515064655 :50:95:135 7 Zi Gege 1986787350 :250:168:200 8 Li Youjiu 918391635 :175:75:300 9 Lao Nanhai 918391635 :250:100:175 # 统计 /etc/services 文件里面的空行数量 [root@NEO files]# awk '/^$/{print NR}' /etc/services # '/^$/{print NR}' 22 266 299 320 326 393 461 474 479 486 494 506 512 518 583 584 [root@NEO files]# awk '/^$/{i=i+1;print i}' /etc/services # i=i+1 表示 把 i+1 的结果赋值给 i ,每个增加1,所以这个公式用来统计;i=i+1 也可以简写成 i++ ; i=i+1 和 print 之间用 ; 分隔 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@NEO files]# # i=i+1 === i++ ---> 用来统计 [root@NEO files]# awk '/^$/{i=i+1}END{print i}' /etc/services # {i=i+1}END{print i} ---> i=i+1 是先计算,END{print i} 表示 文件读取文件最后一行后 执行 {print i} 16 [root@NEO files]# awk '/^$/{i++}END{print i}' /etc/services # i++ 相当于 i=i+1 16
awk 数组案例详解与awk总结
#awk数组-统计与计算 # awk 数组的组成: hotel[110]="张三" # hotel 表示 数组的名字(酒店名称), 110 表示数组的元素名称(房间号), 张三 表示 元素内容(房间内容) ; hotel[110] 组成了一个数组 [root@NEO files]# awk 'BEGIN{hotel[110]="NEO";hotel[114]="XO";print hotel[110],hotel[114]}' # 110]="NEO" ---> 创建数组;print hotel[110] ---> 把数组中的内容显示出来 NEO XO # 处理以下文件内容,将域名取出并根据域名进行计数排序处理:(百度和sohu面试题) http://www.etiantian.org/index.html http://www.etiantian.org/1.html http://post.etiantian.org/index.html http://mp3.etiantian.org/index.html http://www.etiantian.org/3.html http://post.etiantian.org/2.html [root@NEO files]# cat url.txt http://www.etiantian.org/index.html http://www.etiantian.org/1.html http://post.etiantian.org/index.html http://mp3.etiantian.org/index.html http://www.etiantian.org/3.html http://post.etiantian.org/2.html [root@NEO files]# awk -F "[/.]+" '{print $2}' url.txt # 让 $2 作为数组的元素 www www post mp3 www post # h[$2] 表示 把 第2列(www post mp3)作为元素名称组成一个数组;一共有 3个元素 # h[$2]++ 表示 每个元素名称 遇到相同的元素名称时 加1,遇到不同的元素名称时不做处理 # h["www"] 表示 www 这个元素名称中的 元素内容 [root@NEO files]# awk -F "[/.]+" '{h[$2]=h[$2]+1;print h["www"]}' url.txt 1 2 2 2 3 3 [root@NEO files]# # 显示所有元素的内容 [root@NEO files]# awk -F "[/.]+" '{h[$2]++}END{print h["www"],h["post"],h["mp3"]}' url.txt 3 2 1 # awk 自己提供的循环,可用于显示数组里面的内容: for(pol in h) ---> h是数组,pol 是h数组中的变量(数组的元素名称;遍历的也是数组的元素) [root@NEO files]# awk -F "[/.]+" '{h[$2]++}END{for(pol in h) print pol}' url.txt www mp3 post # 遍历的是 数组的元素名称 [root@NEO files]# awk -F "[/.]+" '{h[$2]++}END{for(pol in h) print h[pol]}' url.txt # 把 元素名称 放到 数组h中 3 1 2 [root@NEO files]# awk -F "[/.]+" '{h[$2]++}END{for(pol in h) print pol,h[pol]}' url.txt www 3 mp3 1 post 2
shell编程基础:
shell编程所需的基础知识:
熟练使用 vim 编辑器
熟练 SSH终端
熟练掌握 Linux常用命令
熟练掌握Linux正则表达式及三剑客命令(grep sed awk)
shell编程基础知识与环境
基础知识:
# 1. 什么是Shell ? # 命令解释器; 你输入的命令,谁来给你解释/运行 # CentOS默认的 Shell 是 bash : echo $SHELL /etc/passwd .sh 结尾的文件 file 命令也可以查看文件类型 [root@NEO ~]# echo $SHELL /bin/bash [root@NEO ~]# cat /etc/shells /bin/sh /bin/bash /sbin/nologin /bin/dash /bin/tcsh /bin/csh [root@NEO ~]# file /etc/init.d/iptables /etc/init.d/iptables: POSIX shell script text executable # shell script ---> shell脚本 # 2. 什么是Shell脚本? # 命令大礼包 --- 一个程序文件,包含若干行Linux命令语句 # 循环,条件语句 # 创建shell脚本: # 1. 统一脚本存放目录 # 如: /server/scripts/ # 2. 推荐使用 vim 编辑器编程脚本 # 因为 vim 自带颜色 # 3. 第一行指出由哪个解释器来执行脚本中的内容: #!/bin/bash ---> #! 称为幻数,能被内核识别 ---> 必须写在第一行,如果不是第一行则为脚本注释行 ---> 双可以写为 #!/bin/sh # 4. 版权声明 # 5. 写一个简单脚本(切换目录显示文件属性)并运行 # 脚本目录示例: [root@NEO ~]# [root@NEO ~]# ls -l /server/scripts/ total 8 -rw-r--r-- 1 root root 66 Apr 7 23:22 ip.sh -rw-r--r-- 1 root root 9 Apr 7 14:30 show_date.sh # 脚本注释 & 版权声明: [root@NEO ~]# vim /server/scripts/ip.sh [root@NEO ~]# cat /server/scripts/ip.sh #!/bin/bash #!/bin/bash 表示 这个脚本是用 /bin/bash 运行解释的 # desc: show ip address # author: neo # time: 20190416 # version: v1.0 /sbin/ifconfig eth0 |awk -F "[ :]+" 'NR==2{print $4}' [root@NEO ~]# file /server/scripts/ip.sh /server/scripts/ip.sh: Bourne-Again shell script text executable [root@NEO ~]# /server/scripts/ip.sh # 正常运行脚本的方法:通过绝对路径 -bash: /server/scripts/ip.sh: Permission denied # 在linux 中创建的文件默认的权限是 644 [root@NEO ~]# sh /server/scripts/ip.sh # 以后在执行脚本的时候都是运行 sh 命令 10.0.0.200
变量
# 3.1 什么是变量? # 用一个固定的字符串,替代更多更复杂的内容 # x=1 # devPath=/server/ # filelist=`ls` 或 $(ls) # 引用变量: $x 相当于 ${x} [root@NEO ~]# echo $PATH $LANG # 环境变量 /usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin en_US.UTF-8 [root@NEO ~]# x=1 # 往变量中放值 ; x 是普通变量(局部变量) [root@NEO ~]# echo $x # 取出变量中的值 1 [root@NEO ~]# # 3.2 变量的分类: # 3.2.1 局部变量(普通变量): 只能在创建它们的Shell函数或Shell脚本中使用 定义变量: 变量名=value 变量名要求: 字母、数字、下划线组成,必须以字母或下划线开头 规范的变量名写法定义:见名知意 驼峰语法:首个单词字母小写,其余单词首字母大写 ---> oldAgeSex=1 把一个命令作为变量 普通字符串定义测试 [root@NEO ~]# week=10 [root@NEO ~]# echo $weekday # 此时系统认为 weekday 这个整体是个变量 [root@NEO ~]# echo ${week}day # $week 就相当于 ${week} 10day [root@NEO ~]# # 3.2.2 全局变量(环境变量): 大写,在Linux中绝大地方都可以用 在创建他们的Shell及其派生出来的子Shell中使用 分类: 查看全局变量: env ---> 只显示全局变量 bash内置的环境变量: Shell通过环境变量来确定 登陆用户名、命令路径、终端类型、登陆日志等 LANG PAHT SEHLL UID 等 自定义环境变量: 建议所有环境变量名均为大写 必须用 export 命令定义 取消变量: unset 永久生效 [root@NEO ~]# echo $LANG $PATH $PS1 en_US.UTF-8 /usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin [u@h W]$ [root@NEO ~]# # 全局变量 和 局部变量 [root@NEO ~]# vim /server/scripts/show_date.sh [root@NEO ~]# cat /server/scripts/show_date.sh #!/bin/hash # desc: # author: # time: # version: echo $OLDBOY [root@NEO ~]# OLDBOY=10 # 此时的 OLDBOY 是一个普通变量,在 /server/scripts/show_date.sh 这个脚本中无法使用 [root@NEO ~]# echo $OLDBOY 10 [root@NEO ~]# sh /server/scripts/show_date.sh # 输出为空,因为 OLDBOY 是个局部变量,在 这个脚本中无法使用 [root@NEO ~]# # 让普通变量变成全局问题的方法: export 命令; export 是临时生效;取消全局问题的方法 : unset 命令, unset 不但能取消全局变量,也能取消局部变量 [root@NEO ~]# export OLDBOY # 让 OLDBOY 这个普通变量 变成 全局变量 [root@NEO ~]# sh /server/scripts/show_date.sh 10 # 此时 OLDBOY 就能在 该脚本中使用了 [root@NEO ~]# [root@NEO ~]# env |grep OLDBOY OLDBOY=10 [root@NEO ~]# unset OLDBOY [root@NEO ~]# env |grep OLDBOY [root@NEO ~]# # 3.2.3 Shell 编程之环境变量相关的文件和目录: 全局环境变量配置文件: /etc/profile ---> 修改环境变量的文件 /etc/bashrc /etc/profile.d/ ---> 用户登陆到系统 会运行这个目录下面的脚本 ;脚本要有执行权限 用户自己的环境变量配置文件: ~/.bash_profile ~/.bashrc # 修改 /etc/profile.d/ 下的文件 ---> 用户登陆到系统会自动运行 [root@NEO ~]# ls /etc/profile.d/ colorls.csh cvs.csh glib2.csh lang.csh less.csh vim.csh which2.sh colorls.sh cvs.sh glib2.sh lang.sh less.sh vim.sh [root@NEO ~]# vim /etc/profile.d/show.sh [root@NEO ~]# cat /etc/profile.d/show.sh #!/bin/bash # desc: show ip address of eth0 # author: neo # time: 20190417 # version: v1.0 ip a s eth0 [root@NEO ~]# ll /etc/profile.d/show.sh -rw-r--r-- 1 root root 104 Apr 17 02:00 /etc/profile.d/show.sh [root@NEO ~]# chmod +x /etc/profile.d/show.sh [root@NEO ~]# ll /etc/profile.d/show.sh -rwxr-xr-x 1 root root 104 Apr 17 02:00 /etc/profile.d/show.sh WARNING! The remote SSH server rejected X11 forwarding request. Last login: Tue Apr 16 20:48:25 2019 from 10.0.0.1 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:26:b5:57 brd ff:ff:ff:ff:ff:ff inet 10.0.0.200/24 brd 10.0.0.255 scope global eth0 inet6 fe80::20c:29ff:fe26:b557/64 scope link valid_lft forever preferred_lft forever [root@NEO ~]# # 自己写的跳板机放到 /etc/profile.d/ 下面 # 特殊变量: # 位置变量: $0 (在脚本中) 获取当前执行的shell脚本的文件名 如果执行脚本带路径那么就包括脚本路径 模拟系统脚本使用 $0 $n n 表示数字;$n 表示 第n个参数 $# 表示参数的个数 # 进程状态变量 $? ---> 显示上一个命令的执行结果;命令执行正确 ---> 结果为0 , 命令执行错误 ---> 结果非0 ;软件安装后可用 $? 判断是否安装成功 # 位置变量: # 环境创建: [root@NEO scripts]# vim show_args.sh [root@NEO scripts]# cat show_args.sh #!/bin/bash # desc: # author: neo # time: # version: echo '$0:'$0 '$1:'$1 '$2:'$2 '$3:'$3 '$#:'$# # '$0:' 需要用单引号,双引号的话就被解析了 [root@NEO scripts]# sh show_args.sh $0:show_args.sh $1: $2: $3: $#:0 # $0 表示脚本的名字; $n 在脚本中表示第n个参数 [root@NEO scripts]# sh show_args.sh arg1 arg2 arg3 arg4 arg5 arg6 # 脚本后面可以跟参数 $0:show_args.sh $1:arg1 $2:arg2 $3:arg3 $#:6 # $# 表示参数的个数(脚本中一共有多少个参数) [root@NEO scripts]# ls /root/alex.oldboy.txt ls: cannot access /root/alex.oldboy.txt: No such file or directory [root@NEO scripts]# echo $? 2 # 执行错误 [root@NEO scripts]# ls /root/ alex.txt anaconda-ks.cfg data echotest.txt install.log.syslog oldboy-20171111.log [root@NEO scripts]# echo $? 0 # 执行正确 [root@NEO scripts]# # 变量赋值方法 --- read # 如何向变量中放内容? [root@NEO scripts]# vim show_args.sh [root@NEO scripts]# cat show_args.sh #!/bin/bash # desc: # author: neo # time: # version: x=1 y=2 echo $x $y [root@NEO scripts]# sh show_args.sh 1 2 # 如果 x y 是动态的参数,则利用下面的方法 [root@NEO scripts]# vim show_args.sh [root@NEO scripts]# cat show_args.sh #!/bin/bash # desc: # author: neo # time: # version: x=$1 # 改成 $1 和 $2 y=$2 echo $x $y [root@NEO scripts]# sh show_args.sh 10 20 # 传参10和20;10传给$1 ,20传给 $2 10 20 # read 能够从命令行中读取内容放到变量中 (交互式的) [root@NEO scripts]# read -p "input x y:" x y input x y:10 20 [root@NEO scripts]# echo $x 10 [root@NEO scripts]# echo $y 20 [root@NEO scripts]# [root@NEO scripts]# vim show_args.sh [root@NEO scripts]# cat show_args.sh #!/bin/bash # desc: # author: neo # time: # version: # x=$1 # y=$2 read -p "input x y:" x y echo $x $y [root@NEO scripts]# sh show_args.sh input x y:30 40 30 40 [root@NEO scripts]#
循环条件:
条件表达式: 格式:[<测试表达式>] 先敲一对 [] ,然后退格输入2个空格 [ ],最后再回退一个空格开始输入,即 [] 两端要各有一个空格,如: [ -f /etc/hosts ] 判断文件: -f ---> 文件是否存在 -d ---> 目录是否存在 0 存在,1 不存在 判断整数: 等于 equal ---> -eq 不等于 not equal ---> -ne 大于 greater than ---> -gt 大于等于 greater euqal ---> -ge 小于 less than ---> -lt 小于等于 less euqal ---> -le 简单案例 # Shell编程之测试表达式 --- 中括号 # [] 表示判断或测试 [root@NEO scripts]# [ -f /root/alex.oldboy.txt ] # 判断 /root/alex.oldboy.txt 这个文件是否存在 [root@NEO scripts]# echo $? 1 # 1 表示 [ -f /root/alex.oldboy.txt ] 查找的文件不存在, 0 表示存在 [root@NEO scripts]# [ -f /oldboy/oldboy.txt ] [root@NEO scripts]# echo $? 0 [root@NEO scripts]# [ -d /root ] # 判断 /root 这个目录是否存在; -d 判断目录是否存在 , -f 判断文件是否存在 [root@NEO scripts]# echo $? 0 # 判断整数: [root@NEO scripts]# [ 1 -eq 1 ] [root@NEO scripts]# echo $? 0 # 判断整数的简单案例:判断命令行参数个数等于2 [root@NEO scripts]# sh ./args.sh [root@NEO scripts]# sh ./args.sh a b arg number is 2 [root@NEO scripts]# # 如果 /oldboy 目录不存在则创建 [root@NEO ~]# [ -d /oldboy ] || mkdir -p /oldboy/ # 命令1 || 命令2 ---> || 表示 命令1不成立 则执行 命令2 # 如果 /root/oldboy.txt 存在则提示文件已经存在 [root@NEO ~]# [ -f /oldboy/oldboy.txt ] && echo file exists file exists # Shell编程之 if 判断 # 单分支条件语句: # 语法: if [ 条件 ];then 命令 fi # [] 中括号两端要有两个空格 # 案例:输入2个字,比较大小 # 语法: # if 单分支: [root@NEO scripts]# vim compare.sh [root@NEO scripts]# cat compare.sh #!/bin/bash # desc: # author: neo # time: 20190418 # version: 1.0 num1=$1 num2=$2 if [ $num1 -gt $num2 ];then echo $num1 greater than $num2 fi [root@NEO scripts]# sh compare.sh greater than [root@NEO scripts]# sh compare.sh 10 20 [root@NEO scripts]# sh compare.sh 20 10 20 greater than 10 [root@NEO scripts]# # if 双分支: [root@NEO scripts]# cat compare.sh #!/bin/bash # desc: # author: neo # time: 20190418 # version: 1.0 num1=$1 num2=$2 if [ $num1 -gt $num2 ];then echo $num1 greater than $num2 else echo $num1 less equal $num2 fi [root@NEO scripts]# sh ./compare.sh 10 20 10 less equal 20 [root@NEO scripts]# sh ./compare.sh 20 10 20 greater than 10 [root@NEO scripts]# sh ./compare.sh 20 10 1 3 2 5 7 # 不足之处:后4个参数无用 20 greater than 10 [root@NEO scripts]# sh ./compare.sh 20 ./compare.sh: line 9: [: 20: unary operator expected 20 less equal [root@NEO scripts]# # 参数必须是2个 [root@NEO scripts]# cat compare.sh #!/bin/bash # desc: # author: neo # time: 20190418 # version: 1.0 num1=$1 num2=$2 if [ $# -ne 2 ];then echo "Useage:please input 2 numbers:num1 num2" exit # 退出程序 fi if [ $num1 -gt $num2 ];then echo $num1 greater than $num2 else echo $num1 less equal $num2 fi [root@NEO scripts]# sh compare.sh 10 Useage:please input 2 numbers:num1 num2 [root@NEO scripts]# sh compare.sh 10 20 30 Useage:please input 2 numbers:num1 num2 [root@NEO scripts]# # if 多分支: [root@NEO scripts]# cat compare.sh #!/bin/bash # desc: # author: neo # time: 20190418 # version: 1.0 num1=$1 num2=$2 if [ $# -ne 2 ];then echo "Useage:please input 2 numbers:num1 num2" exit fi if [ $num1 -gt $num2 ];then echo $num1 greater than $num2 elif [ $num1 -lt $num2 ];then echo $num1 less equal $num2 else echo $num1 equal to $num2 fi [root@NEO scripts]# # shell 不太擅长小数
Shell编程之 for 循环
# for 循环语句: # 格式: for 变量名字 in 列表 do 命令 done [root@NEO scripts]# for num in 1 2 3 4 5 > do > echo "the $num number is:"$num > done the 1 number is:1 the 2 number is:2 the 3 number is:3 the 4 number is:4 the 5 number is:5 [root@NEO scripts]# # 优化linux开机启动项目,只保留 crond,sshd,network,rsyslog,sysstat ,其他的都关闭 # 思路: chkconfig 服务 off # 第一步:先排除上面的那几个服务 [root@NEO scripts]# chkconfig |egrep "crond|sshd|network|rsyslog|sysstat" -v # 第二步:取出所有的服务名 [root@NEO scripts]# chkconfig |egrep "crond|sshd|network|rsyslog|sysstat" -v|awk '{print $1}' # for 循环遍历关闭 [root@NEO scripts]# for service in `chkconfig |egrep "crond|sshd|network|rsyslog|sysstat" -v|awk '{print $1}'` > do > echo chkconfig $service off # echo 为了测试 > done