上一篇写了论文的研究背景和作者提出的网络结构,这次把后面的数据集处理和实验及结论写完。
四、实验
1.数据集的处理
作者使用了由8000多张tif格式未压缩图像构成的RAISE数据集(官网上可以选几种不同数据量的版本——1000、2000、4000、6000和全部,给出每种版本中每张图像的名字、NEF及TIFF格式下载地址以及相机各种参数和类别等信息,汇总在了一张csv表格中,需要用到wget命令行等方式批量下载)。作者提到,如果原封不动使用数据集中的超大图像的话,会使网络学习到去马赛克过程中的图像伪影以及图像传感器噪声等错误信息,因此作者为了避免这个问题,采用了对图像下采样的方式,将图像下采样至原来的1/4像素之后作为ground truth数据(此处作者使用多次下采样,每次采样因子为1.25,直到图像大小满足要求的方式得到下采样后的图像),即由原始的一千六百万像素级变为四百万像素级图像,由这些图像构成整个数据集(后续还要经过预处理截取每张图像的一部分来使用)。
然后,根据上一篇博文中图三的过程,为了得到网络的输入。需要对ground truth图再进行下采样得到原来的1/4像素图像得到一百万像素级图(此次下采样直接进行一次因子为2的下采样得到),然后从得到的彩色图像中的每个位置,按照拜尔阵列的排列方式分别取其中一个通道的像素作为该位置上的拜尔阵列值。这样就得到了低分辨率的单通道拜尔阵列输入数据集。上述下采样过程如图六所示。
对于训练数据,作者在整个数据集中的landscape类别下随机选取了4000张,在其他类别随机选取了2000张共6000张图像作为训练数据;对于测试集,作者从剩下的2000张图像中随机选取了50张图像作为测试。
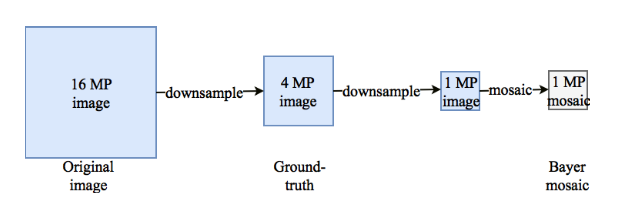
图六
2.训练细节
在训练过程中,作者对上一节中获取的拜尔阵列图像取其中的64 × 64 × 1尺寸的图像块作为网络输入,取ground truth中对应的128 × 128 × 3的图像块作为labels。训练采用ADAM优化器,初始学习率设定为lr = 0.0001,β1 = 0.9,β2 = 0.999,ε = 10-8;batchsize设为16,并且为了更好地收敛,设定每10000个batch就将学习率减为一半。
3.实验结果
由于本文是将超分辨率和去马赛克结合起来优化的第一篇文章,因此他分别应用了几个目前效果最突出的去马赛克算法和超分辨率算法结合起来对图像进行处理作为对照组,其中去马赛克算法分别选择了FlexISP, SEM和DemosaicNet;超分辨率算法则选择了SRCNN。同时,需要注意的是,SEM和DemosaicNet两种去马赛克算法同时也对图像进行了去噪处理,因此为了对比的准确性,作者将两个算法的噪声都设置为了0(不去噪)。作者进行比较的思路和实验后的结果分别如图七(a)、(b)所示。该表通过PSNR和SSIM两种指标定量地说明了文章所提出的网络的有效性。
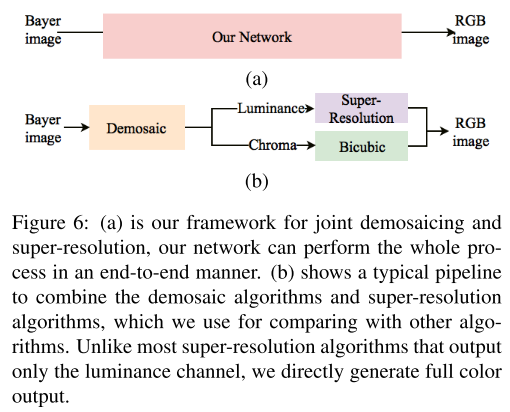
(a)
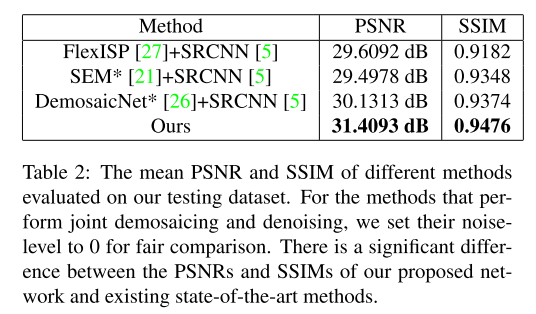
(b)
图七
然后作者给出了一组图像从视觉上定性地证明了他们所提出的网络效果,如图八所示。最后得出的结论是,无论从定量还是定性的角度,文章所提出的模型都比现有的去马赛克和超分辨率算法结合的效果要好,同时也不会产生通常算法中会出现的常见的图像伪影。


图八
读完论文有两个疑问:
1.为什么下采样到原来的1/4之后就可以消除去马赛克过程中图像伪影的影响?
2.为什么第一次(16→4)下采样不直接下采样到1/2,要每次下采样1.25倍得到像素级为原来1/4的图像?