一、面向对象
什么是面向对象?
对比面向过程,是两种不同的处理问题的角度
面向过程更加注重事情的每一个步骤及顺序,面向对象更注重事情有哪些参与者(对象)、及各自需要做什么
比如:洗衣机洗衣服
面向过程会将任务拆解成一系列的步骤(函数),1、打开洗衣机--->2、放衣服---->3、放洗衣粉---->4、清洗---->5、烘干
面向对象会拆出人和洗衣机两个对象:
人:打开洗衣机、放衣服、放洗衣粉
洗衣机:清洗、烘干
从以上例子能看出,面向过程比较直接高效,而面向对象更易于复用、扩展和维护
封装:封装的意义,在于明确标识出允许外部使用的所有成员函数和数据项
内部细节对外部调用透明,外部调用无需修改或者关系内部实现
1、JavaBean的属性私有,提供getset对外访问,因为属性的赋值或者获取逻辑只能由javabean本身决定。而不能由外部胡乱修改。
2、orm框架,操作数据库,我们不需要关心连接的问题是如何建立的,sql是如何执行的,只需要引入mybatis,调用方法即可。
继承:继承基类的方法,并做出自己的改变和扩展
子类共性的方法或者属性直接使用父类的,而不需要自己再定义,只需要扩展自己个性化的
多态: 基于对象所属类的不同,外部对同一个方法的调用,实际执行的逻辑不同。
继承,方法重写,父类引用指向子类对象
父类类型 变量名 = new 子类对象; 变量名.方法名();
无法调用子类特有的功能
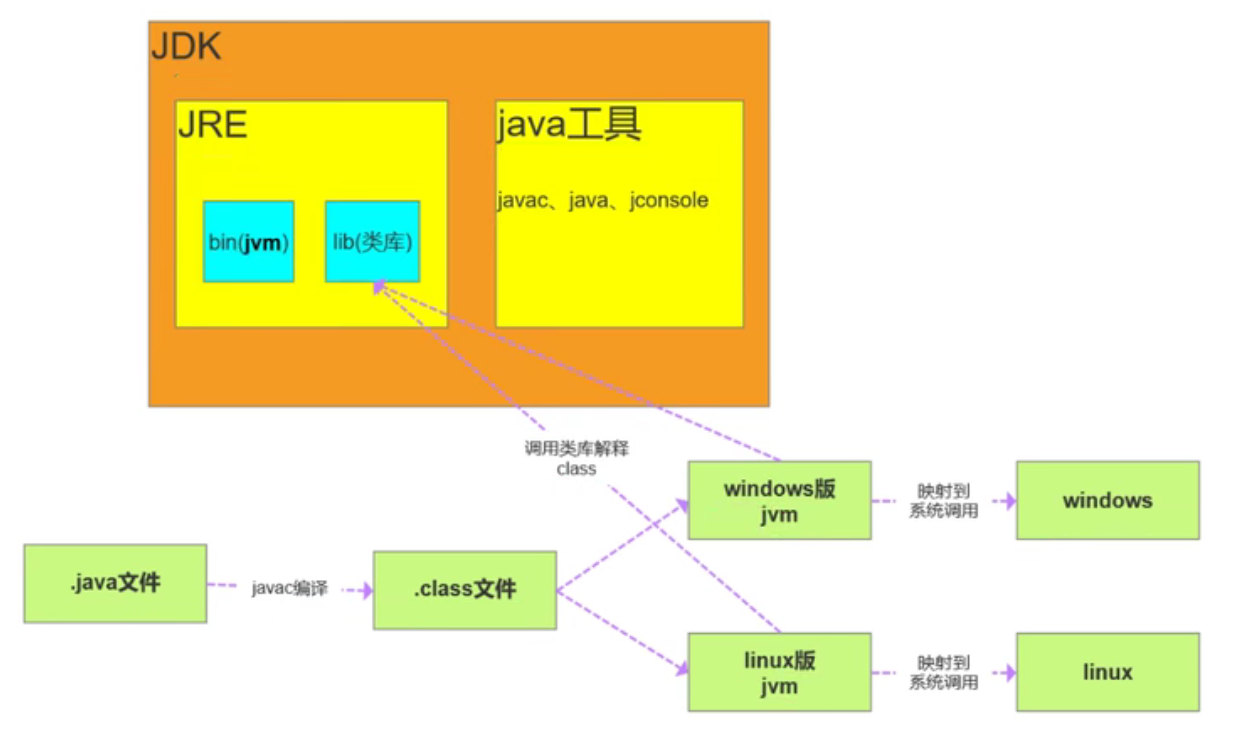
二、JDK、JRE、JVM三者之间的区别和联系
JDK:Java develpment kit java 开发工具
JRE:Java runtime environment java运维工具
JVM:Java virtual machine java虚拟机
三、== 和 equals 比较
==比较的是栈中的值,基本数据类型是变量值,引用类型是堆中内存对象的地址
equals: object中默认也是采用==比较,通常会重写
object
public boolean equals(object obj){ return (this == obj); }
String
public boolean equals(object anObject) { if (this == anObject){ return true; } if(anObject instanceof String){ String anotherString = (String)anObject; int n = value.length; if(n == anotherString.value.length){ char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n -- != 0) { if(v1[i] != v2[i]) return false; i++; } return true; } } return false; }
上述代码可以看出,String类中被复写的equals()方法其实是比较两个字符串的内容。
案例:
public class Demo02 { public static void main(String[] args) { String str1 = "Hello"; //存在堆内存中的常量池中,在栈中存的是内存地址 String str2 = new String ("Hello"); //在堆中分配内存,在栈中存的是内存地址 String str3 = str2; //引用传递,赋值赋的是引用地址值 System.out.println(str1 == str2); //false 比较的是栈中的值,内存地址不同 System.out.println(str1 == str3); //false System.out.println(str2 == str3); //true 比较的是栈中的值,引用地址值 //string重写了equals方法 System.out.println(str1.equals(str2)); //true 比较的是字符内容值 System.out.println(str1.equals(str3)); //true 比较的是字符内容值 System.out.println(str2.equals(str3)); //true 比较的是字符内容值 }
四、简述final作用及为什么局部内部类和匿名内部类只能访问局部final变量?
final,最终的
- 修饰类:表示类不可被继承
- 修饰方法:表示方法不可被子类覆盖,但是可以重载。
- 修饰变量:表示变量一旦被赋值就不可以更改它的值
(1)修饰成员变量
- 如果final修饰的是类变量,只能在静态初始化块中指定初始值或声明该类变量时指定初始值。
- 如果final修饰的是成员变量,可以在非静态初始化块,声明该变量或者构造器中执行初始值。
(2)修饰局部变量
系统不会为局部变量进行初始化,局部变量必须由程序员显示初始化。因此使用final修饰局部变量时,既可以在定义指定默认值(后面的代码不能对变量再赋值),也可以不指定默认值,而在后面的代码中对final变量赋初始值(仅一次)。
public class FinalVar { final static int a = 0; //再声明的时候就需要赋值,或者静态代码块赋值 /** static{ a = 0; } */ final int b = 0; //再声明的时候就需要赋值,或者代码块中赋值,或构造器中赋值 /* { b = 0; } */ public static void main(String[] args) { final int localA; //局部变量只声明没有初始化,不会报错,与final无关 localA = 0; //在使用之前一定要赋值 // localA =1; //但是不允许第二次赋值 } }
(3)修饰基本数据类型和引用数据类型
- 如果时基本数据类型的变量,则其数值一旦初始化之后便不能更改;
- 如果是引用数据类型的变量,则在对其初始化之后便不能再让其指向另一个对象。但是引用的值是可变的。
public class FinalReferenceTest{ public static void main(){ final int[] iArr = {1,2,3,4}; iArr [2] = -3; //合法 iArr = null; //非法,对iArr 不能重新赋值 final Person p = new Person(25); p.setAge(24); //合法 p = null; //非法 } }
为什么局部内部类和匿名内部类只能访问局部final变量?
public class Demo03 { public static void main(String[] args) { } public void test(final int b){ final int a = 10; new Thread(){ @Override public void run(){ System.out.println(a); System.out.println(b); }; }.start(); } } class Outclass { private int age = 12; public void outPrint(final int x){ class Inclass { public void Inprint(){ System.out.println(x); System.out.println(age); } } new Inclass().Inprint(); } }
首先需要知道的一点是:内部类和外部类是处于同一个级别的,内部类不会因为定义在方法中就会随着方法的执行完毕就被摧毁。
这里会产生问题:当外部类的方法结束时,局部变量就会被摧毁,但是内部类对象可能还存在(只有没有人再引用它时,才会死亡)。这里就出现了一个矛盾;内部类对象访问了一个不存在的比变量。为了解决这个问题,就将局部变量复制了一份作为内部类的成员变量,这样当局部变量死亡后,内部类仍可以访问它,实际访问的是局部变量的“copy”。这样就好像延长了局部变量的生命周期。
将局部变量复制为内部类的成员变量时,必须保证这两个变量是一样的,也就是如果我们在内部类中修饰了成员变量,方法中的局部变量也得跟着改变,怎么解决问题?
就将局部变量设置为final,对它初始化后,我就不让你再去修改这个变量,就保证了内部类的成员变量和方法的局部变量的一致性。这实际上也是一种妥协。使得局部变量与内部类建立的拷贝保持一致。
五、String、StringBuffer、StringBuilder区别及使用场景
String是final修饰的,不可变,每次操作都会产生新的string对象
StringBuffer和StringBuilder都是在原对象上操作
StringBuffer是线程安全的,StringBuilder线程不安全的
StringBuffer方法都是synchronized修饰的(不需要额外的加锁),
并发环境的特点:多线程环境下,共享变量,结果不被更改。==>这是需要使用synchronized--->StringBuffer
性能:StringBuilder(没有加锁性能要好一些) > StringBuffer > String
场景:经常要改变字符串内容时使用 StringBuffer 和 StringBuilder
优先使用StringBuilder ,多线程使用共享变量时使用StringBuffer
六、 重载 与 重写 的区别
重载:发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同、方法返回值和访问修饰符可以不同,发生在编译时。
重写:发生在父子类中,方法名、参数列表必须相同、返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类,如果父类方法访问修饰符为private则子类就不能重写该方法。
七、接口与抽象类
初级回答:
- 抽象类可以存在普通成员函数,而接口中只能存在public abstract方法
- 抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的
- 抽象类只能继承一个,接口可以实现多个
中高级回答:
接口的设计目的,是对类的行为进行约束(更准确的说是一种”有“约束,因为接口不能规定类不可以有什么行为),也就是提供一种机制,可以强制要求不同的类具有相同的行为。它只约束了行为的有无,但不对如何实现行为进行限制。
抽象类的设计目的,是代码复用。当不同的类具有某些相同的行为(记为行为集合A),且其中一部分行为的实现方式一致时(A的飞真子集,记为B),可以让这些类都派生于一个抽象类。在这个抽象类中实现了B,避免让所有的子类来实现B,这就达到了代码复用的目的。而A减B的部分,留给各个子类自己实现。正是因为A-B在这里没有实现,所以抽象类不允许实例化出来(否则当调用到A-B时,无法执行)。
抽象类是对类本质的抽象,表达的是is A 的关系,比如:xp is a car。抽象类包含并实现了子类的通用特性,将子类存在差异化的特征进行抽象,交子类去实现。
接口是对行为的抽象,表达的是like A 的关系。比如:Bird like a Aircraft (像飞行器一样可以飞),但其本质上 is a Bird(不是飞行器)。接口的核心是定义行为,即实现类可以做什么,至于实现类主体是谁,是如何实现的,接口并不关心。
使用场景:当你关注一个事物的本质的时候,用抽象类;当你关注一个操作的时候,用接口。
抽象类的功能要远超过接口,但是定义抽象类的代价高。因为高级语言来说(从实际设计上来说也是)每个类只能继承一个类。在这个类中,你必须继承或编写出其所有子类的所有共性。虽然接口在功能上会弱化许多,但是它只是针对一个动作的描述。而且你可以在一个类中同时实现多个接口。在设计阶段会降低难度。
八、List 和 Set 的区别
List:有序,按对象进去的顺序保存对象,可重复,允许多个Null元素对象,可以使用Iterator取出所有元素,在逐一遍历,还可以使用get(int index)获取指定下标的元素。
Set:无序,不可重复,最多允许有一个Null元素对象,取元素时只能用Iterator接口取得所有元素,在逐一遍历各个元素。
九、hashcode 与 equals
hashcode介绍
hashcode() 的作用是获取哈希码,也成为散列码。它实际上是返回一个Int整数。这个哈希码的作用是确认该对象在哈希表中的索引位置。hashcode() 定义在JDK的Object.java中,Java中的任何类都包含有hashCode() 函数。散列表存储的是键值对(key-value),它的特点是:能根据”键“快速的检索出对应的”值“。这其中就利用了散列码!(可以快速找到所需要的对象)。
为什么要有hashCode
以”HashSet如何检查重复“为例子来说明为什么要有hashCode:
对象加入HashSet时,HashSet会计算对象的hashCode值来判断对象加入的位置,看该位置是否有值,如果没有、HashSet会假设对象没有重复出现。但是如果发现有值,这时会调用equals()方法来检查两个对象是否真的相同。如果两者相同,HashSet就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。这样就大大减少了equals的次数,相应就大大提高了执行速度。(equals比较消耗性能,hashCode比equals性能高)
- 如果两个对象相等,则hashCode一定也相同的
- 两个对象相等,对两个对象分别调用equals方法都返回true
- 两个对象有相同的hashcode值,它们也不一定是相等的
- 因此,equals方法被覆盖过,则hashcode 方法也必须被覆盖
- hashcode()的默认行为是对堆上的对象产生独特值(索引值)。如果没有重写hashcode(),则该class的两个对象(两个引用地址)无论如何都不会相等(即使这两个对象指向相同的数据)
十、ArrayList 和 Linked List区别
ArrayList:基于动态数组(存的数值类型是一致的),连续内存存储,适合下标访问(随机访问),扩容机制:因为数组长度固定,超出长度存储数据时需要新建数组,然后将老数组的数据拷贝到新数组,如果不是尾部插入数据还会涉及到元素的移动(往后复制一份,插入新元素),使用尾插法并指定初始容量可以极大提升性能,甚至超过linkedList(需要创建大量的node对象)。指定初始容量的大小可以减少扩容的次数,尾部插入元素的时候也可以提高其性能(有时候ArrayList在插入元素时比LinkedList速度还快)。
Linked List:基于链表,可以存储在分散的内存中,适合做数据插入及删除操作,不适合查询:需要逐一遍历,遍历LinkedList必须使用iterator不能使用for循环,因为每次for循环体内通过get(i) 取得某一元素时都需要对list重新进行遍历,性能消耗极大。(LinkedList里面维护了一个Node内部类,每次插入一个元素都会创建一个node对象,大量数据插入的时候就需要创建大量的node,会很消耗性能,里面有一个item变量来维护这些元素)。另外不要视图使用indexOf等返回元素索引,并利用其进行遍历,使用IndexOf对List进行了遍历,结果为空时会遍历整个列表。