一,Map集合的遍历
- 概述:map集合不能够单独遍历,只能间接的进行遍历。
- 采用的思路:先把双列集合转换为单列集合,通过单例集合的遍历得到其中的一部分数据通过map集合的或者是其他的相关方法得到另一部分数组,从而达到遍历双列集合的效果
- 如何变成单列集合?
- 方式一:纵向切割法
1.1 双列集合纵向的看就只有 key 和 value 这样的两列,从 key 和 value 中间切开,变成了两列,每列的数据都存放到一个容器中,map集合里面得到 key可以找到对应的value,所有优先操作key这一列的数据,得到key 再通过map集合的get(K k)得到对应的value
2. 方式二:横向切割法
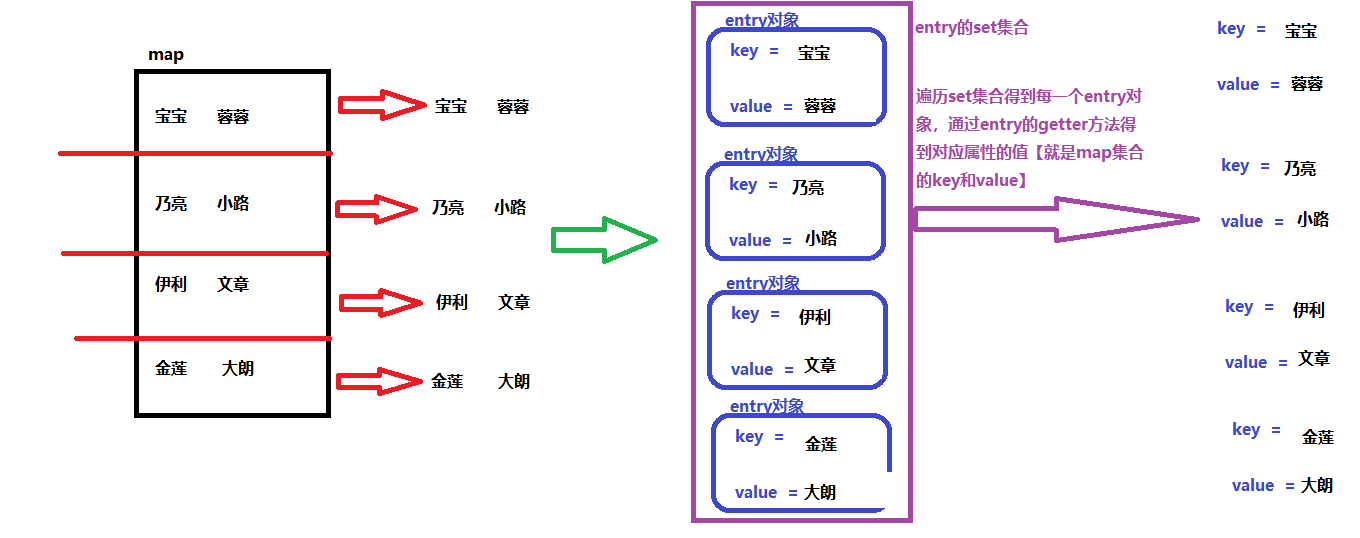
2.1 map集合有几对数据就有几行,把一对一对的数据切割开来变成单独的数据,把每一个单独的数据封装到一个entry对象的属性key和value【此处的key和value不是map的key和value是 entry 对象的属性名称】这样就可以得到多个entry对象,然后把这些entry对象同意放在一个容器【Set集合】
- 遍历方式有两种:
- 键找值方式
步骤:
1.1、通过 map 对象调用 keySet 得到 map 集合所有 key 的 set 集合
1.2、遍历 set 集合
1.3、在遍历 set集合 的循环体中使用 map集合对象 调用get(key)得到对应的value
原理图:

2. 键值对对象方式
步骤:
2.1、把map集合变成 entry对象 的set集合【map集合有一个方法 entrySet,就可以干这件事】
2.2、遍历 entry 对象的集合
2.3、在遍历的过程中通过 getter方法 获取对应的 key和 value
原理图:
代码示例
import java.util.Collection;
import java.util.HashMap;
import java.util.Map.Entry;
import java.util.Set;
public class Demo_Map {
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<>();
map.put("宝宝", "蓉蓉");
map.put("乃亮", "小璐");
map.put("伊利", "文章");
map.put("金莲", "大朗");
//第一种遍历方法:键找值
//双列集合变单列集合,set为无序的单列集合
Set<String> set = map.keySet();
System.out.println(set); //[乃亮, 金莲, 伊利, 宝宝]
//遍历set集合
//foreach: 数据类型 变量名:要遍历的容器{拿到元素处理逻辑}
for (String key : set) {
String value = map.get(key);
//得到key对应的value
System.out.println(key+"**"+value);
}
System.out.println("-----------------------");
//第二种遍历方法:键值对方式遍历
//entrySet()将map集合中每个元素封装成Entry对象后保存到Set集合
Set<Entry<String, String>> set2 = map.entrySet();
//为什么entry对象的属性的数据类型可以自动的和map集合的key和value的数据类型一样
//因为entry是map的内容接口 entry是map的一部分,所以entry的泛型和map集合的泛型使用的同一个泛型
//遍历entry的set集合得到每一个entry对象
System.out.println(set2); //[乃亮=小璐, 金莲=大朗, 伊利=文章, 宝宝=蓉蓉]
for (Entry<String, String> entry : set2) {
//.getKey() 和 .getValue() 获取键和值
//获取key属性的值也就是map的key 的值
String key = entry.getKey();
//获取value 属性的值 也就是map的value的值
String value = entry.getValue();
System.out.println(key+"**"+value);
}
//如果只是单纯的得到 map集合的value值,可以用Collection的values方法
Collection<String> values = map.values();
System.out.println(values); //[小璐, 大朗, 文章, 蓉蓉]
}
}
- 补充:
- 纵向切割的时候分别可以得到 key 和 value 的集合,
- key的集合:通过keySet()得到
- value的集合:通过values()方法得到 Collection集合【如果以后只想单纯的得到map集合的value值】
二,HashMap
- 概述:它是Map集合的典型的实现类,没有自己的特有特点和功能,无非就是为了事项Map接口的所有一切。
- 功能:
- put: 增加和修改元素
- remove: 根据键删除值
- clear : 清空所有集合元素
- get(key): 根据键获取值
- containsKey: 判断map集合的key中是否包含参数
- containsValue: 判断map集合的value中是否包含参数
- keySet: 获取map集合所有key的set集合
- entrySet: 获取所有键值对数据对应的键值对对象的set集合
- values: 获取map集合所有value的单列集合
- size(): 获取集合的长度
- 遍历方式和 map 是一样的。[[ 键找值、键值对 ]]
-
如何保证Hashmap的key存放对象的内容是唯一性
- map集合的键有唯一不可重复的特点;不可重复体现在两点:
- 第一点:对象不一样【地址值不一样就是不一样】比较简单,不需要做任何的事情,只需要把对象当做键存入到 map集合 即可
- 第二点:对象的值不一样【对象的属性值不一样,不包括地址值不一样属性值一样】
- 需要既要对地址值进行保证也要对内容值进行保证,要同时达到这样的效果,需要在对象对应的类中重写 hashCode 和 equals 方法
- 唯一性和 hashSet 原理是一样的:
- 是因为HashSet底层是使用HashMap来存放数据并实现
- 都是根据hash值来存放数据的
代码示例
//定义Student类
public class Student {
private String name;
private int age;
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
}
//定义测试类
import java.util.HashMap;
public class Student_Test {
public static void main(String[] args) {
HashMap<Student, String> map = new HashMap<>();
map.put(new Student("柏芝", 42),"九龙"); // key 就是Student的内容,student里面已重写方法
map.put(new Student("柏芝", 42),"尖沙咀"); //尖沙咀属于修改后的内容
map.put(new Student("张敏",55),"浅水湾");
map.put(new Student("林青霞",60),"铜锣湾");
map.put(null,"铜锣湾"); //添加成功,key值是可以为null
map.put(new Student("林青霞",60),null); //添加成功 value也可以为null
map.put(null, null); //修改成功了,修改了(null,铜锣湾)
System.out.println(map);//重写了hashcode和equals方法所以相同的就只添加一次,出来的是修改后的内容,唯一性
}
}
-
HashMap的key可不可以为null,value的值可不可以为null?
- 可以的而且支持同时为mull null为键的时候不管是否重写hashCode和equals方法都是唯一的一个key
三,HashTable
- 概述:是Map集合早期的典型实现类,没有字独有的功能和特点,完全是为了实现map的功能而出现的,在jdk1.2版本之后逐步被 HashMap 取代使用位置。
- 底层是由哈希表组成,所以无序,不支持null 键,但线程安全。
- 他的使用方式和 HashMap 使用是一模一样,无非就是调用的时候换个对象
-
HashMap和 HashTable:【面试题】
- 相同点:都是Map集合的典型实现类。功能的使用是一模一样的
- 不同点:
- 出现的时间不同【HashTable 早于 HashMap】
- HashTable 是线程安全的,HashMap 是线程不安全的
- HashTable 是效率是低的,HashMap 是效率高的
- HashTable 的 key 和 value 不支持null值;HashMap 支持 null值的
代码示例
import java.util.HashMap;
import java.util.HashSet;
import java.util.Hashtable;
public class Student_Test {
public static void main(String[] args) {
HashMap<Student,String> map = new HashMap<>();
map.put(new Student("柏芝",23), "九龙");
map.put(new Student("柏芝",23), "尖沙咀");
map.put(new Student("张敏",40), "新界");
map.put(new Student("朱茵",50), "铜锣湾");
map.put(null, "铜锣湾");//添加成功了,key可以为null
map.put(new Student("朱茵",50), null);//添加成功了 value也可以为null
map.put(null, null);//修改成功了 null最为键的时候不管是否重写hashCode和equals方法都是唯一的一个key
System.out.println(map);
System.out.println("==============");
Hashtable<Student, String> hashtable = new Hashtable<>();
hashtable.put(new Student("柏芝",23), "九龙");
hashtable.put(new Student("柏芝",23), "尖沙咀");
hashtable.put(new Student("张敏",40), "新界");
hashtable.put(new Student("朱茵",50), "铜锣湾");
//hashtable.put(null, "铜锣湾");//添加成功了,key可以为null
//hashtable.put(new Student("朱茵",50), null);//添加成功了 value也可以为null
//hashtable.put(null, null);
System.out.println(hashtable);
}
}
四,LinkedHashMap
- 概述:他是 HashMap的子类,同样也是Map的实现类。他的功能全部来自Map的共有功能。Map集合是无序的。但是这个实现类是有序的。但是其他的特征和Map的特征的一致。
- 遍历方式和 Map 的遍历方式也是一样的。[[ 键找值;键值对对象 ]]
代码示例
import java.util.HashMap;
import java.util.LinkedHashMap;
public class Demo_LinkedHashMap {
public static void main(String[] args) {
HashMap<Student, String> map = new HashMap<>();
map.put(new Student("柏芝", 42),"九龙"); // key 就是Student的内容,student里面已重写方法
map.put(new Student("柏芝", 42),"尖沙咀"); //尖沙咀属于修改后的内容
map.put(new Student("张敏",55),"浅水湾");
map.put(new Student("林青霞",60),"铜锣湾");
map.put(null,"铜锣湾"); //添加成功,key值是可以为null
map.put(new Student("林青霞",60),null); //添加成功 value也可以为null
map.put(null, null); //修改成功了,修改了(null,铜锣湾)
System.out.println(map);//重写了hashcode和equals方法所以相同的就只添加一次,出来的是修改后的内容,唯一性
System.out.println("--------------------------");
LinkedHashMap<Student, String>map2 = new LinkedHashMap<>();
map2.put(new Student("柏芝", 42),"九龙");
map2.put(new Student("柏芝", 42),"尖沙咀");
map2.put(new Student("张敏",55),"浅水湾");
map2.put(new Student("林青霞",60),"铜锣湾");
System.out.println(map2); //输出有序
}
}
五,Map和Collection的区别
- 相同点:都是存放引用数据类型数据的容器
- 不同点:
- 位置上存放的元素个数不一样:Map是一对【键值对数据】 Collection 放的是一个
- Map里面有序的只有LinkedHashMap,Collection有 List 体系和 LinkedHashSet
- Map不能直接遍历,Collection可以直接遍历,遍历方式一共四种
六,Collections工具类
- 概述:用来处理Collection集合中数据的一些相关功能的工具类 类似 Arrays
- 常用方法:
- int binarySearch(List list, E e): 二分查找法查找e元素在list集合的第一次出现的索引。使用前提:list 需要升序排好了。
- fill(List list, E e): 使用e填充满集合list【使用元素e替换list集合原有的元素】。使用前提:list 集合中必须要有元素
- int frequency(Collection c,E e): 返回集合c中的e元素的个数【计数】
- max: 返回集合中的最大值
- min: 返回集合中的最小值
- replaceAll(List list,E olde ,E newe): 使用news将集合中的olde元素全部替换
- reverse(List list): 反转list集合中的元素位置
- shuffer(List list): 将list集合中的元素全部打乱
- swap(List list,int a ,int b ): 将list集合中a索引的值和b索引的值进行互换
- sort(List list): 将list的元素进行了升序排序
代码示例:
import java.util.ArrayList;
import java.util.Collection;
import java.util.Collections;
public class Demo_Collections {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
list.add(23);
list.add(12);
list.add(43);
list.add(43);
list.add(57);
list.add(57);
list.add(2);
list.add(2);
ArrayList<String> list1 = new ArrayList<>();
list1.add("23");
list1.add("12");
list1.add("43");
list1.add("57");
list1.add("57");//没有排序找到的不一定是第一次出现的那个角标值
list1.add("2");
int i = Collections.binarySearch(list1,"57");
System.out.println(list1); //[23, 12, 43, 57, 57, 2]
System.out.println(i); //57的角标值是4
Collections.sort(list1);// 默认是升序
System.out.println(list1);//字符串排序是按首字母来排序的[12, 2, 23, 43, 57, 57]
int j = Collections.binarySearch(list1,"57");
System.out.println(j); //4
Collections.sort(list);
System.out.println(list); //[2, 2, 12, 23, 43, 43, 57, 57]
int k = Collections.binarySearch(list,57);
System.out.println(k);//6
ArrayList<Object> list2 = new ArrayList<>();
list2.add(100);
list2.add(100);
list2.add(200);
list2.add(300);
Collections.fill(list2,30);//用30替换集合里面的元素, 集合里面必须要有元素
System.out.println(list2);
int num = Collections.frequency(list2, 30);
System.out.println(num); //4,30的元素有4个,没有的话就是0
Integer max = Collections.max(list);
Integer min = Collections.min(list);
System.out.println(max+"=="+min);//57==2,集合里面的最大值与最小值
Collections.replaceAll(list2, 30, "你好");
System.out.println(list2);//[你好, 你好, 你好, 你好],把30全部替换成了字符“你好”,因为list2是object类型所以可以转换为字符
//fill方法是把集合里面的所有的元素替换,replaceAll方法只替换指定的元素其它的元素不替换
System.out.println(list); //[2, 2, 12, 23, 43, 43, 57, 57]
Collections.reverse(list);
System.out.println(list); //[57, 57, 43, 43, 23, 12, 2, 2] 反转
Collections.swap(list, 3, 5);
System.out.println(list); //[57, 57, 43, 12, 23, 43, 2, 2] 3角标与5角标互换
Collections.shuffle(list);
System.out.println(list); //将集合里面的全部元素打乱
}
}
- 综合案例:斗地主
- 使用双列集合完成斗地主案例【发牌到看牌的过程】
- 分析:
- 准备牌:
1.1 存放牌的容器【双列集合】
1.2 生成并存放牌【组合牌】
1.3 牌由花色和数字组成的以及大小王
1.4 准备花色和数字
1.5 花色和 数字去拼接就成为了牌
1.6 把牌存到map集合【存放到哪里合适?】
1.7 牌存在map的value上,key可以是牌的编号
2. 洗牌
2.1 使用shuffer方法洗牌,洗的List 集合 是一个双列集合
2.2 洗编号所在的list集合
3. 发牌
3.1 怎么发牌合适,牌能直接发吗?
3.2 每三张一轮回 可不可以给牌设置编号
【使用编号所在的list集合的索引对3取余根据值不同发给不同的人但是最后的三张不需要取余,直接留给底牌】发牌的时候发编号 ,
4. 看牌
4.1 看牌的时候只要把编号换成对应的牌就可以了
代码示例
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.Set;
public class Poker {
public static void main(String[] args) {
//第一步:准备牌
//准备牌,存放牌的容器 [双列集合]
//牌是string类型的,编号是integer类型的
HashMap<Integer, String> poker_map = new HashMap<>();
//定义一个poker的初始的编号
int id = 1;
//准备花色和数字
String[] color_arr = "♠️,♥️,♣️,♦️".split(","); //用split切开
String[] num_color = "2,3,4,5,6,7,8,9,10,A,J,Q,K".split(",");
//组合数组加花色
for (String num : num_color) {
for (String color : color_arr) {
//花色和数字拼接成了牌,得到一张牌
String poker = color+num;
//把牌存放到map集合的value上,key是牌的编号
//将得到的牌放到容器里面
poker_map.put(id++, poker); //id为编号
}
}
poker_map.put(id++, "大王");
poker_map.put(id++, "小王");
System.out.println(poker_map);//加上大小王得到完整的有顺序的一副牌
//第二步:洗牌
//使用shuffer方法洗牌
Set<Integer> keySet = poker_map.keySet();// 双列集合变为单列集合,需要将编号打乱
System.out.println(keySet);//得到有顺序的编号
//需要把set集合转变为list集合,这个集合是放编号的
ArrayList<Integer> list = new ArrayList<>();
list.addAll(keySet); //将set集合放到list集合里面
Collections.shuffle(list);//需要一个list 集合
System.out.println(list);// 打乱编号
//第三步:发牌
//发的是底牌都是牌的编号所以是integer类型,接收的容器,底牌需要容器,玩家也需要容器 list容器
ArrayList<Integer> dipai_list_id = new ArrayList<>();
ArrayList<Integer> baobao_list_id = new ArrayList<>();
ArrayList<Integer> nailiang_list_id = new ArrayList<>();
ArrayList<Integer> yufan_list_id = new ArrayList<>();
//通过索引来发牌,发的是list编号
for (int i = 0; i < list.size(); i++) {
//先把最后的三张牌留作底牌,需要容器所以在发牌之前需要有接收的容器
if(i >= 51) { //如果角标大于等于51,52/53/54留作底牌
dipai_list_id.add(list.get(i)); //留三张底牌
}else if(i % 3 == 0) { //对3取余,第一张牌的索引为0,i 为索引值,打乱顺序后根据索引整除3的逻辑进行取牌,因为是3个人所以用3进行整除
baobao_list_id.add(list.get(i)); // 发给第一个人,第一个人的牌
}else if (i % 3 == 1) { //除3取余等于1
nailiang_list_id.add(list.get(i));//等于1的时候发给第二个人
}else if(i % 3 == 2) {//除3取余等于2
yufan_list_id.add(list.get(i)); //如果前面的都不满足的话就发给第三个人,这里遍历完里面都是索引值
}
}
//第四步:看牌
//看牌的时候只要把编号换成对应的牌就可以了
System.out.print("羽凡的牌:"); // yufan_list_id里面是索引的集合
for (Integer integer : yufan_list_id) { //遍历羽凡的牌,遍历一个编号得到一个对应的牌,对应的每一个索引都有相应的牌,总共54个索引值
System.out.print(poker_map.get(integer)+" "); //拿到的牌,打印的时候不能换行,get(integer),就相当于get(key)值
}
System.out.println();
System.out.print("乃亮的牌:");
for (Integer integer : nailiang_list_id) {
System.out.print(poker_map.get(integer)+" ");
}
System.out.println();
System.out.print("宝宝的牌:");
for (Integer integer : baobao_list_id) {
System.out.print(poker_map.get(integer)+" ");
}
System.out.println();
System.out.print("底牌:");
for (Integer integer : dipai_list_id) {
System.out.print(poker_map.get(integer)+" ");
}
}
}