在Hive中,ORDER BY语句是对查询结果集进行整体的排序,最终将会产生一个reducer进行全局的排序,达到的最终结果是和传统的关系型数据库是一样的。
在数据量非常大的时候,全局排序的单个reducer将会成为性能瓶颈,有可能由于数据量过大而跑不出来结果。
Hive中可以设置hive.mapred.mode为strict严格模式,这时候,Hive要求用户必须对order by语句加上limit 条数限制,防止排序数据集过大导致性能瓶颈。
在这里我不提sort by ,distribute by的用法,下一节好好分析下这几个语句的用法。我主要讲下Hive的order by 与oracle 的order by的不同点。
同样是一个emp雇员表。我希望执行如下查询:
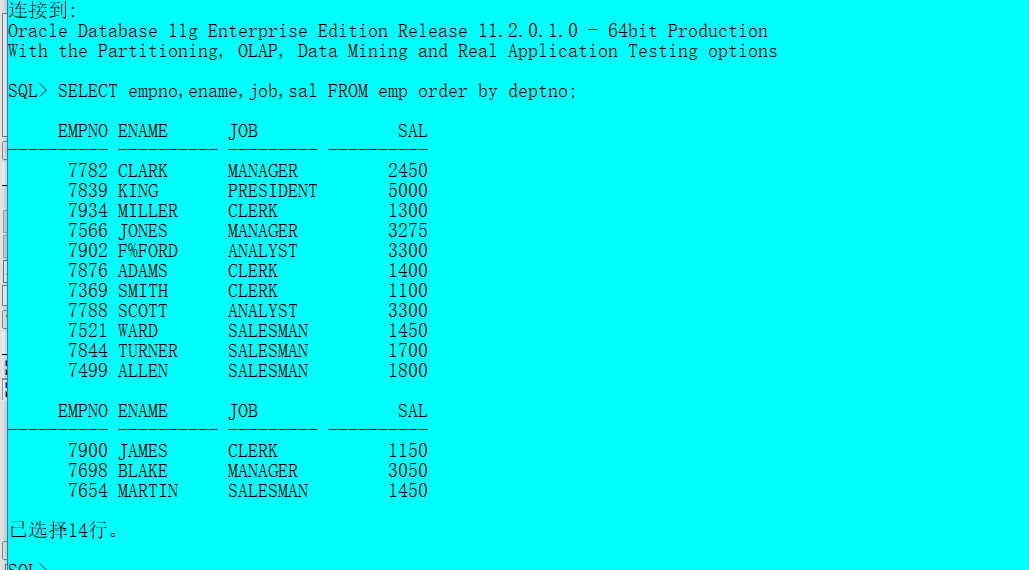
SELECT empno,ename,job,sal FROM emp order by deptno;
这个语句中,order by排序引用的列在不是select查询的列,在大多数的关系型数据库中执行是没有问题的,但是在Hive中执行就会出问题,效果如下:
在Oracle sqlplus中执行效果如下:
在Hive中执行却报错:

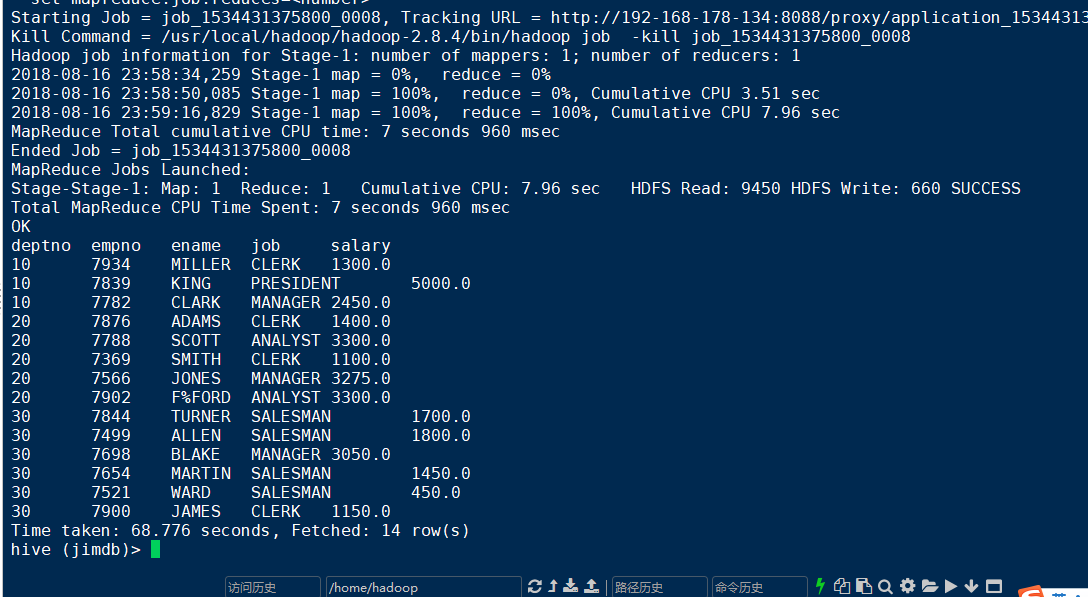
在HIVE中,order by语句只能引用select查询的列,这一点我觉得是有待改进的地方。
我在查询列表中加上deptno后,才能正常执行,这一点大家在写Hive SQL的时候需要注意,或许后续版本会对这个bug进行改进,我当前用的是Hive 2.3.3版本。
排序列如果来自于select 后的选择列的时候就不会报错,如下:
select deptno,empno,ename,job,salary from emp order by deptno;