作为一个AI打工人怎么能少得了在服务器端推理的框架TensorRT呢,但是安装过的打工人知道,各种依赖,是让人抓狂,那今天我来说一套我的方法
原理:GPU + nvidia-docker2 + tiny-TensorRT
先说下笔者的硬件环境(其实就是想秀波GPU)
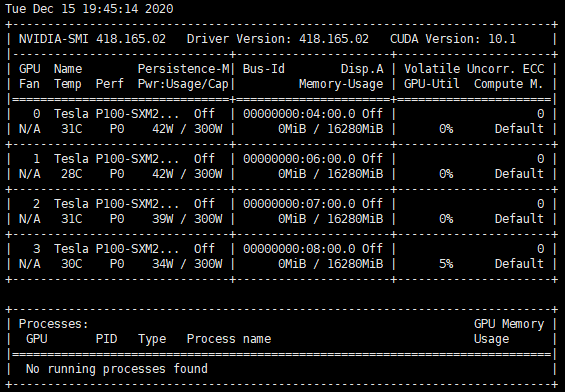
首先给服务器安装驱动
不用安装cuda、cudnn等,具体请看笔者上篇博客 https://www.cnblogs.com/nanmi/p/14132105.html
安装docker
既然使用容器化的东西,得安装docker吧,版本安装最新的就好了,网上教程一大堆就不写了。
安装nvidia-docker2
安装过程可以参考bewithme大神的博客https://blog.csdn.net/bewithme/article/details/105092159 如果是别的系统的请百度对应的安装方法,笔者宿主机是CentOS
测试安装的是否能在容器中调用GPU不用按照网上教程直接下载nvidia/cuda镜像,太大了,可以下载相应的tag版本,比如笔者这个就挺好才100多M
测试方法:
$ docker run --runtime=nvidia --rm nvidia/cuda:10.0-base nvidia-smi
有输出显卡的使用内容即成功
启动tensorrt容器
$ docker pull venalone/tensorrt7:cuda10.2
$ docker pull nvcr.io/nvidia/tensorrt:20.12-py3
$ docker run -itd --name my_tensorrt_env --runtime=nvidia -p 0.0.0.0:xx:22 venalone/tensorrt7:cuda10.2 /bin/bash
$ docker run -itd --name my_tensorrt_env --runtime=nvidia -p 0.0.0.0:xx:22 nvcr.io/nvidia/tensorrt:20.12-py3 /bin/bash
进容器先看看
发现在容器的/usr/local/下cuda也有了,tensorrt也有了,此时python也没有建立软连接的,但是已经在/usr/local/bin下有python3了
开发环境都建立好了,那我要怎么开发呢,开发tensorrt C++可是很烦人呢,有人说那儿哦用tensorrt python API啊,实际上,我接触到的是,大家没人用python来做推理,那C++ API又很复杂,python API又应用不广泛,
怎么办呢?答案是tiny-TensorRT,GitHub项目地址 https://github.com/zerollzeng/tiny-tensorrt,这是大神Ren Zeng 在nvidia tensorrt C++ API的基础上做了分装,使得我这种混子之类的可以站在巨人的肩膀上开发
下载项目及子模块
$ git clone --recurse-submodules -j8 https://github.com/zerollzeng/tiny-tensorrt.git $ cd tiny-tensorrt
该项目包含几个部分:

cmake:定义了project CMakeLists.txt去查找你系统的架构、cuda等的函数
plugin:是当模型的某些OP不被支持,这是很常见的事情,自定义的插件代码,里面又三个示例,插件才是灵魂啊!!!
pybind11:项目作者不仅考虑到C++作为入口,同时也考虑到python作为入口,这样主体是C++的发挥其性能和灵活性,入口却是python入口,果然是大神,膜拜。
spdlog:是输出日志,打印等函数的分装,这样使用起来就好用了。
test:是测试调用该框架是最终是如何使用调用的呢,真的分装很好了,极简单了。
另外几个文件:Int8Calibrator.cpp和其同名头文件是用来做INT8单精度量化的,不了解原理的可以百度下,量化单精度时是分为饱和量化和不饱和量化,网络模型的weight是做不饱和的量化(对称量化),按比例压缩到±127,而对每一层的响应做的是饱和量化,又叫非对称量化,总之int8的模型weight是做不饱和量化,响应(激活值做饱和量化),这个会涉及到KL散度(相对熵),具体可参考我的另外稍早时候的博客,有对量化做详细说明https://www.cnblogs.com/nanmi/p/13607515.html
PyTrt.cpp是为了做C++和python绑定用的,入口
Trt.cpp和Trt.h是代码的核心之一,可以详细阅读
utils.h是定义了一些简单的小工具的组件头文件引用就可以
编译
首先在/etc/profile配置环境变量
export CUDA_HOME=/usr/local/cuda export PATH=$CUDA_HOME/bin:$PATH export LD_LIBRARY_PATH=$CUDA_HOME/lib64$LD_LIBRARY_PATH export TENSORRT_HOME=/usr/local/TensorRT-7.0.0.11/ export CPLUS_INCLUDE_PATH=$CPLUS_INCLUDE_PATH:${TENSORRT_HOME}/include export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:${TENSORRT_HOME}/lib export LIBRARY_PATH=$LIBRARY_PATH:${TENSORRT_HOME}/lib export PATH=$PATH:${TENSORRT_HOME}/bin
然后编译
修改CMakeLists.txt中放开编译python、test的选项ON
$ cd tiny-tensorrt $ mkdir -p build && cd build $ cmake .. $ make -j32
编译完成后,会产生libtinytrt.so结合Trt.h只需要这两个就可以完成对该封装的使用,使用示例在test文件夹下
Reference
[1] https://github.com/zerollzeng/tiny-tensorrt
[2] https://github.com/zerollzeng/tiny-tensorrt/blob/master/docs/CustomPlugin-CN.md