介绍
1997年麻省理工大学学生研究的数据模型,被计算机实现到代码中了--hash一致性;本质来讲是一种散列算法;
将计算机中的数据,投影(mapping)计算到一个0-43亿正整数的区间(hash环)
key值和node节点的信息,都会做散列计算
node节点的信息,是一个字符串对象"10.9.9.9:6379",这个对象完成hash一致性的散列计算,获取一个整数值
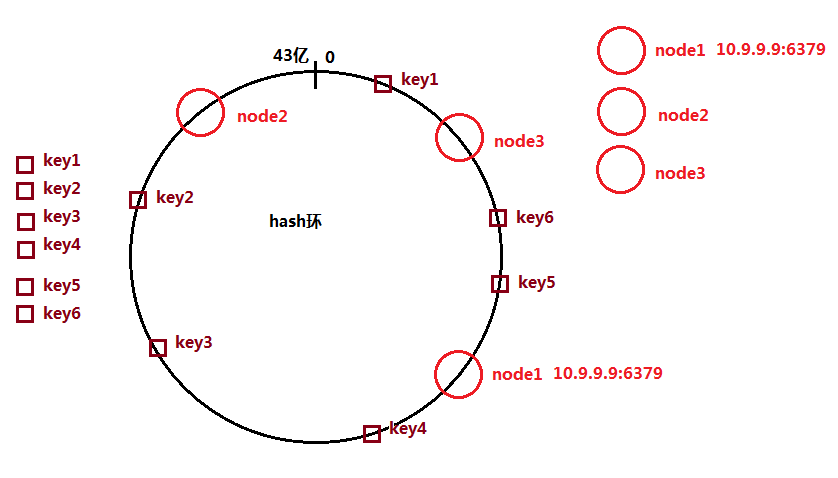
key值与节点的对应关系,可以通过hash环上的映射整数结果来计算;
key值的映射整数,顺时针寻找最近的节点的整数值,增删改查,都到这个节点来完成;
node1对应key:key6,key5
node2对应key:key2,key3,key4
node3对应:key1
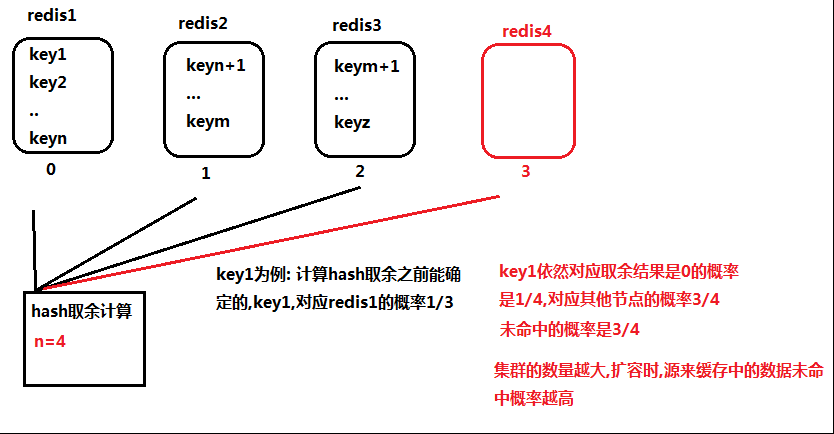
对比一下hash取余算法
缺点:节点数量变化(扩容),数据的未命中概率增高(缓存雪崩容易出现);集群节点数量越多;
未命中概率越高,造成缓存击穿
hash一致性的增加扩容节点
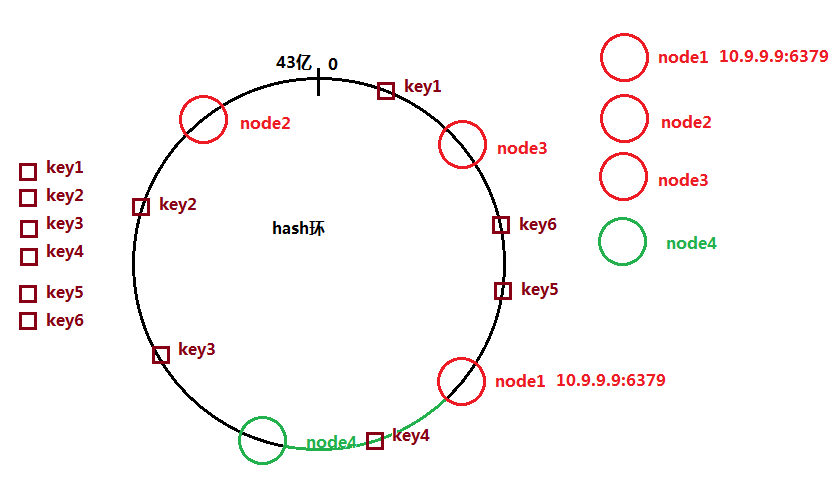
当node4添加进来之后,依然做散列计算,映射到环中某个整数;
只有绿色弧线对应的key值在查询获取时未命中,
集群节点数量越多的时候,被切分开的弧线的长度越小(未命中的key越少)
数据的平衡性保证
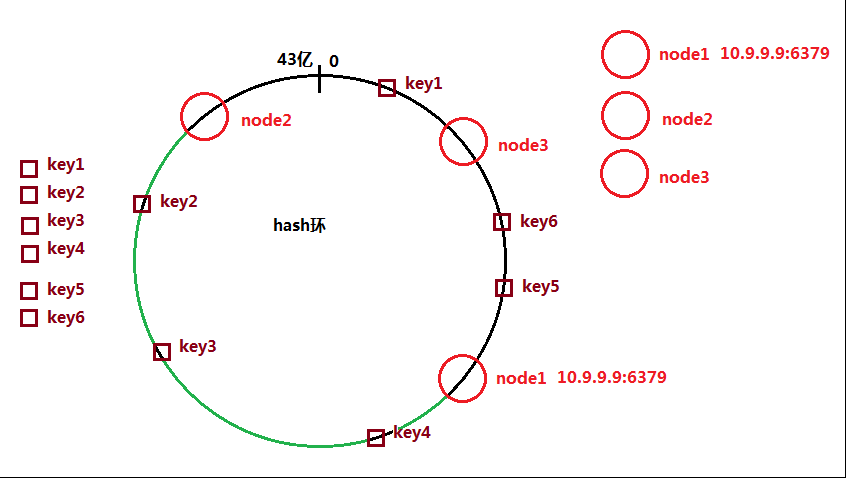
绿色弧线的key值都被对应存储到node2,导致node2的数据管理严重倾斜(不平衡);
代码中(jedis)引入了虚拟节点的概念;