文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/。
1.一个项目中的真实问题
实际项目中,本想通过C#制作小工具生成SHP的二进制空间索引文件,然后java服务端解析该空间索引文件进行使用。
在真实使用中发现java端解析的该文件内容与C#写入的差别非常大,比如java中解析到的double均为非常大的负数。

2.排查问题
2.1 测试是否C#写入有误
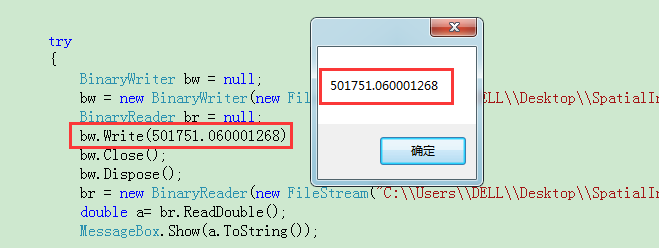
检查写入的值在C#中解译为正确。
2.2 编码错误
用java生成相同的文件,编码与C#生成文件的编码一样,但是内容不一样,所以本身不是编码错误导致。

2.3 总结
推断出,错位原因为C#写入的值和Java写入的值不一样。
3.错误原因
a.C#中byte范围是[0,255],而Java中的byte范围是[-128,127]。
b.C#中的字节排序为低端排序,但是Java中的字节排序为高端排序。比如double值在java中是如此存储的:writes that long value to the underlying output stream as an 8-byte quantity, high byte first。
4.解决思路
4.1 描述
利用C#中的sbyte[-128,127],将C#中存入的byte数组进行倒置,然后再将各byte准换至sbyte,最后整体存入该sbyte数组。
4.2 具体实现代码



5.结果验证
C#中写入:

Java中读取:
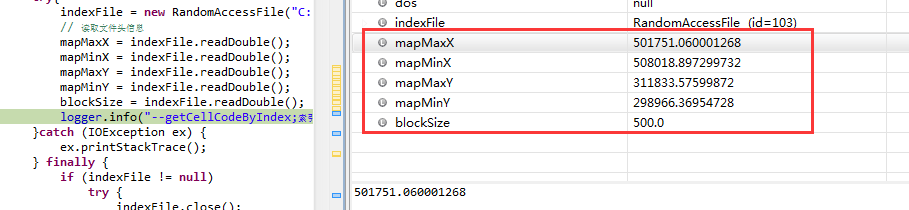
结果一致。
6.关于写入string的问题
大家如果用C#将string变成二进制写入到文件中时,会发现Java写入相同的string值生成的文件大小比C#的小,这是为什么呢?
查看Java中写入string二进制的说明:Writes the string to the file as a sequence of bytes. Each character in the string is written out, in sequence, by discarding its high eight bits。
可见其写入的字符,默认为ANSI编码,即只有一个字节,同时其字节排序仍然是高位排序。发现这点后,我们可以对C#中写入字符串进行重写:

-----欢迎转载,但保留版权,请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/
如果您觉得本文确实帮助了您,可以微信扫一扫,进行小额的打赏和鼓励,谢谢 ^_^
