文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/。
1.背景
目前跟信息采集相关的一个项目提出了这样的一个需求:中国银行等一些部门和政府关系较好,需要在兴趣点搜索时优先显示他们。
我们的兴趣点查询是使用的Lucene进行分词查询的,这涉及到我们要对我们搜索出来的结果进行一次优先级排序。这里,我和大家一起探讨解决此问题的两种方案。
2.字典创立时对字典文档设置优先级
2.1.通过Document的setBoost来建立文档优先级
在Lucene4.0前,Document可以通过setBoost来设立文档的优先级。流程图为:

但是,此方法在Lucene4.0之后不能使用,因为此之后去掉了Document可以直接setBoost的方法。
2.2.通过对数据源进行排序来解决建立字典文档优先级
在项目中,数据存放在数据库中,索引是建立在数据库的该兴趣点表上,于是我们可以改变我们的思路,即直接对查询所得的数据先进行排序,然后再建立索引。
下面我们具体讲下实施方案。
2.2.1.修改兴趣点表,增加排序字段

这里,我们增加了一个ORDERINDEX排序字段。
2.2.2.在代码中对数据源进行排序,然后生成字典
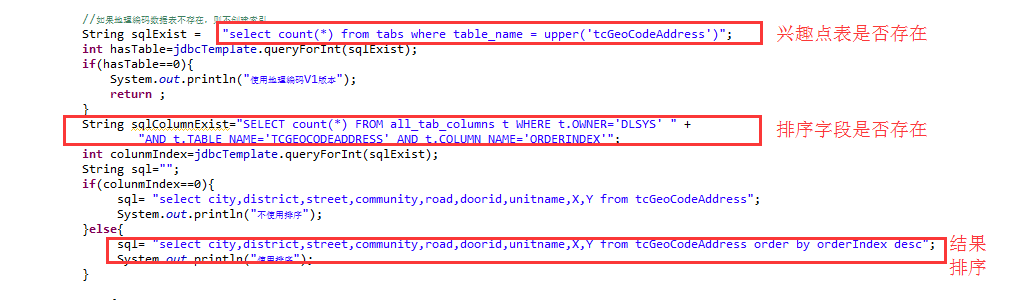
2.2.3.测试例子
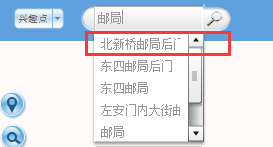
符合邮局关键字段的数据有多个,我们将北新桥邮局后面的ORDERINDEX修改为1,如果我们输入邮局,能将北新桥邮局后门首先返回,则表示方法成功。

结果展示:
3. 分词查询时,通过设置query 影响排序
3.1.思路分析
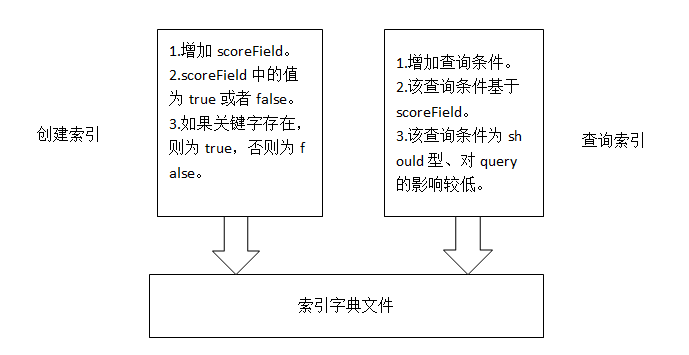
我们首先可以在创建Document时,增加一个field。该field默认值为false。当我们需要创建的字符串满足优先查询字符串时,则将该field的值改为true.
然后,再创建查询条件时,增加一个建立在field的查询条件,该查询条件为should型,查询值为true,并且设置其对query的影响为低。
流程图为:
3.2.具体实现
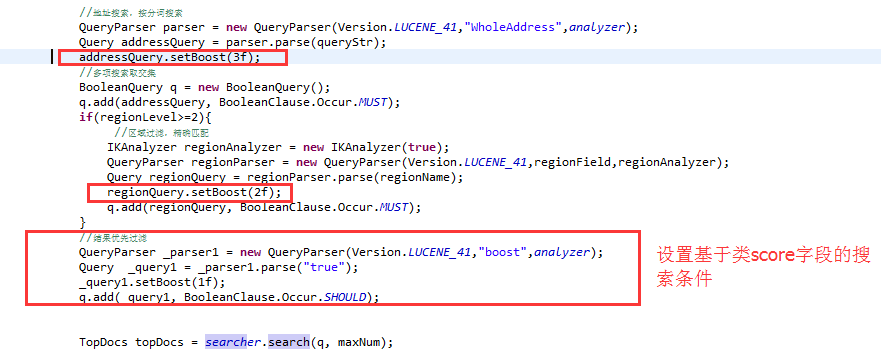
3.2.1增加类score字段

3.2.2增加query影响条件
4.总结
在代码中通过setBoost有如下几个缺点:
a.增加了代码开发量
b.在构建索引字典中遍历是否满足优先条件,比较耗时。
鉴于以上缺点,选择直接通过数据源排序构建索引字典是比较好的方式。
5.扩展
由于Lucene中分词的粒度很难控制,比如邮局二字。当我们输入邮或者邮局时,是可以有查询结果的。但是输入局时却不能。
针对此种问题,基于Lucene的分词条件进行修改和扩展,是能根本解决问题的方法之一,但是学习成本略大。
此处我选择了一种折中的方式来解决,即分词查询后判断查询结果是否为空,如果是空,则触发数据库查询。
当然,触发数据库查询的前提是,兴趣点不能过多。一般项目中兴趣点均在10W以内,所以数据库查询消耗时间是有限的。
而为什么不直接使用数据库查询是在于:
a.分词查询可以加速查询效率。
b.分词查询避免数据库查询使用过多的like关键字。
c.分词查询可以建立对拼音检索的支持。
-----欢迎转载,但保留版权,请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/
如果您觉得本文确实帮助了您,可以微信扫一扫,进行小额的打赏和鼓励,谢谢 ^_^
