Schema的快速入门

如果是简单元素直接 <element name=”” type=””></element>

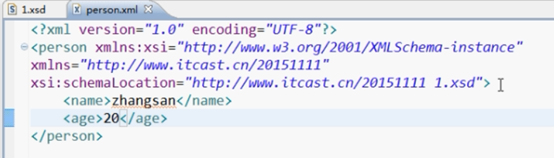
Schema开发过程:



Sax 解的析原理
解析xml有两种技术 dom 和sax
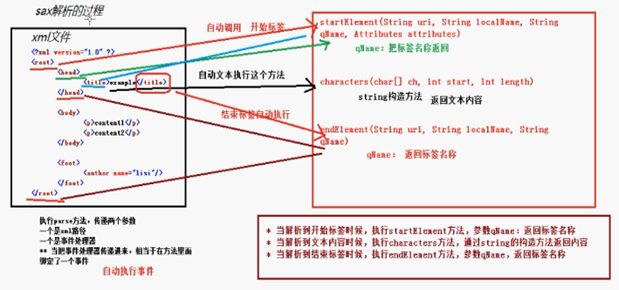
4使用jaxp的sax方式解析xml
**Sax方法不能实现增删改查,只能做查询操作
**打印出整个文档
**执行parse方法,第一个参数xml路径,第二个参数 是事件处理器
**创建一个类,继承事件处理器的类
**重写里面的三个方法
*获取到所有name元素的值
/* * 1创建一个解析器工厂 * 2创建解析器 * 3执行 parse方法 * * 4自己创建一个类,继承DefaultHandler * 5重写里面的三个方法 */ //获取所有name class Mydefault2 extends DefaultHandler{ boolean flag = false; int idx = 1; @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { //判断qName是不是name元素 if("name".equals(qName)){ flag = true; } } @Override public void characters(char[] ch, int start, int length) throws SAXException { //当flasg为true的时候,表示解析name元素 //索引值是1 if(flag == true && idx == 1){ System.out.println(new String(ch,start,length)); } } @Override public void endElement(String uri, String localName, String qName) throws SAXException { //把flag设置为false,表示name元素结束 if("name".equals(qName)){ flag = false; idx++; } } }
5使用dom4j解析xml
*dom4j 是一个组织,针对xml解析,提供解析器dom4j
*不是javase 的一部分, 想要使用第一步怎么使用?
**导入dom4j提供的

6 使用dom4j查询xml’
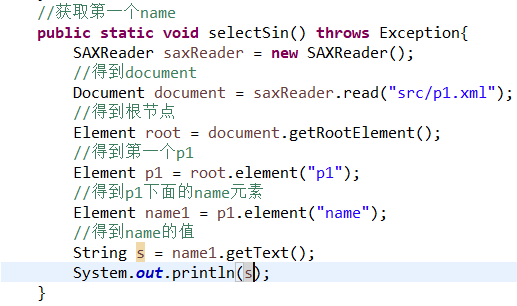
查询所有name元素里面的值
1创建解析器
2得到一个·document
3得到根节点 getRootElement()
4得到所有的p1标签
*element(qname)
**获取标签下第一个子标签
**qname 标签名称
*elements(qname)
**获取标签面是这个名称所有子标签(一层)
**qname 标签名称
*elements()
**获取标签下面的所有子标签
5得到name
6得到name里面的值

7使用dom4j添加节点
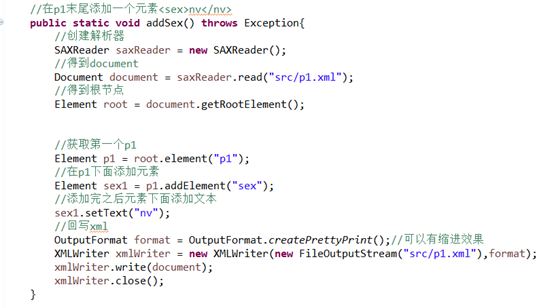
8特定位置添加节点
//特定位置添加元素 public static void addAgeBefore() throws Exception{ //1创建解析器 // SAXReader saxReader = new SAXReader(); //2得到document // Document document = saxReader.read(Dom4jUtils.PATH); Document document = Dom4jUtils.getDocument(Dom4jUtils.PATH); //3得到根节点 Element root = document.getRootElement(); //4获取第一个p1 Element p1 = root.element("p1"); //5获取p1下面所有的元素 /* * element()方法 返回list集合 * 使用list方法 ,在指定位置添加元素 * *** add(int index,E element) * -第一个参数是 位置下标 ,从0开始 * -第二个参数是 要添加的元素 *6回写xml */ //5 List<Element> list = p1.elements(); //创建元素使用 Element school = DocumentHelper.createElement("school"); //在school下面创建文本 school.setText("ecit"); //特定位置添加 list.add(1, school); //回写 Dom4jUtils.xmlWriters(Dom4jUtils.PATH, document); }
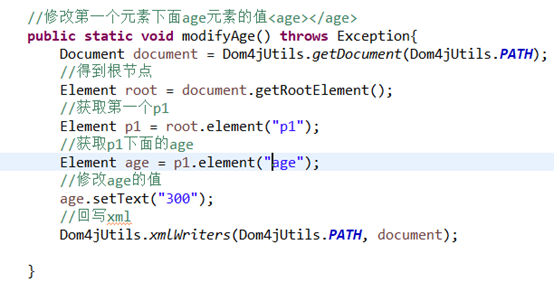
9修改
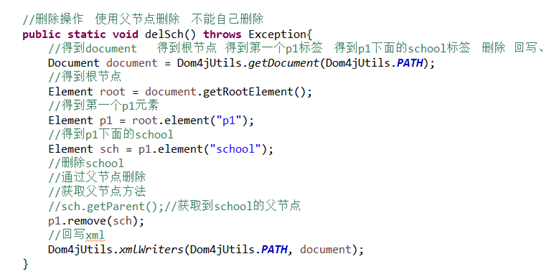
10删除
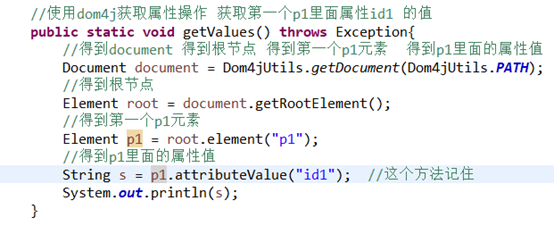
11获取属性
12使用dom4j支持xpath的操作
