gh-ost原理
一、三种模式架构图
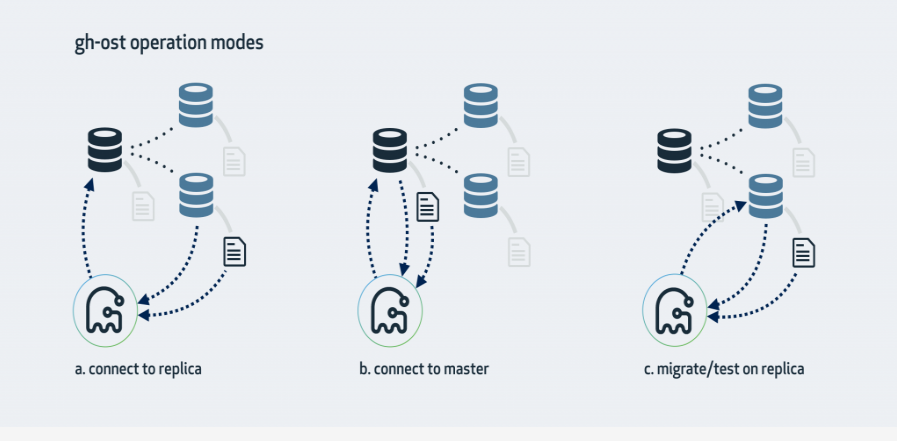
1、连上从库,在主库上修改
这是gh-ost默认的工作模式,它会查看从库情况,找到集群的主库并且连接上去,对主库侵入最少,大体步骤是:
在主库上创建_xxx_gho、_xxx_ghc,并修改_xxx_gho表结构;
从slave上读取二进制日志事件,将变更应用到主库上的_xxx_gho表;
在主库上读源表的数据写入_xxx_gho表中:insert into igore....select;
在主库上完成表切换;
2、直接主库修改
在主库上创建_xxx_gho、_xxx_ghc,并修改_xxx_gho表结构;
从主库上读取二进制日志事件,将变更应用到主库上的_xxx_gho表;
在主库上读源表的数据写入_xxx_gho表中:insert into igore....select;
在主库上完成表切换;
3、在从库上修改和测试
这种模式会在从库上做修改。gh-ost仍然会连上主库,但所有操作都是在从库上做的,不会对主库产生任何影响。在操作过程中,gh-ost也会不时地暂停,以便从库的数据可以保持最新。
--migrate-on-replica选项让gh-ost直接在从库上修改表。最终的切换过程也是在从库正常复制的状态下完成的。
--test-on-replica表明操作只是为了测试目的。在进行最终的切换操作之前,复制会被停止。原始表和临时表会相互切换,再切换回来,最终相当于原始表没被动过。主从复制暂停的状态下,你可以检查和对比这两张表中的数据。
二、原理
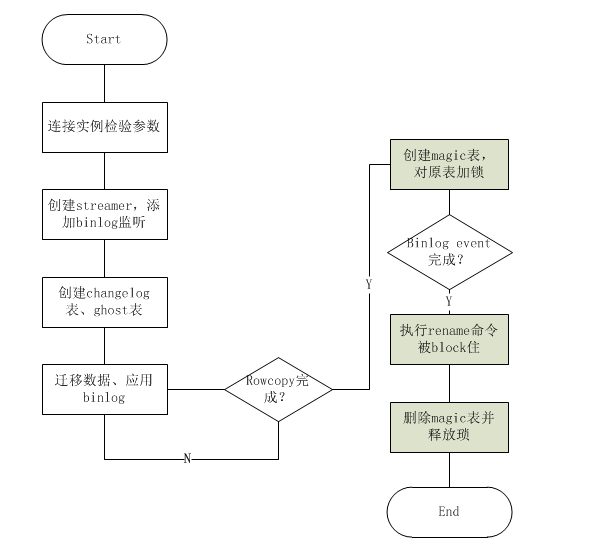
1、检查校验环境
测试db是否可连通,并且验证database是否存在
确认连接实例是否正确
权限验证 show grants for current_user()
binlog验证,包括row格式验证和修改binlog格式后的重启replicate
原表存储引擎,外键,触发器检查,行数预估等
2、创建binlog streamer连接到主库或者从库,添加binlog的监听
3、创建log表_xxx_ghc和ghost表_xxx_gho并修改ghost表结构到最新
4、开始迁移数据:row copy和binlog apply同时进行
1)最小值:select `id` from darren`.`t4` order by id` asc limit 1;
2) 最大值:select `id` from darren`.`t4` order by id` desc limit 1;
3) 计算第一个chunk: select `id` from `darren`.`t4` where `id` >= _binary'1' and `id` <= _binary'58594' order by `id` asc limit 1 offset 999
最后一个chunk如果不足1000,那么上面sql查询为空,这时运行:
select `id` from (
select `id` from `darren`.`t4`
where `id` > _binary'58000' and `id` <= _binary'58594' order by `id` asc limit 1000
) select_osc_chunk
order by `id` desc limit 1;
4)循环插入数据:insert ignore into `darren`.`_t4_gho` (`id`, `name`, `c1`)
(select `id`, `name`, `c1` from `darren`.`t4` force index (`PRIMARY`)
where `id` >= _binary'1' and `id` <= _binary'1000' lock in share mode
)
4.1、rowcopy数据和应用binlog顺序不同是否产生数据冲突
数据迁移过程中sql映射关系:
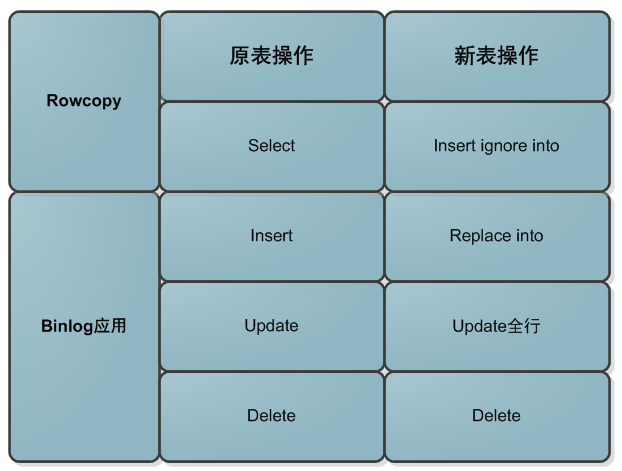
rowcopy和binlog应用各种排列组合:
数据迁移过程,涉及三个操作:A:对原表进行rowcopy;B:应用程序的DML;C:应用binlog到新表,因为DML操作才会记录binglog,所以C操作一定在B操作的后面,共有如下几种组合:
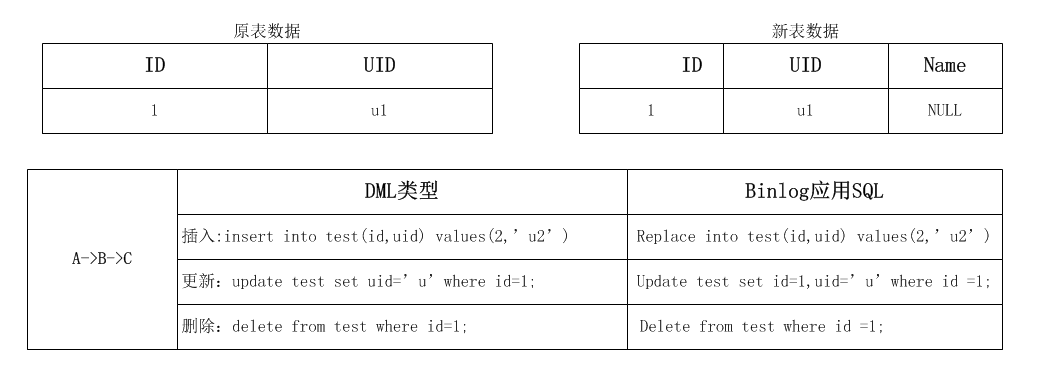
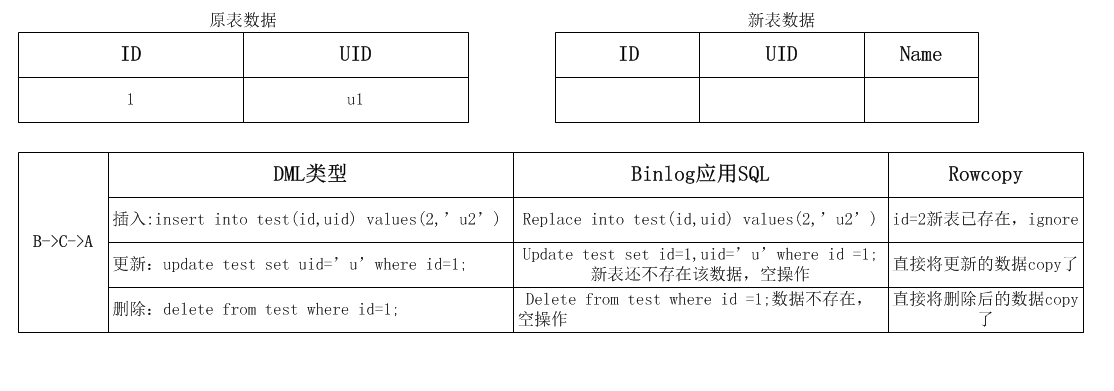
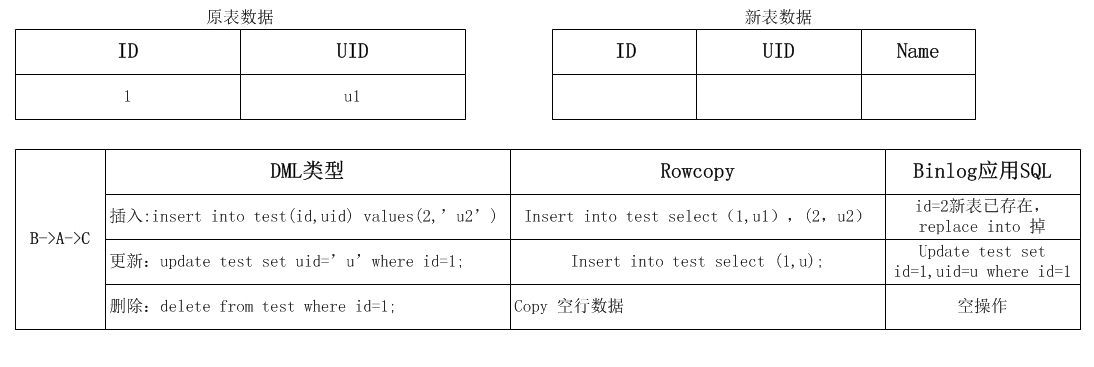
1.insert 操作
binlog是最权威的,gh-ost的原则是以binlog优先,所以无论任何顺序下,数据都是和binlog保持一致,如果rowcopy在后,会insert ignore,如果binlog apply在后会replace into掉。
2.update/delete 操作
对已经rowcopy过的数据,出现对原表的update/delete操作。这时候会全部通过binlog apply执行,注意binlog apply的update是对某一条记录的全部列覆盖更新,所以不会有累加的问题。
对尚未迁移的数据,出现对原表的update/delete操作。这时候对新表的binlog apply会是空操作,具体数据由rowcopy迁移。
特殊情况下:
先对原表更新完以后,rowcopy在binlog apply之前把数据迁移了过去,而在binlog event过来以后,会再次应用,这里有问题?其实结合gh-ost的binlog apply之前把数据迁移了过去,
而在binlog的sql映射规则,insert操作会被replace重新替换掉,update 会更新对应记录全部行,delete 会是空操作。最终数据还是一致的状态。
4.2、binlog同步数据何时结束?
copy完数据向_xxx_ghc写入status:AllEventsUpToLockProcessed:1533533052229905040,当binlogsyncer过滤到该值表示所有event都已应用
5、copy完成后进行原子性cut-over阶段
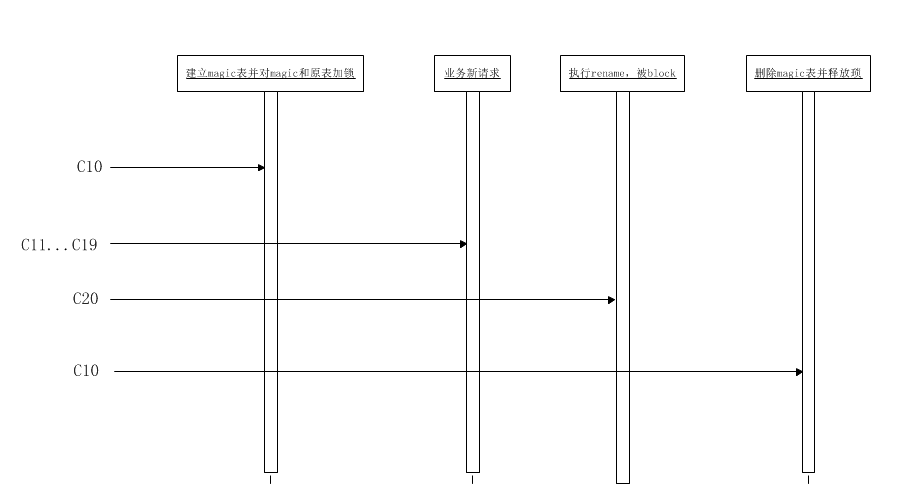
5.1) C10:
创建magic表_xxx_del,目的为了防止过快的进行rename操作和意外情况rename
对源表和magic表_xxx_del加write锁
5.2) C11...C19: 新的请求进来,关于原表的请求被blocked
5.3) C20: 执行:rename table `t4` to `_t4_del`,`_t4_gho` to `t4`;这时被阻塞,timeout:3s。(这一步只有binlog event应用完成后)
5.4) 检查是否有blocked 的RENAME请求,通过show processlist
5.5) C10:
删除magic表(只有show processlist里存在被block的rename才进行)
释放琐
不同阶段失败后如何处理:
如果5.1失败,退出程序,比如建表成功,加锁失败,退出程序,未加锁
rename请求来的时候,会话C10死掉,lock会自动释放,同时因为_xxx_del的存在rename也会失败,所有请求恢复正常
rename被blocked的时候,会话C10死掉,lock会自动释放,同样因为_xxx_del的存在,rename会失败,所有请求恢复正常
C20死掉,gh-ost会捕获不到rename,会话C10继续运行,释放lock,所有请求恢复正常
6、清理战场
7.1) 关闭binlogsyncer连接
7.2) 删除源表和_t4_ghc表