3.1.1 什么是document
在solr中,document是保存数据的基本单位,是由一组相关的数据元素组成的元素集合。
document由field组成。field称之为文档的字段。若干个field代表了document是由若干个不同意义的数据元素组成的。一个document可以由1个或多个field组成。
每个field都会有一个fieldType(字段类型),fieldType定义了当前field数据的数据类型(int,string,long,doule,tdouble,text等等)
3.1.2 基本的搜索问题
如果要查询一本关于如果购置房产的书籍,我们可能会这样搜索:
搜索关键字:buy a home
如果用SQL的方式来检索数据库中的书籍名称列表,那么,书籍的完整名称必须是“buy a home”,否则将检索不到。如果改进一下SQL,用如下来做检索:
%buy a home%
这样,虽然扩大了搜索的范围,只要书名中包含“buy a home”,也是可以检索到,但是匹配的单词顺序依然要符合"buy a home",只是它的前面和后面可以有其他词了。再改进:
%buy% %a% %home%

这样,就可以完整的匹配搜索关键字中的所有单词,但是这样也会匹配出很多完全无关的书名,例如:
"how to cook a duck" "buy a plane" "decorating your home" 等等.....
显然,这些书不是我们想要的。所以这样的问题,就需要由搜索引擎来解决。solr就是解决这种问题的。
solr可以对提交给他的内容以及查询请求进行词分析,从而确定意义相近的词汇,理解并匹配这些意义相似的词,并且可以忽略掉一些不相干的词,例如:"a","the","of"等等。并根据搜索出的结果与查询请求关键字的匹配程度作出评分,这样可以保证最接近搜索本意的结果排在最前面,确保了用户不会在无数的结果中去确定哪条才是他真正需要的。
当文档发送给solr后,根据文档中的字段,分析器按照字段定义的数据类型对字段的数据进行解析处理,原始数据的类型被解析成确切的数据类型之后就被保存到索引中了,这样以后需要搜索该文档时,就能以这个索引值做为关键字去搜索。
一般情况,字段的数据类型只有text类型需要专门指定分析器。其他数据类型的分析器都是默认在org.apache.solr.analysis包中。例如int型,对应在analysis包中的class就是int.class。在定义字段类型的时候只要在class属性中指定即可。例如:<fieldType name="int" class="solr.TrieIntField"/>
3.1.3 倒排索引
solr利用Lucene's的倒排索引增强了自己快速搜索的能力。在搜索时提供了许多很好用的附加功能。但这里并打算深入探讨关于Lucene的数据结构。
一个传统的数据库保存多文档结构的实现方法通常以一个文档的ID为索引,ID对应它的表记录,每条记录就是一个文档,文档的内容中包扩了这个文档所有的词(正排索引)。而倒排索引刚好与此相反。倒排索引是以词为索引,词对应着表记录,每条记录就是一个文档ID以及词在该文档中的位置。正排索引是从文档到关键字的映射(已知文档求关键字),倒排索引是从关键字到文档的映射(已知关键字求文档)。

将要被solr索引的字符串首先通过内容解析被分词器分割成单个的词,在插入倒排索引之前每个词被转换为小写字母,其他的都保持不变。值得注意的是,还有其他一些其他的词转换功能,不仅仅是这些简单的功能。字符串在被执行解析时,可以对词进行修改,增加或删除。具体的执行细节在第六章讲解。
最终,有两点细节是:
1.所有被索引的词,都映射到一个或多个文档
2.倒排索引的这些词都是按升序排列储存的
3.1.4 词、短语和布尔逻辑
我们已经清楚了Lucene的倒排索引是什么样的了,现在我们学习请求如何利用索引去匹配文档的机制。在这一节,将复习在倒排索引中搜索单词和短语以及利用布尔逻辑和模糊查询去扩展搜索功能。
在上一个节中,内容中的所有词都被分成独立的词保存到了索引中。假如搜索:“new home”,那么有以下3种情况需要考虑:
1.检索两个词,“new”和“home”。要求文档必须这两个词都匹配到
2.检索两个词,要求只匹配到其中一个就算满足条件
3.检索确切的短语 “new home”
必须词
第一种情况进行测试。把请求字符串进行拆分为两个词,并要求两个都匹配。在solr中,有两种意义相同的语法格式来描述请求:
1.+new +home
2.new AND home
这两个格式在处理逻辑上是相同的,但是,第二种格式在solr的请求解释器中最终会被解析成第一种格式。一元操作符“+”,表示它后面紧跟着的词必须存在于匹配到的任何文档中。二元操作符“AND”,表示紧跟在他前面和他后面的词都必须存在于匹配到的任何文档中。
可选词
对比“AND”操作符,“OR”也是一个二元操作符。表示匹配到的文档必须包括操作符之前或之后的任意一个词。solr默认任何请求的字符串中,如果两词之间没有显式声明一个操作符,那么就默认这两个词为可选词,例如:
1.new home
2.new OR home
否定词
除了设置请求字符串中的词为必须词或可选词外,还可以设置否定词。通过设置否定词,查询返回的文档中将被要求不能包含这个词。两个意义相同的语法格式:
1.new home -rental
2.new home NOT rental
这样,任何不包含rental,但包含了new或home的文档将会被返回。
SOLR 默认操作符
solr默认的操作符是or.可以通过q.op来设置默认操作符。例如:
/select/?q=new house&q.op=OR versus /select?q=new house&q.op=AND
- q.op - 覆盖schema.xml的defaultOperator(有空格时用"AND"还是用"OR"操作逻辑),一般默认指定OR
也可以在query字符串中指定操作符,这样会覆盖掉默认操作符。
短语
Solr不仅可以查询单个的词,也可以查询短语。但是在索引中只包含了独立的关键字,那么,对短语进行查询是如何工作的呢?在短语中的每个关键字依旧独立地使用 Lucene 索引进行查询。具体机制:http://www.tuicool.com/articles/jqQJrm
- “new home” OR "new house"
分组表达式
除了之前学习到的请求表达式格式以外,还有一种表达式格式,叫是分组表达式。分组表达式格式如下:
1.New AND (house OR (home NOT improvement NOT depot NOT grown)
2.(+(buying purchasing -renting) +(home house residence –(+property - bedroom)))
solr通过这些布尔逻辑操作符提供给用户一个强大灵活的查询功能。
总结:
OR 两个词的并集 + 单个词在文档中必须存在 AND 两个词的交集 NOT(-)单个词在文档中必须不存在
3.1.5 查找多个文档
基于以上词、短语、布尔逻辑操作符的基础概念,我们进一步来学习Solr究竟如何去利用倒排索引去查找匹配的文档
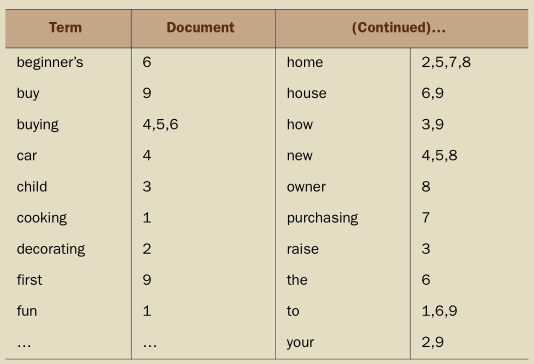
如果某个用户提交了对字符串“new home”的查询,鉴于Lucene的倒排索引机制,solr会如何去找到匹配查询字符串的文档?“new home”是一个两个词组成的一个查询。之前我们学习到solr默认的逻辑操作符是“or”,它存在于这两个词之间。如此来看,这两个词会分别在索引中做查询:

表格中分别是两个词匹配到的文档ID,接着Lucene将执行分组操作去达到一个合适的最终结果集。如果,默认的逻辑操作符是“or”,那么这个请求的结果集将是分别由两个词的结果集组成的并集。图如下:
OR

AND

除了OR、AND查询外,NOT查询也很常用

Solr除了可以做这些查询,还可以做多词短语查询
3.1.6 短语查询与词位置
我们知道索引中保存的都是独立的词,那如何去查询一个完整的句子?当查询请求是一个短语时,实际上仍然是在索引中检索组成短语的每个词。一旦请求短语中的词所匹配的文档分别被检索出,每个词至少匹配到了1个或更多个文档。每个词在所匹配到的文档中的位置也被标记出,例假设搜索的短语是“new home”:

上面是一部分倒排索引的内容。查询请求“new home”执行后产生的结果是查询到了两篇匹配的文档,5和8。下图是查询索引后返回的结果示意图:

在这个例子中,“new” 和 “home”匹配到的文档ID分别是“4,5,8”和“2,5,7,8”。在这些匹配到的文档中5,8两个文档中的词出现的位置也相同,分别都是3,4。“Buying a New Home” 和 “Becoming a New Home Owner”这两个文档就更符合“new home”的搜索结果。由于要确保匹配到的文档中匹配到的词的位置是相同的一个位置,solr保证了在原始文档中的词形成的短语。可以让你在各自的文档中重建被索引的词之间的原始位置,从而可以在请求中搜索短语。
3.1.7 模糊匹配
在搜索时,并不是每次都能确切的预料到将要查询到的结果是什么样。因此,solr提供了多种模糊匹配的查询方法。solr的模糊匹配是一种在查询索引时能非精确的去匹配词的方法。例如,有些人想查到所有具有某个前缀的词(通配符搜索),或者找出在词的拼写上只有1,2个不同字母的词(模糊查询、编辑距离查询),或者在查询中,在某个的范围内去匹配两个的词(相似查询)
通配符查询
在SOLR中,最常用的模糊匹配的方式是通配符查询。假设,你需要查询以offic开始的所有文档,比较二的做法是在查询字符串中将所有可能的以offic开头的词枚举出来:
office OR officer OR official OR officiate OR …
因为这些在拼写上相似的词已经保存在索引中了,可以使用通配符*
offic*
另外,如果需要匹配的位置是在词中间,例如:officer、offer、officiator 那么可以写成
off*r
*可以匹配0个或者多个字母,如果只要匹配到一个字母,那么可以使用?通配符
off?r 这样只会匹配offer
通配符搜索提供了强大的功能,但是也有可能会很消耗系统资源。例如,o* 的资源消耗就要比 offic* 大很多,因为o*会去匹配索引中所有以o开头的词 ,而offic*只会去匹配以offic开头的所
有词。系统会先以通配符之前的字符去做匹配,然后再做通配符匹配。明显,以offic开头的词是以o开头的词的子集,匹配到的数量也会少很多,因此效率会更高。 如果要搜索以ing结尾的所有词(*ing)这种以通配符开头的词的资源消耗非常的高。做这样的操作,solr提供了快一些的解决方案,但是需要额外添加一些配置。解决方案是在schema.xml字段类
型的分析器中添加ReversedWildcardFilterFactory。
ReversedWildcardFilterFactory会在将文档添加到索引中的时候,将要加入的每个词在索引中添加两个,一个是正常的词,一个是反转之后的词。例如:
caring liking smiling
#gnirac #gnikil #gnilims
假如,当一个请求是以*ing开头提交上来时,solr会自动的在反转的索引中做搜索。将这种通配符前置的搜索转换为普通的通配符后置的搜索,这样就提升了性能。但是这样做会产生冗余,增加空间消耗,并且做全面查询的话效率会降低。因此,这种方法不被推荐,除非确实要做许多这种查询
最后,通配符查询,只能用于对单个词查询时。不能用于短语的查询,例如:
■ Works: softwar* eng?neering
■ Does not work: "softwar* eng?neering"
如果将通配符用于短语查询,那么就需要把整个短语当作一个词来做索引。
范围查询
当你需要在一个范围内去搜索文档时就可以使用范围搜索。例如,你想找到所有从2012年2月2日到2012年8月2日这6个月内创建的文档,可以按如下方式来搜索:
Query: created:[2012-02-01T00:00.0Z TO 2012-08-02T00:00.0Z]
这种范围请求的格式也可以用到其他字段类型上,例如:
Query: yearsOld:[18 TO 21] Matches 18, 19, 20, 21
Query: title:[boat TO boulder] Matches boat, boil, book, boulder, etc.
Query: price:[12.99 TO 14.99] Matches 12.99, 13.000009, 14.99, etc.
[] 表示括号中的两个值也在查找范围内。 {}表示括号中的两个值不在查找范围内