判断是否含有缺失数据
isnull()
删除缺失数据
data.dropna()data.dropna(how='all')
传入how='all'将只丢弃全为NA的那些行
用这种方式丢弃列,只需传入axis=1即可
data.dropna(axis=1, how='all')
丢弃一列全部为null的数据df.dropna(thresh=2)
如果含有null的数量少于2个,则会保留
填充缺失数据
df.fillna(0)
是通过一个字典调用fillna,就可以实现对不同的列填充不同的值:
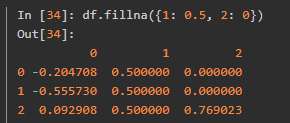
fillna默认会返回新对象,但也可以对现有对象进行就地修改:

向后填充值

可以限制填充次数

数据转换
移除重复数据
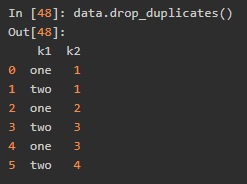
判断是否是重复行

去除重复列的值,判断全体
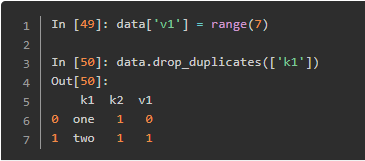
过滤某一列
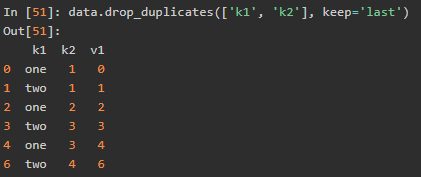
保留最后一个重复列
利用函数或映射进行数据转换
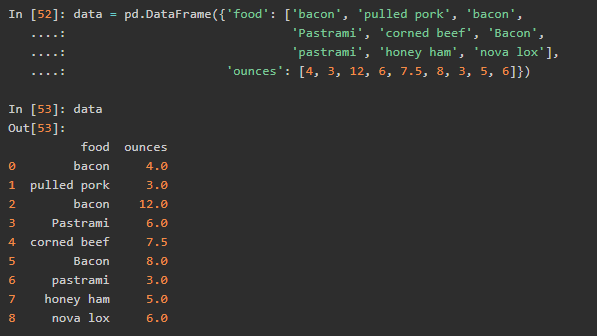

先转小写再对应

替换值

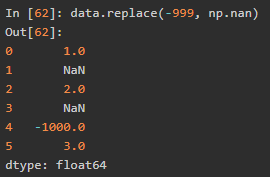
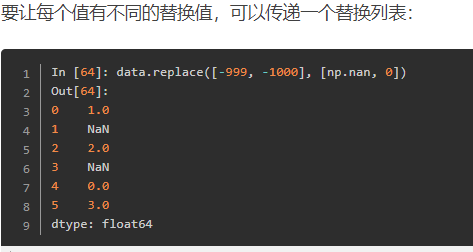
将-999替换为np.nan -1000替换为0

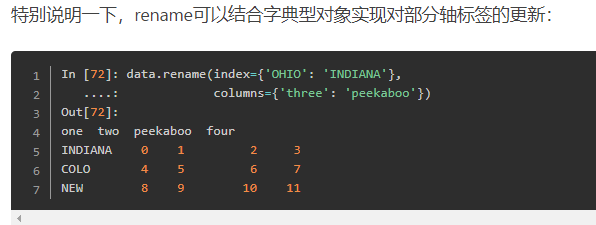
重命名轴索引




离散化和面元划分
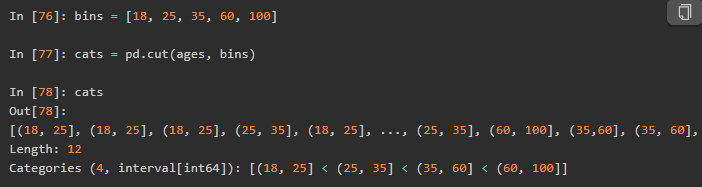

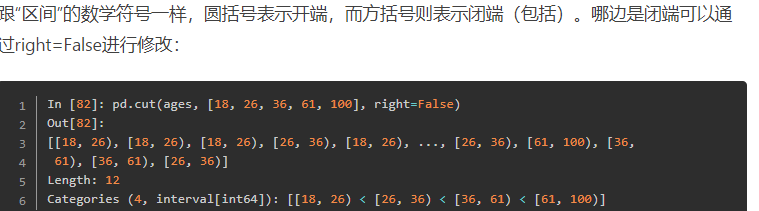

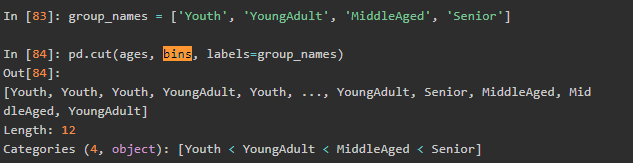
分4份保留到小数点后2位

qcut

检测和过滤异常值
盖帽法
np.sign(data)可以复制符号
排列和随机采样
生成司机数数组


计算指标/哑变量

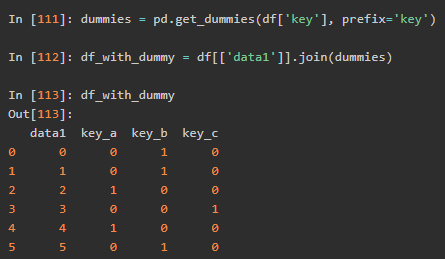
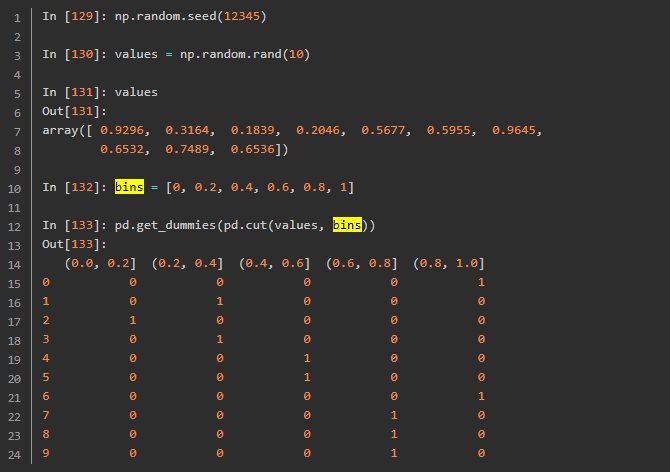
字符串操作



