一、Jdbc简介
JDBC代表数据库连接(Java DataBase Connectivity)。
JDBC是用于在编程语言中与数据库连接的API。
1. Jdbc架构
JDBC体系结构由两层组成:
- JDBC API:提供应用程序到JDBC管理器连接。
- JDBC驱动程序API:支持JDBC管理器到驱动程序连接。
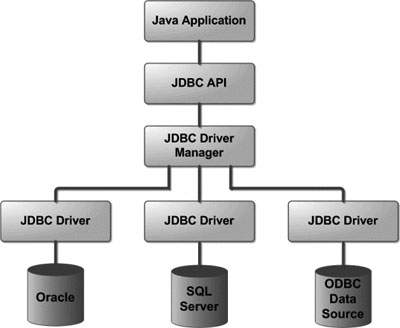
2. 常见的Jdbc组件
JDBC API提供以下接口和类:
- DriverManager:用于管理数据库驱动程序列表。
- Driver:此接口处理与数据库服务器的通信。
- Connection:此接口具有用于联系数据库的所有方法。
- Statement:此接口创建的对象将SQL语句提交到数据库。
- ResultSet:保存数据库检索后的数据。
- SQLException:处理数据库应用程序中发生的任何错误。
二、Jdbc数据库连接
建立Jdbc连接的步骤
- 引入数据库驱动包:添加对应数据库的驱动包
- 注册JDBC驱动程序:使JVM将所需的驱动程序实现加载到内存中,从而可以满足JDBC请求。
- 数据库URL配置:创建一个正确格式化的地址,指向要连接到的数据库。
- 创建连接对象:调用DriverManager对象的getConnection()方法来建立实际的数据库连接。
引入数据库驱动包
MySQL
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.25</version> </dependency>
Oracle
<dependency> <groupId>com.oracle</groupId> <artifactId>ojdbc6</artifactId> <version>11.2.0.3</version> </dependency>
注册JDBC驱动程序
在使用程序之前,必须先注册该驱动程序。
注册驱动程序是将数据库驱动程序的类文件加载到内存中的过程。
只需在程序中一次注册就可以。可以通过两种方式之一来注册驱动程序。
第一种:Class.forName()
推荐使用的方法,因为它使驱动程序注册可配置和便携。
Class.forName("oracle.jdbc.driver.OracleDriver");
第二种:DriverManager.registerDriver()
使用静态DriverManager.registerDriver()方法来注册驱动程序。
如果使用的是非JDK兼容的JVM(如Microsoft提供的),则应使用registerDriver()方法。
Driver myDriver = new oracle.jdbc.driver.OracleDriver();
DriverManager.registerDriver( myDriver );
MySQL驱动:com.mysql.jdbc.Driver
Oracle驱动:oracle.jdbc.driver.OracleDriver
数据库URL配置
加载驱动程序后,可以使用DriverManager.getConnection()方法建立连接。
有三个重载的DriverManager.getConnection()方法:
- getConnection(String url)
- getConnection(String url, Properties prop)
- getConnection(String url, String user, String password)
这里每个格式都需要一个数据库URL。 数据库URL是指向数据库的地址,不同的数据库URL是不同的。
MySQL
JDBC驱动程序名称:com.mysql.jdbc.Driver
URL格式:jdbc:mysql://hostname/databaseName
Oracle
JDBC驱动程序名称:oracle.jdbc.driver.OracleDriver
URL格式:jdbc:oracle:thin:@hostname:portNumber:databaseName
PostgreSQL
JDBC驱动程序名称:org.postgresql.Driver
URL格式:jdbc:postgresql://hostname:port/dbname
DB2
JDBC驱动程序名称:com.ibm.db2.jdbc.net.DB2Driver
URL格式:jdbc:db2:hostname:port Number/databaseName
Sybase
JDBC驱动程序名称:com.sybase.jdbc.SybDriver
URL格式:jdbc:sybase:Tds:hostname: portNumber/databaseName
创建连接对象
DriverManager.getConnection()
默认下是自动提交模式的,可以通过Connection的setAutoCommit方法手动设置。
三、Statement、PreparedStatement和CallableStatement
当获得了与数据库的连接后,就可以与数据库进行交互了。
JDBC Statement,CallableStatement和PreparedStatement接口定义了可用于发送SQL或PL/SQL命令,并从数据库接收数据的方法和属性。
- Statement:用于对数据库进行通用访问,在运行时使用静态SQL语句时很有用。 Statement接口不能接受参数。
- PreparedStatement:当计划要多次使用SQL语句时使用。PreparedStatement接口在运行时接受输入参数。
- CallableStatement:当想要访问数据库存储过程时使用。CallableStatement接口也可以接受运行时输入参数。
1. Statement
创建 Statement对象
使用Connection对象的createStatement()方法创建一个Statement对象。
Statement stmt = conn.createStatement( );
基本方法
- boolean execute (String SQL):如果可以检索到ResultSet对象,则返回一个布尔值true; 否则返回false。使用此方法执行SQLDDL语句或需要使用真正的动态SQL,可使用于执行创建数据库,创建表的SQL语句等等。
- int executeUpdate (String SQL):返回受SQL语句执行影响的行数。
- ResultSet executeQuery(String SQL):返回一个ResultSet对象。
- close():关闭Statement。如果先关闭Connection对象,它也会关闭Statement对象。 但是,应该始终显式关闭Statement对象,以确保正确的清理顺序。
批量处理
JDBC提供了数据库batch处理的能力,在数据大批量操作(新增、删除等)的情况下可以大幅度提升系统的性能。
批量处理需要connection.setAutoCommit(false),取消自动提交模式,根据实际情况手动提交。
示例
// 关闭自动执行 con.setAutoCommit(false); Statement stmt = con.createStatement(); stmt.addBatch("INSERT INTO employees VALUES (1000, 'Joe Jones')"); stmt.addBatch("INSERT INTO departments VALUES (260, 'Shoe')"); stmt.addBatch("INSERT INTO emp_dept VALUES (1000, 260)"); // 提交一批要执行的更新命令 int[] updateCounts = stmt.executeBatch();
注意:批处理不能包含有返回结果集的操作。
说明
- addBatch() 添加SQL操作语句
- executeBatch() 提交批量操作语句,返回更新计数数组,如果批处理中的某个命令无法正确执行,将抛出BatchUpdateException,可以调用其 getUpdateCounts() 方法来为批处理中成功执行的命令返回更新计数的整型数组
- clearBatch() 清空已添加的SQL操作语句
2. PreparedStatement
PreparedStatement接口扩展了Statement接口,比Statement更优秀。此语句可以动态地提供/接受参数。
创建PreparedStatement对象
String SQL = "Update Employees SET age = ? WHERE id = ?";
PreparedStatement pstmt = conn.prepareStatement(SQL);
JDBC中的所有参数都由 ? 符号作为占位符,这被称为参数标记。 在执行SQL语句之前,必须为每个参数(占位符)提供值。
setXXX()方法将值绑定到参数,其中XXX表示要绑定到输入参数的值的Java数据类型。 如果忘记提供绑定值,则将会抛出一个SQLException。
每个参数标记是它其顺序位置引用。第一个标记表示位置1,下一个位置2等等。 该方法与Java数组索引不同(它不从0开始)。
基本方法
- boolean execute (String SQL):如果可以检索到ResultSet对象,则返回一个布尔值true; 否则返回false。使用此方法执行SQLDDL语句或需要使用真正的动态SQL,可使用于执行创建数据库,创建表的SQL语句等等。
- int executeUpdate (String SQL):返回受SQL语句执行影响的行数。
- ResultSet executeQuery(String SQL):返回一个ResultSet对象。
- close():关闭PreparedStatement。
- clearParameters():清除参数
批量处理
PreparedStatement只能应用在同一个表中批量插入数据,或批量更新表的数据。
// 关闭自动执行 connection.setAutoCommit(false); PreparedStatement stmt = connection.prepareStatement("INSERT INTO sp_test(comment) VALUES (?)"); stmt.setString(1, "Kelly GongFu"); stmt.addBatch(); stmt.setString(1, "Cookie"); stmt.addBatch(); // 提交要执行的批处理 int[] updateCounts = stmt.executeBatch(); // 因取消了自动提交,所以需要手动提交 connection.commit(); connection.close();
3. CallableStatement
用于执行对数据库存储过程的调用。
四、查询结果集
1. 普通结果集ResultSet
java.sql.ResultSet接口表示数据库查询的结果集。
Jdbc提供以下连接方法来创建具有所需ResultSet的语句:
- createStatement(int RSType, int RSConcurrency);
- prepareStatement(String SQL, int RSType, int RSConcurrency);
- prepareCall(String sql, int RSType, int RSConcurrency);
第一个参数表示ResultSet对象的类型,第二个参数是两个ResultSet常量之一,用于指定结果集是只读还是可更新。
ResultSet对象类型
- ResultSet.TYPE_FORWARD_ONLY:光标只能在结果集中向前移动。
- ResultSet.TYPE_SCROLL_INSENSITIVE:光标可以向前和向后滚动,结果集对创建结果集后发生的数据库所做的更改不敏感。
- ResultSet.TYPE_SCROLL_SENSITIVE:光标可以向前和向后滚动,结果集对创建结果集之后发生的其他数据库的更改敏感。
如果不指定任何ResultSet类型,默认是TYPE_FORWARD_ONLY值。
ResultSet的并发性
- ResultSet.CONCUR_READ_ONLY 创建只读结果集
- ResultSet.CONCUR_UPDATABLE 创建可更新的结果集
如果不指定任何并发类型,默认是CONCUR_READ_ONLY值。
浏览结果集
光标移动
- previous():向前滚动
- next():向后滚动
- getRow():得到当前行号
- absolute(n):光标定位到n行
- relative(int n):相对移动n行
- first():将光标定位到结果集中第一行。
- last():将光标定位到结果集中最后一行。
- beforeFirst():将光标定位到结果集中第一行之前。
- afterLast():将光标定位到结果集中最后一行之后。
- moveToInsertRow():光标移到插入行
- moveToCurrentRow():光标移回到调用
- moveToInsertRow():方法前光标所在行
测试光标
- isFirst()
- isLast()
- isBeforeFirst()
- isAfterLast()
查看结果集
ResultSet接口包含数十种获取当前行数据的方法。
每个可能的数据类型都有一个get方法,每个get方法有两个版本,一个是采用列名称,一个是采用列索引(从1开始)。
注意:ResultSet在数据库连接关闭后(close掉)后就不能使用了,必须一直保持连接的状态才能使用,否则需要使用到RowSet离线结果集。
2. 离线结果集RowSet
RowSet是什么
RowSet接口继承自ResultSet接口。
与ResultSet相比,RowSet默认是可滚动、可更新、可序列化的结果集,可以作为JavaBean来方便地在网络上传输,用于同步两端数据。对于离线RowSet而言,
程序从创建RowSet时就已经把数据load进内存,因此可以更好地利用内存性能,降低数据库服务器的负载,提高程序性能。
RowSet接口下包含了JdbcRowSet, CachedRowSet, FilteredRowSet, JoinRowSet, WebRowSet,除了JdbcRowSet之外,后面四个都是离线RowSet。
RowSetFactory
在JDK1.6及以前的版本中,如果要使用JdbcRowSet,则必须使用JdbcRowSetImpl的构造器来构造对象,但是在编译的时候会有警告,因此JdbcRowSetImpl是内部专用的API,在未来版本可能会删除。这种获取JdbcRowSet的方式是不推荐的,因为使用内部API,在将来的版本中可能不兼容,而且这样的程序直接与具体的实现类JdbcRowSetImpl耦合,不利于维护和升级。
在JDK1.7中,引入了RowSetFactory和RowSetProvider接口,其中RowSetProvider负责创建RowSetFactory,而RowSetFactory则可以通过以下方法创建RowSet实例。
- createCachedRowSet()
- createFilteredRowSet()
- createJdbcRowSet()
- createJoinRowSet()
- createWebRowSet()
创建对象时可以传入ResultSet实例填充RowSet,也可以在创建JdbcRowSet实例之后通过execute(sql)方法得到数据填充RowSet。
//创建RowSetFactory RowSetFactory rowSetFactory = RowSetProvider.newFactory(); //创建指定的RowSet CachedRowSet rowSet = rowSetFactory.createCachedRowSet(); //将ResultSet放到RowSet中 rowSet.populate(resultSet);
离线查询分页
所谓分页,就是一次只装载ResultSet的某几条记录,这样可以避免CachedRowSet内存占用过大的问题。
CachedRowSet控制分页的方法:
- populate(ResultSet rs, int startRow) :从第startRow行开始装载
- setPageSize(int pageSize):设置每页大小
- previousPage():在底层ResultSet可用情况下,让CachedRowSet读取上一页记录
- nextPage() :在底层ResultSet可用情况下,让CachedRowSet读取下一页记录
3. ResultSetMetaData类
通过ResultSet对象可以获取到ResultSetMetaData 。
ResultSetMetaData metaData = resultSet.getMetaData();
ResultSetMetaData是什么
ResultSetMetaData 是描述ResultSet的元数据对象,包括了数据的字段名称、类型以及数目等必须具备的信息。
ResultSetMetaData类的主要方法
getColumCount()方法
方法的原型:public int getColumCount() throws SQLException。
方法说明:返回所有字段的数目
返回值:所有字段的数目(整数)。
异常产生:数据库发生任何的错误,则会产生一个SQLException对象。
getColumName()方法
方法的原型:public String getColumName (int colum) throws SQLException。
方法说明:根据字段的索引值取得字段的名称。
参数:colum,字段的索引值,从1开始。
返回值:字段的名称(字符串)。
异常产生:数据库发生任何的错误,则会产生一个SQLException对象。
getColumType()方法
方法的原型:public String getColumType (int colum) throws SQLException。
方法说明:根据字段的索引值取得字段的类型,返回值的定义在java.sql.Type类。
参数:colum,字段的索引值,从1开始。
返回值:字符串,SQL的数据类型定义在java.sql.Type类。
异常产生:数据库发生任何的错误,则会产生一个SQLException对象。
扩展阅读:https://www.cnblogs.com/xtdxs/p/7114927.html
通过Connection.getMetaData()可以获取到DatabaseMetaData,DatabaseMetaData是描述数据库信息的元数据对象。
五、事务处理
JDBC连接默认是处于自动提交模式,即每个SQL语句在完成后都会提交到数据库。
对于简单的应用程序是没有问题的,但是有时我们需要关闭自动提交,自己管理事务:
- 提高性能
- 保持业务流程的完整性
- 使用分布式事务
1. 关闭自动提交事务
要启用手动事务支持,调用Connection对象的setAutoCommit()方法,设置true或false。
2. 提交和回滚事务
conn.commit( );
conn.rollback( );
3. 事务保存点
新的JDBC 3.0新添加了Savepoint接口提供了额外的事务控制能力。大多数现代DBMS支持其环境中的保存点,如Oracle的PL/SQL。
设置保存点(Savepoint)时,可以在事务中定义逻辑回滚点。 如果通过保存点(Savepoint)发生错误时,则可以使用回滚方法来撤消所有更改或仅保存保存点之后所做的更改。
Connection对象有两种新的方法可用来管理保存点:
-
setSavepoint(String savepointName):定义新的保存点,它返回一个Savepoint对象
-
releaseSavepoint(Savepoint savepointName):删除保存点。要注意,它需要一个Savepoint对象作为参数。 该对象通常是由setSavepoint()方法生成的保存点
有一个rollback (String savepointName)方法,它将使用事务回滚到指定的保存点。
示例
try{ //Assume a valid connection object conn conn.setAutoCommit(false); Statement stmt = conn.createStatement(); //set a Savepoint Savepoint savepoint1 = conn.setSavepoint("Savepoint1"); String SQL = "INSERT INTO Employees " + "VALUES (106, 24, 'Curry', 'Stephen')"; stmt.executeUpdate(SQL); //Submit a malformed SQL statement that breaks String SQL = "INSERTED IN Employees " + "VALUES (107, 32, 'Kobe', 'Bryant')"; stmt.executeUpdate(SQL); // If there is no error, commit the changes. conn.commit(); }catch(SQLException se){ // If there is any error. conn.rollback(savepoint1); }
六、数据库连接池
1. 连接池的实现原理
连接复用,通过建立一个数据库连接池以及一套连接使用管理策略,使得一个数据库连接可以得到高效、安全的复用,避免了数据库连接频繁建立、关闭的开销。
对于共享资源,有一个很著名的设计模式:资源池。该模式正是为了解决资源频繁分配、释放所造成的问题的。把该模式应用到数据库连接管理领域,就是建立一个数据库连接池,提供一套高效的连接分配、使用策略,最终目标是实现连接的高效、安全的复用。
数据库连接池的基本原理是在内部对象池中维护一定数量的数据库连接,并对外暴露数据库连接获取和返回方法。如:外部使用者可通过getConnection 方法获取连接,使用完毕后再通过releaseConnection 方法将连接返回,注意此时连接并没有关闭,而是由连接池管理器回收,并为下一次使用做好准备。
ConnectionPool以缓冲池的机制,在一定数量上限范围内,控制管理Connection,Statement和ResultSet。任何数据库的资源是有限的,如果被耗尽,则无法获得更多的数据服务。
在大多数情况下,资源的耗尽不是由于应用的正常负载过高,而是程序原因。
在实际工作中,数据库资源往往是瓶颈资源,不同的应用都会访问同一数据源。其中某个应用耗尽了数据库资源后,意味其他的应用也无法正常运行。因此,ConnectionPool的第一个任务是限制:每个应用或系统可以拥有的最大资源。也就是确定连接池的大小(PoolSize)。
ConnectionPool的第二个任务:在连接池的大小(PoolSize)范围内,最大限度地使用资源,缩短数据库访问的使用周期。许多数据库中,连接(Connection)并不是资源的最小单元,控制Statement资源比Connection更重要。
以Oracle为例:每申请一个连接(Connection)会在物理网络(如 TCP/IP网络)上建立一个用于通讯的连接,在此连接上还可以申请一定数量的Statement。同一连接可提供的活跃Statement数量可以达到几百。在节约网络资源的同时,缩短了每次会话周期(物理连接的建立是个费时的操作)。但在一般的应用中,多数是这样的,有10个程序调用,则会产生10次物理连接,每个Statement单独占用一个物理连接,这是极大的资源浪费。 ConnectionPool可以解决这个问题,让几十、几百个Statement只占用同一个物理连接, 发挥数据库原有的优点。
通过ConnectionPool对资源的有效管理,应用可以获得的Statement总数到达 :(并发物理连接数)×(每个连接可提供的Statement数量)
例如某种数据库可同时建立的物理连接数为 200个,每个连接可同时提供250个Statement,那么ConnectionPool最终为应用提供的并发Statement总数为: 200 × 250 = 50,000个。这是个并发数字,很少有系统会突破这个量级。所以在本节的开始,指出资源的耗尽与应用程序直接管理有关。
对资源的优化管理,很大程度上依靠数据库自身的JDBC Driver是否具备。有些数据库的JDBC Driver并不支持Connection与Statement之间的逻辑连接功能。
对资源的申请、释放、回收、共享和同步,这些管理是复杂精密的。所以,ConnectionPool另一个功能就是,封装这些操作,为应用提供简单的,甚至是不改变应用风格的调用接口。
2. 简单连接池的实现
- 程序初始化时创建数据库连接池(给所有的连接设置一个可用的标识)
- 使用时向数据申请可用连接(如何判断可用?首先标识是可用的,其次通过执行一个select查询来判断是真正的可用,获取后,设置标识为不可用)
- 使用完毕,将连接返还给连接池(将标识设置为可用)
- 程序退出时,关闭所有连接,释放资源
3. 开源的数据库连接池
DBCP:org.apache.commons.dbcp2.BasicDataSource
C3P0:com.mchange.v2.c3p0.ComboPooledDataSource
Druid:com.alibaba.druid.pool.DruidDataSource
......
这里以DBCP为例进行说明。Tomcat的连接池也是采用该连接池来实现的。该数据库连接池既可以与应用服务器整合使用,也可由应用程序独立使用。
添加依赖
<!-- https://mvnrepository.com/artifact/org.apache.commons/commons-dbcp2 --> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-dbcp2</artifactId> <version>2.7.0</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.commons/commons-pool2 --> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> <version>2.7.0</version> </dependency>
dbcpConfig.properties 配置文件
#连接设置 driver=com.mysql.jdbc.Driver url=jdbc:mysql://localhost:3305/spring username=root password=123456 #初始化连接 initialSize=10 #最大连接数量 maxActive=50 #<!-- 最大空闲连接 --> maxIdle=20 #<!-- 最小空闲连接 --> minIdle=5 #<!-- 超时等待时间以毫秒为单位 6000毫秒/1000=60秒 --> maxWait=60000 #JDBC驱动建立连接时附带的连接属性的格式必须为这样:[属性名=property;] #注意:"user"与"password"两个属性会被明确传递,因此这里不需要包含它们 connectionProperties=useUnicode=true;characterEncoding=utf8 #指定由连接池所创建的连接的自动提交(auto-commit)状态 defaultAutoCommit=false #driver default 指定由连接池所创建连接的事务级别(TransactionIsolation) #可用值:NONE,READ_UNCOMMITTED,READ_COMMITTED,REPEATABLE_READ,SERIALIZABLE defaultTransactionIsolation=READ_COMMITTED
JdbcUtils工具类
import org.apache.commons.dbcp2.BasicDataSourceFactory; import javax.sql.DataSource; import java.io.InputStream; import java.sql.Connection; import java.sql.ResultSet; import java.sql.Statement; import java.util.Properties; public class JdbcUtils { private static DataSource ds = null; static { try { InputStream in = JdbcUtils.class.getClassLoader().getResourceAsStream("dbcpConfig.properties"); Properties prop = new Properties(); prop.load(in); BasicDataSourceFactory factory = new BasicDataSourceFactory(); //创建数据库连接池 ds = factory.createDataSource(prop); } catch (Exception e) { throw new ExceptionInInitializerError(e); } } public static Connection getConnection() throws Exception { return ds.getConnection();//不会把sql真正的connection返回 } public static void release(Connection conn, Statement st, ResultSet rs) { if (rs != null) { try { rs.close(); //throw new } catch (Exception e) { e.printStackTrace(); } rs = null; } if (st != null) { try { st.close(); } catch (Exception e) { e.printStackTrace(); } st = null; } if (conn != null) { try { conn.close(); } catch (Exception e) { e.printStackTrace(); } } } }