一、添加依赖
<!-- https://mvnrepository.com/artifact/org.springframework.kafka/spring-kafka --> <!-- 这里使用的spring版本是4.3.23.RELEASE, 所以引用的spring-kafka版本是1.3.10的,如果太高,会 Caused by: java.lang.ClassNotFoundException: org.springframework.core.log.LogAccessor--> <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> <version>1.3.10.RELEASE</version> </dependency> <!--https://mvnrepository.com/artifact/org.slf4j/slf4j-api--> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>1.7.28</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.28</version> </dependency>
在classpath下添加log4j.properties:
### 设置rootLogger ### log4j.rootLogger = info,stdout,D,E ### 输出信息到控制台 ### ### 控制台输出 log4j.appender.stdout = org.apache.log4j.ConsoleAppender ### 默认是system.out,如果system.err是红色提示 log4j.appender.stdout.Target = System.out ### 布局格式,可以灵活指定 log4j.appender.stdout.layout = org.apache.log4j.PatternLayout ### 消息格式化 log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n ### 输出INFO 级别以上的日志到=D://logs/error.log ### ### 以每天一个文件输出日志 log4j.appender.D = org.apache.log4j.DailyRollingFileAppender ### 输出文件目录 log4j.appender.D.File = D://logs/log.log ### 消息增加到指定的文件中,false表示覆盖指定文件内容 log4j.appender.D.Append = true ### 输出信息最低级别 log4j.appender.D.Threshold = INFO log4j.appender.D.layout = org.apache.log4j.PatternLayout log4j.appender.D.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n ### 输出ERROR 级别以上的日志到=D://logs/error.log ### log4j.appender.E = org.apache.log4j.DailyRollingFileAppender log4j.appender.E.File =D://logs/error.log log4j.appender.E.Append = true log4j.appender.E.Threshold = ERROR log4j.appender.E.layout = org.apache.log4j.PatternLayout log4j.appender.E.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
二、创建KafkaConfiguration配置类
都是一些配置参数,值得注意的是,KafkaTemplate的类型为<Integer,String>,我们可以找kafkaTemplate的send方法,有多个重载方法,其中有个方法如下,key和data参数都为泛型,这其实就是对应着KafkaTemplate<Integer,String>。那具体有什么用呢,还记得我们的Topic中可以包含多个Partition(分区)吗,那我们如果不想手动指定发送到哪个分区,我们则可以利用key去实现。这里我们的key是Integer类型,template会根据 key 路由到对应的partition中,如果key存在对应的partitionID则发送到该partition中,否则由算法选择发送到哪个partition。
import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.common.serialization.IntegerDeserializer; import org.apache.kafka.common.serialization.IntegerSerializer; import org.apache.kafka.common.serialization.StringDeserializer; import org.apache.kafka.common.serialization.StringSerializer; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.kafka.annotation.EnableKafka; import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory; import org.springframework.kafka.core.ConsumerFactory; import org.springframework.kafka.core.DefaultKafkaConsumerFactory; import org.springframework.kafka.core.DefaultKafkaProducerFactory; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.kafka.core.ProducerFactory; import java.util.HashMap; import java.util.Map; @Configuration @EnableKafka public class KafkaConfiguration { //ConcurrentKafkaListenerContainerFactory为创建Kafka监听器的工程类,这里只配置了消费者 @Bean public ConcurrentKafkaListenerContainerFactory<Integer, String> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); return factory; } //根据consumerProps填写的参数创建消费者工厂 @Bean public ConsumerFactory<Integer, String> consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerProps()); } //根据senderProps填写的参数创建生产者工厂 @Bean public ProducerFactory<Integer, String> producerFactory() { return new DefaultKafkaProducerFactory<>(senderProps()); } //kafkaTemplate实现了Kafka发送接收等功能 @Bean public KafkaTemplate<Integer, String> kafkaTemplate() { KafkaTemplate template = new KafkaTemplate<Integer, String>(producerFactory()); return template; } //消费者配置参数 private Map<String, Object> consumerProps() { Map<String, Object> props = new HashMap<>(); //连接地址 props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); //GroupID props.put(ConsumerConfig.GROUP_ID_CONFIG, "bootKafka"); //是否自动提交 props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); //自动提交的频率 props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "100"); //Session超时设置 props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "15000"); //键的反序列化方式 props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class); //值的反序列化方式 props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); return props; } //生产者配置 private Map<String, Object> senderProps (){ Map<String, Object> props = new HashMap<>(); //连接地址 props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); //重试,0为不启用重试机制 props.put(ProducerConfig.RETRIES_CONFIG, 1); //控制批处理大小,单位为字节 props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384); //批量发送,延迟为1毫秒,启用该功能能有效减少生产者发送消息次数,从而提高并发量 props.put(ProducerConfig.LINGER_MS_CONFIG, 1); //生产者可以使用的总内存字节来缓冲等待发送到服务器的记录 props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 1024000); //键的序列化方式 props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class); //值的序列化方式 props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); return props; } }
三、创建DemoListener消费者
这里的消费者其实就是一个监听类,指定监听名为topic.quick.demo的Topic,consumerID为demo。
import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.kafka.annotation.KafkaListener; import org.springframework.stereotype.Component; @Component public class DemoListener { private static final Logger log = LoggerFactory.getLogger(DemoListener.class); //声明consumerID为demo,监听topicName为test20200519的Topic @KafkaListener(id = "demo", topics = "test20200519") public void listen(String msgData) { log.info("demo receive : "+msgData); } }
可以在cmd命令行窗口中创建主题,启动生产者,观察控制台。
四、操作Topic以及Kafka Tool 2的使用
1. Kafka Tool 2
Kafka Tool 2是一款Kafka的可视化客户端工具,可以非常方便的查看Topic的队列信息以及消费者信息以及kafka节点信息。下载地址
(1) 创建连接
(2) 配置连接
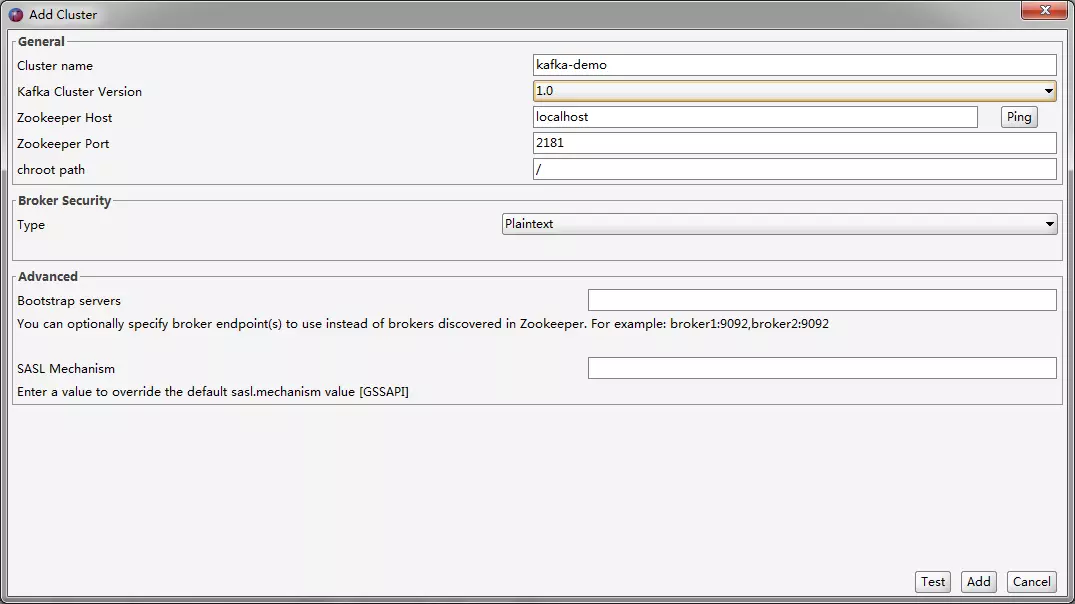
这个软件监控的是Zookeeper而不是Kafka,Kafka的集群搭建也是依赖Zookeeper来实现的,所以默认情况下我们都是直接通过Zookeeper去完成大部分操作。
(3) 界面
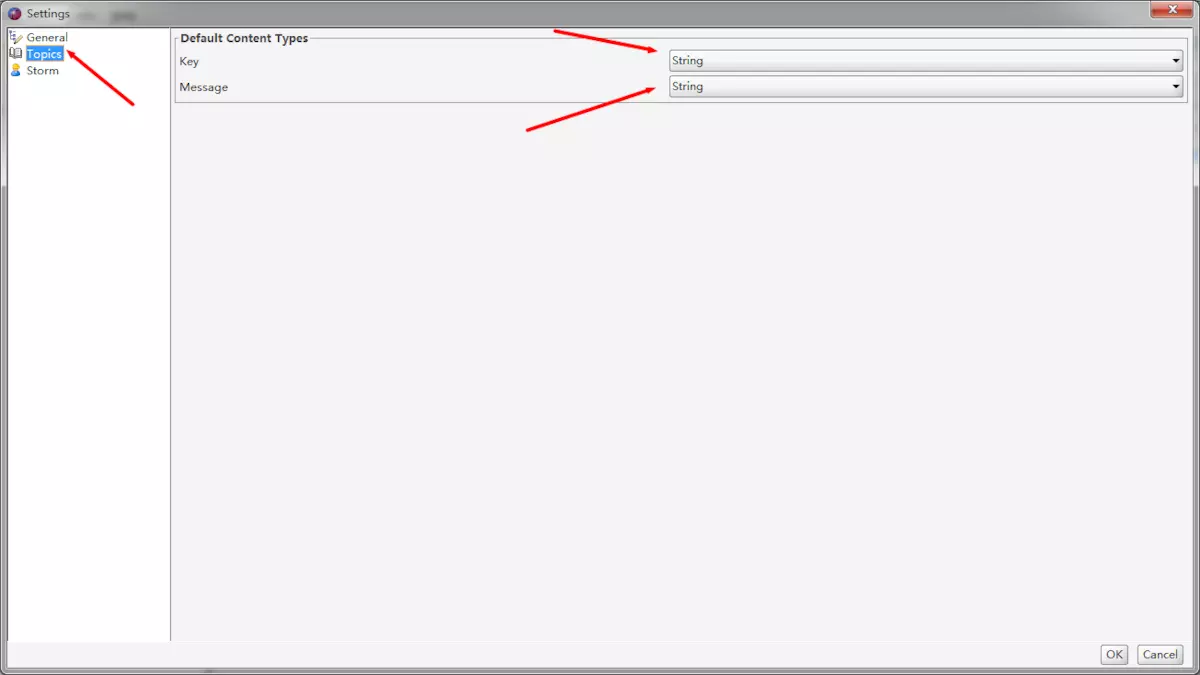
(4) 修改为明文显示
这个软件默认显示数据的类型为Byte,说白了我们是不能直接看到消息的明文数据的。
2. 操作Topic
(1) 手动创建Topic
KafkaTemplate在发送的时候就已经帮我们完成了创建Topic的操作,所以我们不需要主动创建Topic,而是交由KafkaTemplate去完成。但这样也出现了问题,这种情况创建出来的Topic的Partition(分区)数永远只有1个,也不会有副本(不知道的回炉重造,Kafka部署集群时使用的),这就导致了我们在后期不能顺利扩展。所以这种情况我们需要使用代码手动去创建Topic。
@Bean public KafkaAdmin kafkaAdmin() { Map<String, Object> props = new HashMap<>(); //配置Kafka实例的连接地址 props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092"); KafkaAdmin admin = new KafkaAdmin(props); return admin; } @Bean public AdminClient adminClient() { return AdminClient.create(kafkaAdmin().getConfig()); }
测试:
@Autowired private AdminClient adminClient; /* * @MethodName 创建topic * @Description Topic的新增删除方法都是异步执行的,为了避免在创建过程中程序关闭导致创建失败,所以在代码最后加了一秒的休眠 * 分区数量和副本数 * 我们在操作过程中可以动态修改分区数,修改分区数并不会导致数据的丢失,但是分区数只能增大不能减小。 */ @Test public void testCreateTopic() throws InterruptedException { NewTopic topic = new NewTopic("topic.Init4", 4, (short) 1); adminClient.createTopics(Arrays.asList(topic)); Thread.sleep(1000); }
(2) 查询topic信息
/** * @MethodName listTopics * @Description 查询topic */ @Test public void listTopics() throws ExecutionException, InterruptedException { DescribeTopicsResult result = adminClient.describeTopics(Arrays.asList("topic.Init4")); result.all().get().forEach((k,v)->System.out.println("k: " + k +" ,v: "+ v.toString() +" ")); }
3. KafkaTemplate发送消息及结果回调
Spring是借助KafkaTemplate来操作kafka的(类似于JdbcTemplate),其中send方式是核心方法,有很多的重载方法。
这里以最多参数的send方法来进行说明:
- topic:这里填写的是Topic的名字
- partition:这里填写的是分区的id,其实也是就第几个分区,id从0开始。表示指定发送到该分区中
- timestamp:时间戳,一般默认当前时间戳
- key:消息的键
- data:消息的数据
- ProducerRecord:消息对应的封装类,包含上述字段
- Message<?>:Spring自带的Message封装类,包含消息及消息头
ListenableFuture<SendResult<K, V>> sendDefault(V data); ListenableFuture<SendResult<K, V>> sendDefault(K key, V data); ListenableFuture<SendResult<K, V>> sendDefault(Integer partition, K key, V data); ListenableFuture<SendResult<K, V>> sendDefault(Integer partition, Long timestamp, K key, V data); ListenableFuture<SendResult<K, V>> send(String topic, V data); ListenableFuture<SendResult<K, V>> send(String topic, K key, V data); ListenableFuture<SendResult<K, V>> send(String topic, Integer partition, K key, V data); ListenableFuture<SendResult<K, V>> send(String topic, Integer partition, Long timestamp, K key, V data); ListenableFuture<SendResult<K, V>> send(ProducerRecord<K, V> record); ListenableFuture<SendResult<K, V>> send(Message<?> message);
(1) 使用sendDefault发送消息
//这个是我们之前编写的KafkaTemplate代码,加入@Primary注解 //@Primary注解的意思是在拥有多个同类型的Bean时优先使用该Bean,到时候方便我们使用@Autowired注解自动注入。 @Bean @Primary public KafkaTemplate<Integer, String> kafkaTemplate() { KafkaTemplate template = new KafkaTemplate<Integer, String>(producerFactory()); return template; } @Bean("defaultKafkaTemplate") public KafkaTemplate<Integer, String> defaultKafkaTemplate() { KafkaTemplate template = new KafkaTemplate<Integer, String>(producerFactory()); template.setDefaultTopic("topic.Init4"); return template; }
测试
//这里要注意不能直接用@Autowired, @Autowire默认是按类型查找 //因存在两个KafkaTemplate实例,所以使用名称查找 @Resource @Resource KafkaTemplate defaultKafkaTemplate; @Test public void testDefaultTopicSend(){ defaultKafkaTemplate.sendDefault("I`m send msg to default topic"); }
其他的几个测试:
@Autowired KafkaTemplate kafkaTemplate; @Test public void testTemplateSend() { //发送带有时间戳的消息 kafkaTemplate.send("topic.Init4", 0, System.currentTimeMillis(), 0, "send message with timestamp"); //使用ProducerRecord发送消息 ProducerRecord record = new ProducerRecord("topic.Init4", "use ProducerRecord to send message"); kafkaTemplate.send(record); //使用Message发送消息 Map map = new HashMap(); map.put(KafkaHeaders.TOPIC, "topic.Init4"); map.put(KafkaHeaders.PARTITION_ID, 0); map.put(KafkaHeaders.MESSAGE_KEY, 0); GenericMessage message = new GenericMessage("use Message to send message",new MessageHeaders(map)); kafkaTemplate.send(message); }
(2) 消息结果回调
一般来说我们都会去获取KafkaTemplate发送消息的结果去判断消息是否发送成功,如果消息发送失败,则会重新发送或者执行对应的业务逻辑。所以这里我们去实现这个功能。
/** * 实现ProducerListener接口,重写方法,实现消息回调 */ @Component public class KafkaSendResultHandler implements ProducerListener<String, String> { private static final Logger log = LoggerFactory.getLogger(KafkaSendResultHandler.class); @Override public void onSuccess(String topic, Integer partition, String key, String value, RecordMetadata recordMetadata) { log.info("发送kafka消息成功..." + topic); } @Override public void onError(String topic, Integer partition, String key, String value, Exception exception) { log.info("发送kafka消息失败..." + topic); } //是否对发送成功的消息感兴趣,false表示不感兴趣,即不会执行onSuccess方法 @Override public boolean isInterestedInSuccess() { return true; } }
测试:
@Autowired KafkaTemplate kafkaTemplate; @Autowired private KafkaSendResultHandler producerListener; @Test public void sendMessage() throws InterruptedException { kafkaTemplate.setProducerListener(producerListener); kafkaTemplate.send("topic.Init4", "test producer listen"); Thread.sleep(1000); }
(3) KafkaTemplate异步发送消息
上文提及了发送消息的时候需要休眠一下,否则发送时间较长的时候会导致进程提前关闭导致无法调用回调时间。主要是因为KafkaTemplate发送消息是采取异步方式发送的。
KafkaTemplate会使用ProducerRecord把我们传递进来的参数再一次封装,最后调用doSend方法发送消息到Kafka中。
① doSend方法先是检测是否开启事务,紧接着使用SettableListenableFuture发送消息,然后判断是否启动自动冲洗数据到Kafka。
② SettableListenableFuture实现了ListenableFuture接口,ListenableFuture则实现了Future接口,Future是Java自带的实现异步编程的接口,支持返回值的异步,而我们使用Thread或者Runnable都是不带返回值的。
(4) KafkaTemplate同步发送消息
KafkaTemplate异步发送消息大大的提升了生产者的并发能力,但某些场景下我们并不需要异步发送消息,这个时候我们可以采取同步发送方式,实现也是非常简单的,我们只需要在send方法后面调用get方法即可。Future模式中,我们采取异步执行事件,等到需要返回值得时候我们再调用get方法获取future的返回值。
@Test public void testSyncSend() throws ExecutionException, InterruptedException { kafkaTemplate.send("topic.Init4", "test sync send message").get(); }
get方法还有一个比较有意思的重载方法,get(long timeout, TimeUnit unit),当send方法耗时大于get方法所设定的参数时会抛出一个超时异常,但需要注意,这里仅抛出异常,消息还是会发送成功的。
这里的测试方法设置send耗时必须小于 一微秒(那必须得失败呀,嘿嘿嘿),运行后我们可以看到抛出的异常,但也发现消息能发送成功并被监听器接收了。那这功能有什么作用呢,可以判断消息发送是否快还是慢。
@Test public void testTimeOut() throws ExecutionException, InterruptedException, TimeoutException { kafkaTemplate.send("topic.Init4", "test send message timeout").get(1, TimeUnit.MICROSECONDS); }
4. 使用kafka事务的两种方式
(1) 为什么要使用kafka事务
在日常开发中,数据库的事务几乎是必须用到的,事务回滚不一定在于数据增删改异常,可能系统出现特定逻辑判断的时候也需要进行数据回滚,Kafka亦是如此,我们并不希望消息监听器接收到一些错误的或者不需要的消息。
(2) 使用事务的两种方式
- 配置Kafka事务管理器并使用@Transactional注解
- 使用KafkaTemplate的executeInTransaction方法
① 使用@Transactional注解方式
首先需要我们配置KafkaTransactionManager,这个类就是Kafka提供给我们的事务管理类,我们需要使用生产者工厂来创建这个事务管理类。需要注意的是,我们需要在producerFactory中开启事务功能,并设置TransactionIdPrefix,TransactionIdPrefix是用来生成Transactional.id的前缀。
@Bean public ProducerFactory<Integer, String> producerFactory() { DefaultKafkaProducerFactory factory = new DefaultKafkaProducerFactory<>(senderProps()); factory.transactionCapable(); factory.setTransactionIdPrefix("tran-"); return factory; } @Bean public KafkaTransactionManager transactionManager(ProducerFactory producerFactory) { KafkaTransactionManager manager = new KafkaTransactionManager(producerFactory); return manager; }
测试
@Test @Transactional public void testTransactionalAnnotation() throws InterruptedException { kafkaTemplate.send("topic.Init4", "test transactional annotation"); throw new RuntimeException("fail"); }
② 使用KafkaTemplate.executeInTransaction开启事务
/** * 疑问:这段代码一直没有test完,没有进入执行 */ @Test public void testExecuteInTransaction() throws InterruptedException { kafkaTemplate.executeInTransaction(new KafkaOperations.OperationsCallback() { @Override public Object doInOperations(KafkaOperations kafkaOperations) { System.out.println("-------------------------"); kafkaOperations.send("topic.Init4", "test executeInTransaction"); throw new RuntimeException("fail"); //return true; } }); }
5. @KafkaListener的花式操作
对于Kafka中Topic的数据消费,我们一般都选择使用消息监听器进行消费,怎么把消息监听器玩出花来呢,那就得看看它所实现的功能了。
Spring-Kafka中消息监听大致分为两种类型,一种是单条数据消费,一种是批量消费;两者的区别只是在于监听器一次性获取消息的数量。GenericMessageListener是我们实现消息监听的一个接口,向上扩展的接口有非常多,比如:单数据消费的MessageListener、批量消费的BatchMessageListener、还有具备ACK机制的AcknowledgingMessageListener和BatchAcknowledgingMessageListener等等。
(1) GenericMessageListener
GenericMessageListener使用注解标明这是一个函数式接口,默认实现了三种不同参数的onMessage方法。data就是我们需要接收的数据,Consumer则是消费者类,Acknowledgment则是用来实现Ack机制的类。需要注意一下的是,Consumer对象并不是线程安全的。
@FunctionalInterface public interface GenericMessageListener<T> { void onMessage(T var1); default void onMessage(T data, Acknowledgment acknowledgment) { throw new UnsupportedOperationException("Container should never call this"); } default void onMessage(T data, Consumer<?, ?> consumer) { throw new UnsupportedOperationException("Container should never call this"); } default void onMessage(T data, Acknowledgment acknowledgment, Consumer<?, ?> consumer) { throw new UnsupportedOperationException("Container should never call this"); } }
① 非注解方式监听topic
- 创建监听器工厂
@Bean public ConcurrentKafkaListenerContainerFactory<Integer, String> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); return factory; }
- Bean方式创建监听容器
@Bean public KafkaMessageListenerContainer demoListenerContainer() { // 参数为topic数组 ContainerProperties properties = new ContainerProperties("topic.Init2", "topic.Init3", "topic.Init4"); properties.setGroupId("topic.Init"); properties.setMessageListener(new MessageListener<Integer,String>() { private Logger log = LoggerFactory.getLogger(this.getClass()); @Override public void onMessage(ConsumerRecord<Integer, String> record) { log.info("topic.Init receive : " + record.toString()); } }); return new KafkaMessageListenerContainer(consumerFactory(), properties); }
- 测试
/** * 如果创建kafkaTemplate的producerFactory开启了事务配置,这里需要添加@Transactional注解 */ @Test public void testKafkaListener() { kafkaTemplate.send("topic.Init2", "send msg to beanListener"); }
② @KafkaListener
使用@KafkaListener这个注解并不局限于这个监听容器是单条数据消费还是批量消费,它的监听方法可以接收的参数有:
- data : 对于data值的类型其实并没有限定,根据KafkaTemplate所定义的类型来决定。data为List集合的则是用作批量消费。
- ConsumerRecord:具体消费数据类,包含Headers信息、分区信息、时间戳等。
- Acknowledgment:用作Ack机制的接口。
- Consumer:消费者类,使用该类我们可以手动提交偏移量、控制消费速率等功能。
public void listen1(String data) public void listen2(ConsumerRecord<K,V> data) public void listen3(ConsumerRecord<K,V> data, Acknowledgment acknowledgment) public void listen4(ConsumerRecord<K,V> data, Acknowledgment acknowledgment, Consumer<K,V> consumer) public void listen5(List<String> data) public void listen6(List<ConsumerRecord<K,V>> data) public void listen7(List<ConsumerRecord<K,V>> data, Acknowledgment acknowledgment) public void listen8(List<ConsumerRecord<K,V>> data, Acknowledgment acknowledgment, Consumer<K,V> consumer)
@KafkaListener注解提供了如下属性:
- id:消费者的id,当GroupId没有被配置的时候,默认id为GroupId
- containerFactory:@KafkaListener区分单数据还是多数据消费只需要配置一下注解的containerFactory属性就可以了,这里面配置的是监听容器工厂,也就是ConcurrentKafkaListenerContainerFactory,配置BeanName
- topics:需要监听的Topic,可监听多个
- topicPartitions:可配置更加详细的监听信息,必须监听某个Topic中的指定分区,或者从offset为200的偏移量开始监听
- errorHandler:监听异常处理器,配置BeanName
- groupId:消费组ID
- idIsGroup:id是否为GroupId
- clientIdPrefix:消费者Id前缀
- beanRef:真实监听容器的BeanName,需要在 BeanName前加 "_"
(2) 使用ConsumerRecord类消费
ConsumerRecord类里面包含分区信息、消息头、消息体等内容,如果业务需要获取这些参数时,使用ConsumerRecord会是个不错的选择。如果使用具体的类型接收消息体则更加方便,比如说用String类型去接收消息体。
(3) 批量消费
- 重新创建一份新的消费者配置,配置为一次拉取5条消息
- 创建一个监听容器工厂,设置其为批量消费并设置并发量为5,这个并发量根据分区数决定,必须小于等于分区数,否则会有线程一直处于空闲状态
- 创建一个分区数为8的Topic
- 创建监听方法,设置消费id为batch,监听topic.quick.batch,使用batchContainerFactory工厂创建该监听容器
import org.apache.kafka.clients.admin.NewTopic; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.common.serialization.IntegerDeserializer; import org.apache.kafka.common.serialization.StringDeserializer; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.context.annotation.Bean; import org.springframework.kafka.annotation.KafkaListener; import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory; import org.springframework.kafka.core.DefaultKafkaConsumerFactory; import org.springframework.stereotype.Component; import java.util.HashMap; import java.util.List; import java.util.Map; @Component public class BatchListener { private static final Logger log= LoggerFactory.getLogger(BatchListener.class); private Map<String, Object> consumerProps() { Map<String, Object> props = new HashMap<>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true); props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000"); props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "15000"); //一次拉取消息数量 props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "5"); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); return props; } @Bean("batchContainerFactory") public ConcurrentKafkaListenerContainerFactory listenerContainer() { ConcurrentKafkaListenerContainerFactory container = new ConcurrentKafkaListenerContainerFactory(); container.setConsumerFactory(new DefaultKafkaConsumerFactory(consumerProps())); //设置并发量,小于或等于Topic的分区数 container.setConcurrency(5); //设置为批量监听 container.setBatchListener(true); return container; } @Bean public NewTopic batchTopic() { return new NewTopic("topic.quick.batch", 8, (short) 1); } @KafkaListener(id = "batch",topics = {"topic.quick.batch"},containerFactory = "batchContainerFactory") public void batchListener(List<String> data) { log.info("topic.quick.batch receive : "); for (String s : data) { log.info(s); } } }
紧接着我们启动项目,控制台的日志信息非常完整,我们可以看到batchListener这个监听容器的partition分配信息。我们设置concurrency为5,也就是将会启动5条线程进行监听,那我们创建的topic则是有8个partition,意味着将有3条线程分配到2个partition和2条线程分配到1个partition。我们可以看到这段日志的最后5行,这就是每条线程分配到的partition。
partitions assigned:[topic.quick.batch-4, topic.quick.batch-5] [INFO ] 2020-05-20 22:13:25,736 method:org.springframework.kafka.listener.AbstractMessageListenerContainer$2.onPartitionsAssigned(AbstractMessageListenerContainer.java:281) partitions assigned:[topic.quick.batch-2, topic.quick.batch-3] [INFO ] 2020-05-20 22:13:25,736 method:org.springframework.kafka.listener.AbstractMessageListenerContainer$2.onPartitionsAssigned(AbstractMessageListenerContainer.java:281) partitions assigned:[topic.quick.batch-7] [INFO ] 2020-05-20 22:13:25,783 method:org.springframework.kafka.listener.AbstractMessageListenerContainer$2.onPartitionsAssigned(AbstractMessageListenerContainer.java:281) partitions assigned:[topic.quick.batch-6] [INFO ] 2020-05-20 22:13:25,783 method:org.springframework.web.servlet.handler.AbstractHandlerMethodMapping$MappingRegistry.register(AbstractHandlerMethodMapping.java:544) Mapped "{[/user/{id}],methods=[GET]}" onto public java.lang.String com.linhw.spring.test.PathVariableController.getUser(org.springframework.ui.Model,java.lang.Integer) [INFO ] 2020-05-20 22:13:25,783 method:org.springframework.web.servlet.handler.AbstractHandlerMethodMapping$MappingRegistry.register(AbstractHandlerMethodMapping.java:544) Mapped "{[/websocket],methods=[GET]}" onto public java.lang.String com.linhw.spring.test.WebSocketController.websocketPage() [INFO ] 2020-05-20 22:13:25,845 method:org.springframework.kafka.listener.AbstractMessageListenerContainer$2.onPartitionsAssigned(AbstractMessageListenerContainer.java:281) partitions assigned:[topic.quick.batch-0, topic.quick.batch-1]
测试:在短时间内发送12条消息到topic中,可以看到运行结果,对应的监听方法总共拉取了三次数据,其中两次为5条数据,一次为2条数据,加起来就是我们在测试方法发送的12条数据。
@Test public void testBatch() { for (int i = 0; i < 12; i++) { kafkaTemplate.send("topic.quick.batch", "test batch listener,dataNum-" + i); } }
注意:设置的并发量不能大于partition的数量,如果需要提高吞吐量,可以通过增加partition的数量达到快速提升吞吐量的效果。
(4) 监听Topic中指定的分区
@TopicPartition:topic--需要监听的Topic的名称,partitions --需要监听Topic的分区id,partitionOffsets --可以设置从某个偏移量开始监听
@PartitionOffset:partition --分区Id,非数组,initialOffset --初始偏移量
① 创建分区的topic
@Bean public NewTopic batchWithPartitionTopic() { return new NewTopic("topic.quick.batch.partition", 8, (short) 1); }
② 分区注解
@KafkaListener(id = "batchWithPartition", containerFactory = "batchContainerFactory", topicPartitions = { @TopicPartition(topic = "topic.quick.batch.partition",partitions = {"1","3"}), @TopicPartition(topic = "topic.quick.batch.partition",partitions = {"0","4"}, partitionOffsets = @PartitionOffset(partition = "2",initialOffset = "100")) } ) public void batchListenerWithPartition(List<String> data) { log.info("topic.quick.batch.partition receive : "); for (String s : data) { log.info(s); } }
(5) 注解方式获取消息头及消息体
- @Payload:获取的是消息的消息体,也就是发送内容
- @Header(KafkaHeaders.RECEIVED_MESSAGE_KEY):获取发送消息的key
- @Header(KafkaHeaders.RECEIVED_PARTITION_ID):获取当前消息是从哪个分区中监听到的
- @Header(KafkaHeaders.RECEIVED_TOPIC):获取监听的TopicName
- @Header(KafkaHeaders.RECEIVED_TIMESTAMP):获取时间戳
@KafkaListener(id = "anno", topics = "topic.quick.anno") public void headerListener(@Payload String data, @Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) Integer key, @Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic, @Header(KafkaHeaders.RECEIVED_TIMESTAMP) long ts) { log.info("topic.quick.anno receive : "+ "data : "+data+" "+ "key : "+key+" "+ "partitionId : "+partition+" "+ "topic : "+topic+" "+ "timestamp : "+ts+" " ); }
测试
@Test public void testAnno() throws InterruptedException { Map map = new HashMap<>(); map.put(KafkaHeaders.TOPIC, "topic.quick.anno"); map.put(KafkaHeaders.MESSAGE_KEY, 0); map.put(KafkaHeaders.PARTITION_ID, 0); map.put(KafkaHeaders.TIMESTAMP, System.currentTimeMillis()); kafkaTemplate.send(new GenericMessage<>("test anno listener", map)); }
(6) 使用Ack机制确认消费
Kafka的Ack机制相对于RabbitMQ的Ack机制差别比较大,刚入门Kafka的时候我也被搞蒙了,不过能弄清楚Kafka是怎么消费消息的就能理解Kafka的Ack机制了
我先说说RabbitMQ的Ack机制,RabbitMQ的消费可以说是一次性的,也就是你确认消费后就立刻从硬盘或内存中删除,而且RabbitMQ粗糙点来说是顺序消费,像排队一样,一个个顺序消费,未被确认的消息则会重新回到队列中,等待监听器再次消费。
但Kafka不同,Kafka是通过最新保存偏移量进行消息消费的,而且确认消费的消息并不会立刻删除,所以我们可以重复的消费未被删除的数据,当第一条消息未被确认,而第二条消息被确认的时候,Kafka会保存第二条消息的偏移量,也就是说第一条消息再也不会被监听器所获取,除非是根据第一条消息的偏移量手动获取。
使用Kafka的Ack机制比较简单,只需简单的三步即可:
- 设置ENABLE_AUTO_COMMIT_CONFIG=false,禁止自动提交
- 设置AckMode=MANUAL_IMMEDIATE
- 监听方法加入Acknowledgment ack 参数
怎么拒绝消息呢,只要在监听方法中不调用ack.acknowledge()即可。
import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.common.serialization.IntegerDeserializer; import org.apache.kafka.common.serialization.StringDeserializer; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.context.annotation.Bean; import org.springframework.kafka.annotation.KafkaListener; import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory; import org.springframework.kafka.core.DefaultKafkaConsumerFactory; import org.springframework.kafka.listener.AbstractMessageListenerContainer; import org.springframework.kafka.support.Acknowledgment; import org.springframework.stereotype.Component; import java.util.HashMap; import java.util.Map; @Component public class AckListener { private static final Logger log= LoggerFactory.getLogger(AckListener.class); private Map<String, Object> consumerProps() { Map<String, Object> props = new HashMap<String, Object>(); props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000"); props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "15000"); props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class); props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); return props; } @Bean("ackContainerFactory") public ConcurrentKafkaListenerContainerFactory ackContainerFactory() { ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory(); factory.setConsumerFactory(new DefaultKafkaConsumerFactory(consumerProps())); factory.getContainerProperties().setAckMode(AbstractMessageListenerContainer.AckMode.MANUAL_IMMEDIATE); factory.setConsumerFactory(new DefaultKafkaConsumerFactory(consumerProps())); return factory; } @KafkaListener(id = "ack", topics = "topic.quick.ack",containerFactory = "ackContainerFactory") public void ackListener(ConsumerRecord record, Acknowledgment ack) { log.info("topic.quick.ack receive : " + record.value()); ack.acknowledge(); } }
编写测试方法,运行后可以方法监听方法能收到消息,紧接着注释ack.acknowledge()方法,重新测试,同样你会发现监听容器能接收到消息,这个时候如果你重启项目还是可以看到未被确认的那几条消息。
@Test public void testAck() throws InterruptedException { for (int i = 0; i < 5; i++) { kafkaTemplate.send("topic.quick.ack", i+""); } }
Kafka机制会出现的一些情况,导致没办法重复消费未被Ack的消息,解决办法有如下:
① 重新将消息发送到队列中,这种方式比较简单而且可以使用Headers实现第几次消费的功能,用以下次判断
@KafkaListener(id = "ack", topics = "topic.quick.ack", containerFactory = "ackContainerFactory") public void ackListener(ConsumerRecord record, Acknowledgment ack, Consumer consumer) { log.info("topic.quick.ack receive : " + record.value()); //如果偏移量为偶数则确认消费,否则拒绝消费 if (record.offset() % 2 == 0) { log.info(record.offset()+"--ack"); ack.acknowledge(); } else { log.info(record.offset()+"--nack"); kafkaTemplate.send("topic.quick.ack", record.value()); } }
② 使用Consumer.seek方法,重新回到该未ack消息偏移量的位置重新消费,这种可能会导致死循环,原因出现于业务一直没办法处理这条数据,但还是不停的重新定位到该数据的偏移量上。
@KafkaListener(id = "ack", topics = "topic.quick.ack", containerFactory = "ackContainerFactory") public void ackListener(ConsumerRecord record, Acknowledgment ack, Consumer consumer) { log.info("topic.quick.ack receive : " + record.value()); //如果偏移量为偶数则确认消费,否则拒绝消费 if (record.offset() % 2 == 0) { log.info(record.offset()+"--ack"); ack.acknowledge(); } else { log.info(record.offset()+"--nack"); consumer.seek(new TopicPartition("topic.quick.ack",record.partition()),record.offset() ); } }
6. 实现消息转发以及ReplyTemplate
软件需要使用什么技术都是按照业务逻辑来的嘛,那自动转发相对应的业务可以是什么呢?
可以使用转发功能实现业务解耦,系统A从Topic-A中获取到消息,进行处理后转发到Topic-B中,系统B监听Topic-B获取消息再次进行处理,这个消息可以是订单相关数据,系统A处理用户提交的订单审核,系统B处理订单的物流信息等等。
Spring-Kafka整合了两种消息转发方式:
- 使用Headers设置回复主题(Reply_Topic),这种方式比较特别,是一种请求响应模式,使用的是ReplyingKafkaTemplate类
- 手动转发,使用@SendTo注解将监听方法返回值转发到Topic中
(1) @SendTo方式
- 配置ConcurrentKafkaListenerContainerFactory的ReplyTemplate
- 监听方法加上@SendTo注解
这里我们为监听容器工厂(ConcurrentKafkaListenerContainerFactory)配置一个ReplyTemplate,ReplyTemplate是我们用来转发消息所使用的类。@SendTo注解本质其实就是利用这个ReplyTemplate转发监听方法的返回值到对应的Topic中,我们也可以是用代码实现KakfaTemplate.send(),不过使用注解的好处就是减少代码量,加快开发效率。
@Bean public ConcurrentKafkaListenerContainerFactory<Integer, String> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setReplyTemplate(kafkaTemplate()); return factory; }
@Component public class ForwardListener { private static final Logger log= LoggerFactory.getLogger(ForwardListener.class); @KafkaListener(id = "forward", topics = "topic.quick.target") @SendTo("topic.quick.real") public String forward(String data) { log.info("topic.quick.target forward "+data+" to topic.quick.real"); return "topic.quick.target send msg : " + data; } }
测试:可以看到运行成功后,topic.quick.real这个主题会产生一条数据,这条数据就是我们在forward方法返回的值。
@Autowired private KafkaTemplate kafkaTemplate; @Test public void testForward() { kafkaTemplate.send("topic.quick.target", "test @SendTo"); }
(2) ReplyTemplate方式
使用ReplyTemplate方式不同于@SendTo方式,@SendTo是直接将监听方法的返回值转发对应的Topic中,而ReplyTemplate也是将监听方法的返回值转发Topic中,但转发Topic成功后,会被请求者消费。
这是怎么回事呢?我们可以回想一下请求响应模式,这种模式其实我们是经常使用的,就像你调用某个第三方接口,这个接口会把响应报文返回给你,你可以根据业务处理这段响应报文。而ReplyTemplate方式的这种请求响应模式也是相同的,首先生成者发送消息到Topic-A中,Topic-A的监听器则会处理这条消息,紧接着将消息转发到Topic-B中,当这条消息转发到Topic-B成功后则会被ReplyTemplate接收。那最终消费者获得的是被处理过的数据。
实现流程:
- 配置ConcurrentKafkaListenerContainerFactory的ReplyTemplate
- 配置topic.quick.request的监听器
- 注册一个KafkaMessageListenerContainer类型的监听容器,监听topic.quick.reply,这个监听器里面我们不处理任何事情,交由ReplyingKafkaTemplate处理
- 通过ProducerFactory和KafkaMessageListenerContainer创建一个ReplyingKafkaTemplate类型的Bean,设置回复超时时间为10秒
@Bean public ConcurrentKafkaListenerContainerFactory<Integer, String> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setReplyTemplate(kafkaTemplate()); return factory; }
@KafkaListener(id = "replyConsumer", topics = "topic.quick.request",containerFactory = "kafkaListenerContainerFactory") @SendTo public String replyListen(String msgData){ log.info("topic.quick.request receive : "+msgData); return "topic.quick.reply reply : "+msgData; } @Bean public KafkaMessageListenerContainer<String, String> replyContainer(@Autowired ConsumerFactory consumerFactory) { ContainerProperties containerProperties = new ContainerProperties("topic.quick.reply"); return new KafkaMessageListenerContainer<>(consumerFactory, containerProperties); } @Bean public ReplyingKafkaTemplate<String, String, String> replyingKafkaTemplate(@Autowired ProducerFactory producerFactory, KafkaMessageListenerContainer replyContainer) { ReplyingKafkaTemplate template = new ReplyingKafkaTemplate<>(producerFactory, replyContainer); template.setReplyTimeout(10000); return template; }
发送消息就显得稍微有点麻烦了,不过在项目编码过程中可以把它封装成一个工具类调用。
- 我们需要创建ProducerRecord类,用来发送消息,并添加KafkaHeaders.REPLY_TOPIC到record的headers参数中,这个参数配置我们想要转发到哪个Topic中。
- 使用replyingKafkaTemplate.sendAndReceive()方法发送消息,该方法返回一个Future类RequestReplyFuture,这里类里面包含了获取发送结果的Future类和获取返回结果的Future类。使用replyingKafkaTemplate发送及返回都是异步操作。
- 调用RequestReplyFuture.getSendFutrue().get()方法可以获取到发送结果
- 调用RequestReplyFuture.get()方法可以获取到响应结果
@Autowired private ReplyingKafkaTemplate replyingKafkaTemplate; @Test public void testReplyingKafkaTemplate() throws ExecutionException, InterruptedException, TimeoutException { ProducerRecord<String, String> record = new ProducerRecord<>("topic.quick.request", "this is a message"); record.headers().add(new RecordHeader(KafkaHeaders.REPLY_TOPIC, "topic.quick.reply".getBytes())); RequestReplyFuture<String, String, String> replyFuture = replyingKafkaTemplate.sendAndReceive(record); SendResult<String, String> sendResult = replyFuture.getSendFuture().get(); System.out.println("Sent ok: " + sendResult.getRecordMetadata()); ConsumerRecord<String, String> consumerRecord = replyFuture.get(); System.out.println("Return value: " + consumerRecord.value()); Thread.sleep(20000); }
注意:由于ReplyingKafkaTemplate也是通过监听容器实现的,所以响应时间可能会较慢,要注意选择合适的场景使用。
7. KafkaListener定时启动(禁止自启动)
(1) 定时启动的意义何在?
在这里我举一个定时启动的应用场景:
比如现在单机环境下,我们需要利用Kafka做数据持久化的功能,由于用户活跃的时间为早上10点至晚上12点,那在这个时间段做一个大数据量的持久化可能会影响数据库性能导致用户体验降低,我们可以选择在用户活跃度低的时间段去做持久化的操作,也就是晚上12点后到第二条的早上10点前。
(2) 使用KafkaListenerEndpointRegistry
注意下:@KafkaListener这个注解所标注的方法并没有在IOC容器中注册为Bean,而是会被注册在KafkaListenerEndpointRegistry中,KafkaListenerEndpointRegistry在SpringIOC中已经被注册为Bean。
那我们怎么让KafkaListener定时启动呢?
- 禁止KafkaListener自启动(AutoStartup)
- 编写两个定时任务,一个晚上12点,一个早上10点
- 分别在12点的任务上启动KafkaListener,在10点的任务上关闭KafkaListener
import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Bean; import org.springframework.kafka.annotation.KafkaListener; import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory; import org.springframework.kafka.config.KafkaListenerEndpointRegistry; import org.springframework.kafka.core.ConsumerFactory; import org.springframework.scheduling.annotation.EnableScheduling; import org.springframework.scheduling.annotation.Scheduled; import org.springframework.stereotype.Component; @Component @EnableScheduling public class TaskListener{ private static final Logger log= LoggerFactory.getLogger(TaskListener.class); @Autowired private KafkaListenerEndpointRegistry registry; @Autowired private ConsumerFactory consumerFactory; @Bean public ConcurrentKafkaListenerContainerFactory delayContainerFactory() { ConcurrentKafkaListenerContainerFactory container = new ConcurrentKafkaListenerContainerFactory(); container.setConsumerFactory(consumerFactory); //禁止自动启动 container.setAutoStartup(false); return container; } @KafkaListener(id = "durable", topics = "topic.quick.durable",containerFactory = "delayContainerFactory") public void durableListener(String data) { //这里做数据持久化的操作 log.info("topic.quick.durable receive : " + data); } //定时器,每天凌晨0点开启监听 @Scheduled(cron = "0 0 0 * * ?") public void startListener() { log.info("开启监听"); //判断监听容器是否启动,未启动则将其启动 if (!registry.getListenerContainer("durable").isRunning()) { registry.getListenerContainer("durable").start(); } registry.getListenerContainer("durable").start(); } //定时器,每天早上10点关闭监听 @Scheduled(cron = "0 0 10 * * ?") public void shutDownListener() { log.info("关闭监听"); registry.getListenerContainer("durable").stop(); } }
8. 配置消息过滤器
消息过滤器可以在消息抵达监听容器前被拦截,过滤器根据系统业务逻辑去筛选出需要的数据再交由KafkaListener处理。
配置消息其实是非常简单的额,只需要为监听容器工厂配置一个RecordFilterStrategy(消息过滤策略),返回true的时候消息将会被抛弃,返回false时,消息能正常抵达监听容器。
这里我们将消息转换为long类型,判断该消息为基数还是偶数,把所有基数过滤,监听容器只接收偶数。
import org.apache.kafka.clients.consumer.ConsumerRecord; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Bean; import org.springframework.kafka.annotation.KafkaListener; import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory; import org.springframework.kafka.core.ConsumerFactory; import org.springframework.kafka.listener.adapter.RecordFilterStrategy; import org.springframework.stereotype.Component; @Component public class FilterListener { private static final Logger log= LoggerFactory.getLogger(TaskListener.class); @Autowired private ConsumerFactory consumerFactory; @Bean public ConcurrentKafkaListenerContainerFactory filterContainerFactory() { ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory(); factory.setConsumerFactory(consumerFactory); //配合RecordFilterStrategy使用,被过滤的信息将被丢弃 factory.setAckDiscarded(true); factory.setRecordFilterStrategy(new RecordFilterStrategy() { @Override public boolean filter(ConsumerRecord consumerRecord) { long data = Long.parseLong((String) consumerRecord.value()); log.info("filterContainerFactory filter : "+data); if (data % 2 == 0) { return false; } //返回true将会被丢弃 return true; } }); return factory; } @KafkaListener(id = "filterCons", topics = "topic.quick.filter",containerFactory = "filterContainerFactory") public void filterListener(String data) { //这里做数据持久化的操作 log.error("topic.quick.filter receive : " + data); } }
9. ConsumerAwareErrorHandler异常处理器
注:ConsumerAwareErrorHandler在Spring4.3.23.RELEASE中没有找到,可能是Spring5的?
代码异常十之八九,十段代码九个bug。平常程序异常我们使用try catch捕获异常,在catch方法中根据异常类型进行相关处理,既然我们可以使用try catch处理异常,那为什么还要使用ConsumerAwareErrorHandler异常处理器去处理异常呢?
首先,KafkaListener要做的事只是监听Topic中的数据并消费,如果在KafkaListener中还需要对异常进行处理则会显得代码块非常臃肿不利于维护,我们可以把异常处理的这些代码抽象出来,构造成一个异常处理器,KafkaListener中所抛出的异常都会经过ConsumerAwareErrorHandler异常处理器进行处理,这样就非常方便我们进行后期维护,比如后期更改异常处理业务的时候,只需要修改ConsumerAwareErrorHandler处理器就行了,而不需要KafkaListener的一堆代码中去修改代码。
(1) 单消息消费异常处理器
这里主要就是注册一个ConsumerAwareListenerErrorHandler 类型的异常处理器,bean的注册默认使用的是方法名,所以我们将这个异常处理的BeanName放到@KafkaListener注解的errorHandler属性里面。当KafkaListener抛出异常的时候,则会自动调用异常处理器。
@Component public class ErrorListener { private static final Logger log= LoggerFactory.getLogger(ErrorListener.class); @KafkaListener(id = "err", topics = "topic.quick.error", errorHandler = "consumerAwareErrorHandler") public void errorListener(String data) { log.info("topic.quick.error receive : " + data); throw new RuntimeException("fail"); } @Bean public ConsumerAwareListenerErrorHandler consumerAwareErrorHandler() { return new ConsumerAwareListenerErrorHandler() { @Override public Object handleError(Message<?> message, ListenerExecutionFailedException e, Consumer<?, ?> consumer) { log.info("consumerAwareErrorHandler receive : "+message.getPayload().toString()); return null; } }; } }
(2) 批量消费异常处理器
批量消费代码也是差不多的,只不过传递过来的数据都是List集合方式.
@Bean public ConsumerAwareListenerErrorHandler consumerAwareErrorHandler() { return new ConsumerAwareListenerErrorHandler() { @Override public Object handleError(Message<?> message, ListenerExecutionFailedException e, Consumer<?, ?> consumer) { log.info("consumerAwareErrorHandler receive : "+message.getPayload().toString()); MessageHeaders headers = message.getHeaders(); List<String> topics = headers.get(KafkaHeaders.RECEIVED_TOPIC, List.class); List<Integer> partitions = headers.get(KafkaHeaders.RECEIVED_PARTITION_ID, List.class); List<Long> offsets = headers.get(KafkaHeaders.OFFSET, List.class); Map<TopicPartition, Long> offsetsToReset = new HashMap<>(); return null; } }; }
参考: