本蒟蒻终于浮上来了,泪目......作业链接放在下面
https://github.com/Luckyoranges/031802531
一、计算模块接口的设计与实现过程
先放上流程图
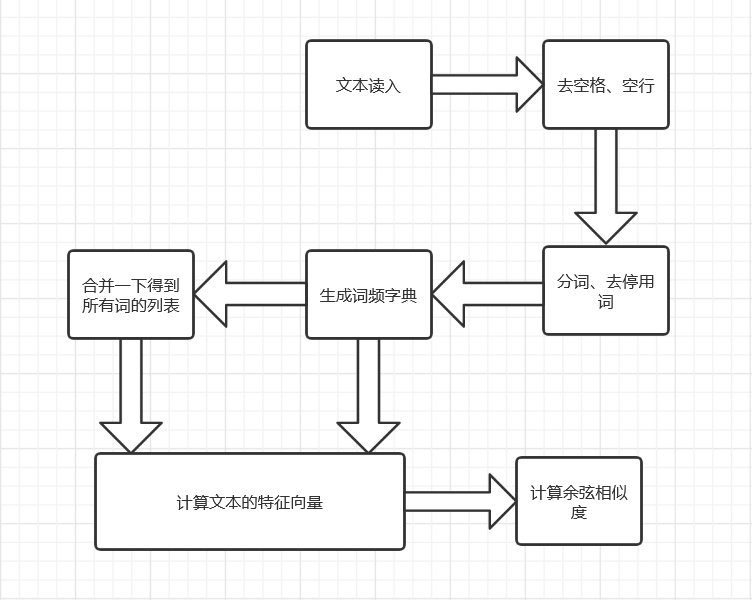
简单地说明一下算法原理(真的真的很容易理解,因为是本蒟蒻自己的理解)
高中的时候大家都学过空间中两个向量夹角余弦值的公式吧:
余弦值越大,那么两个向量之间的夹角就越小,这两个向量之间的距离就越近。
那么,如果我们把两个文本也表示成向量的模式,然后计算出它们的余弦值,是不是就可以根据这个来判断它们的相似度了呢。
下面来介绍一下各个模块,分成三个部分:文本预处理、特征向量生成(核心)、余弦相似度计算(but这个很简单啦,就不介绍了)
1、文本预处理
先把文本中的空格、空行去掉,这样方便对文本进行分词操作。
分词的话,这里我用了jieba分词工具
然后将分词结果中的停用词(“的”、“然后”之类的)去掉,增加准确性
2、特征向量生成
关于怎么确定特征向量的权值问题真的困扰了我好久,最初是想用TF-IDF计算权值的,可是计算这个要有较多的文本作为语料库,可我们只比较两个文本的相似度呀。
然后突然发现,只有两个文本用TF不就好了吗,还要IDF干嘛。。。
分别计算一下两个文本所有词的词频,然后按词频排个序(不是闲得无聊,排序生成元组列表后面会好操作一点)。
再把两个文本出现的所有词提取出来生成列表,用它构成我们的向量空间。
对所有词列表里的每个词计算它在一个文本中的出现次数,以词频作为向量分量的值(前面排过序,这里遍历的时候会快一点点),生成文本的特征向量。
二、计算模块接口部分的性能改进
这里用了Pycharm的分析工具
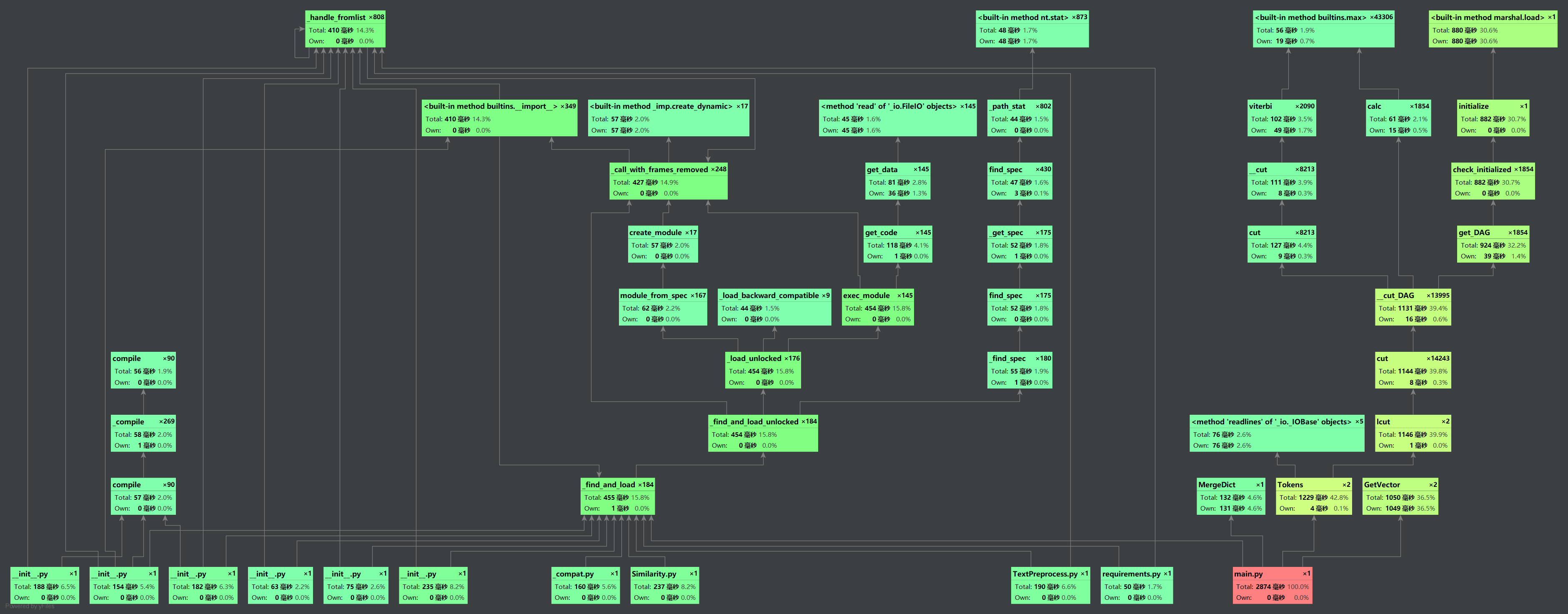
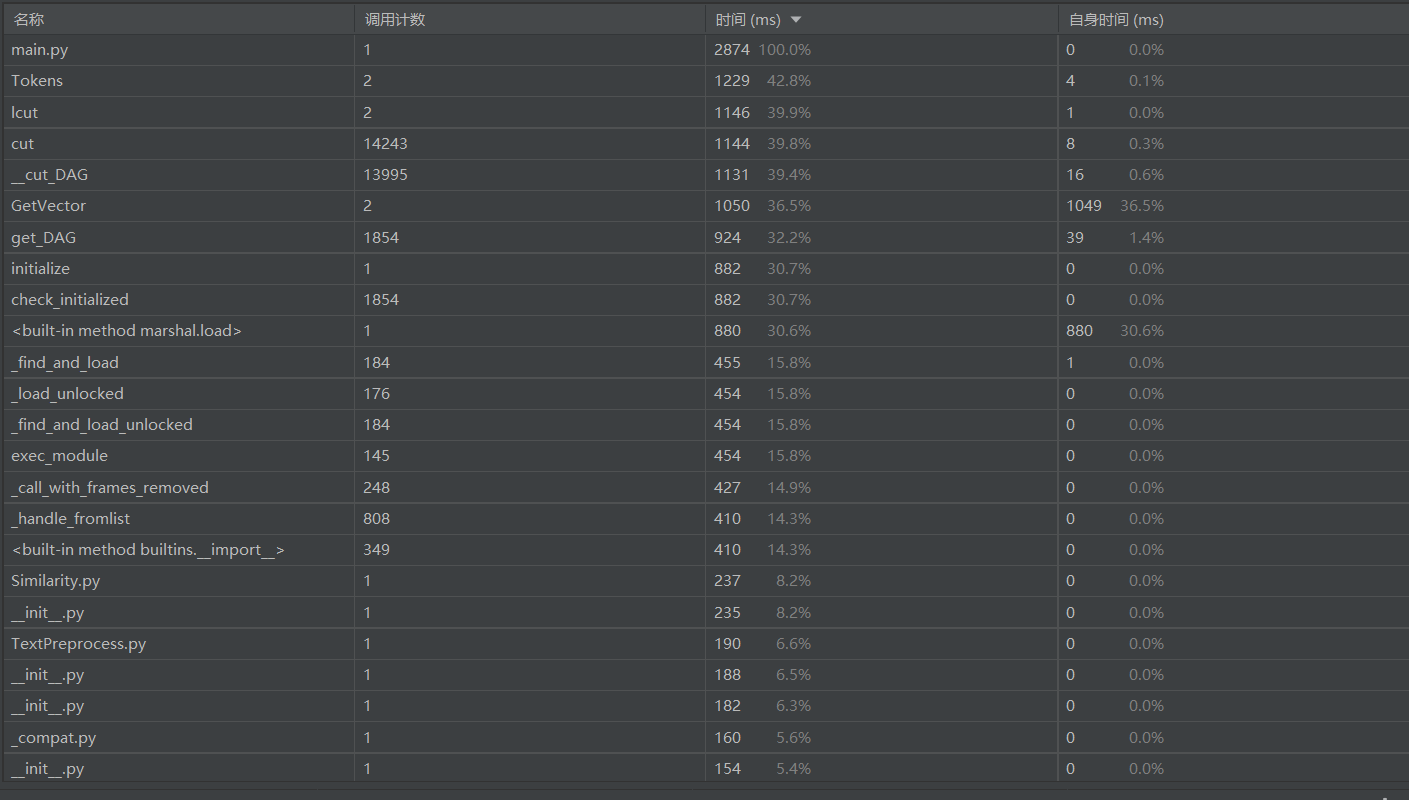
文本预处理和特征向量计算模块都耗费了挺多时间的,分词用了别人的东西,自己优化不来哈哈,不去停用词的话应该会提高一点性能,但是答案的准确度会下降,还是保留着它吧;
在设计的时候有考虑到特征向量计算的复杂度是O(n²),因为用了两层循环,所以想看看排序会不会快一点,看来好像还是差强人意。
三、计算模块部分单元测试展示
测试代码:
import unittest
import TestFunction
class TextTestCase(unittest.TestCase):
def test_self(self):
print("orig.txt的文本相似度如下:
")
TestFunction.test_main("orig.txt", "testfileorig.txt", "ans1.txt")
def test_orig_add(self):
print("orig_0.8_add.txt的文本相似度如下:
")
TestFunction.test_main("orig.txt", "testfileorig_0.8_add.txt", "ans2.txt")
def test_orig_dis1(self):
print("orig_0.8_dis_1.txt的文本相似度如下:
")
TestFunction.test_main("orig.txt", "testfileorig_0.8_dis_1.txt", "ans3.txt")
def test_orig_dis3(self):
print("orig_0.8_dis_3.txt的文本相似度如下:
")
TestFunction.test_main("orig.txt", "testfileorig_0.8_dis_3.txt", "ans4.txt")
def test_orig_dis7(self):
print("orig_0.8_dis_7.txt的文本相似度如下:
")
TestFunction.test_main("orig.txt", "testfileorig_0.8_dis_7.txt", "ans5.txt")
def test_orig_dis10(self):
print("orig_0.8_dis_10.txt的文本相似度如下:
")
TestFunction.test_main("orig.txt", "testfileorig_0.8_dis_10.txt", "ans6.txt")
def test_orig_dis15(self):
print("orig_0.8_dis_15.txt的文本相似度如下:
")
TestFunction.test_main("orig.txt", "testfileorig_0.8_dis_15.txt", "ans7.txt")
def test_orig_mix(self):
print("orig_0.8_mix.txt的文本相似度如下:
")
TestFunction.test_main("orig.txt", "testfileorig_0.8_mix.txt", "ans8.txt")
def test_orig_rep(self):
print("orig_0.8_rep.txt的文本相似度如下:
")
TestFunction.test_main("orig.txt", "testfileorig_0.8_rep.txt", "ans9.txt")
unittest.main()
测试结果:

测试覆盖率:
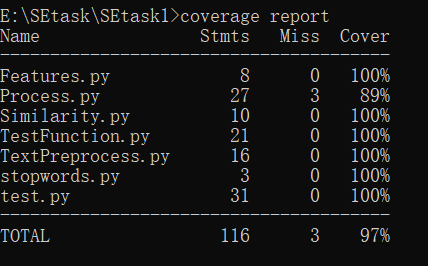
Process.py里面有个条件分支,应该是那里没有执行,没有问题的
四、计算模块部分异常处理说明
空文本异常处理
import TestFunction
try:
TestFunction.test_main("orig.txt", "null.txt", "ans.txt")
except IndexError:
print("HeHeHe, 读入了空文件吧!")
五、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 60 | 60 |
| Development | 开发 | ||
| · Analysis | · 需求分析(包括学习新技术) | 1200 | 840 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范(为目前的开发制定合适的规范) | 30 | 20 |
| · Design | · 具体设计 | 60 | 40 |
| · Coding | · 具体编码 | 480 | 240 |
| · Code Review | · 代码复审 | 60 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 480 |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结,并提出过程改进计划 | 60 | 120 |
| · 合计 | 2160 | 1970 |
六、作业总结
十场理论考试都顶不上这一次软工作业啊啊啊!之前说每天一个小时,我觉得还蛮多的,结果每天两小时到deadline那一天才做完......
不过通过这次作业,也确实让在两周内我学到了大量知识,包括两天速成python、三天速成Git基本操作和面向GitHub编程等等。
原来完成一个项目需要这么多的工作,而编写代码只是其中的一小部分(我花在测试和修改上的时间比编码还多一倍......)。
目前来看,要能够在接下来的作业中继续“生存”下来,我还要再加把劲呀,python的好多特性还没搞懂,这次作业中也没有使用到类。
不说了,回到知识的大海里吧,明天又是新的作业......