最常用的简体字识别包:https://raw.githubusercontent.com/tesseract-ocr/tessdata/4.00/chi_sim.traineddata,也可以从上面的语言包下载地址获取各种你所需要的语言包
第二步:
直接执行下载好的tesseract-ocr-setup-4.00.00dev.exe(我的),下一步、下一步安装。其中



如果可以,也可以全部勾选,避免以后再单独下载字符库,其实我是全部下载,不过过程有点漫长,超级慢,我是隔夜安装好的。
第三步:配置环境变量
注意:我的系统是win7,其他系统应该差不多,跟配置java变量一样
复制你的安装地址,我的是安装在C:Program Files (x86)Tesseract-OCR,界面如下:

复制安装路径“C:Program Files (x86)Tesseract-OCR”,进入“控制面板系统和安全系统”,点击
“系统保护”(就是修改环境变量)
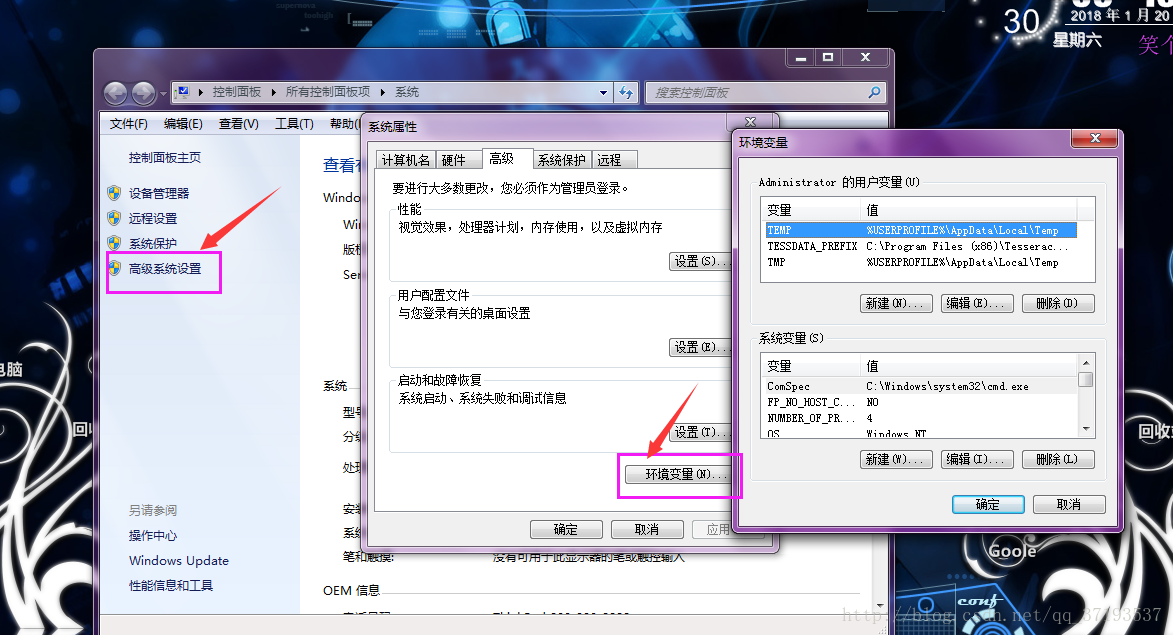
刚才的安装路径“C:Program Files (x86)Tesseract-OCR”添加到的PATH中
配置好了点击保存。
打开命令终端,输入:tesseract -v,可以看到版本信息

如果出现报错,估计是环境变量没配置好。
到这里,我们就算安装完成了,但是,我们的系统还是无法识别中文的,我们要去下载简体汉字、繁体汉字语言包(上文给了地址了),下载好之后放到安装目录的tessconfigs目录下即可。
补充:因为没有配置全局变量,无法跨盘执行数据转换,这里我们在环境变量那增加一个配置信息
系统变量—->新建:
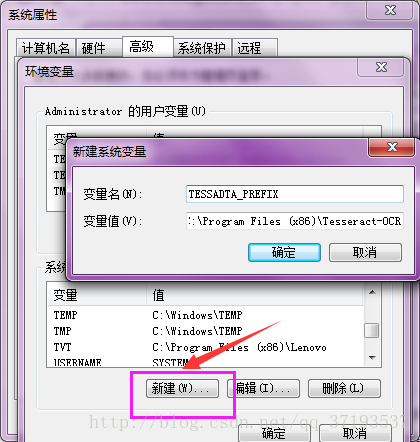
命令行操作:
tesseract 1.jpg 1.txt -l chi_sim+equ+eng
然后回车
1.jpg是当前目录中的1.jpg图片
1.txt是指定结果输出到文本文件
-l是指定使用的包
chi_sim是中文识别包,equ是数学公式包,eng是英文包