0.卷积层的理解
- 实际上卷积核(convolution kernel)不是真的卷积,而是类似一个输入和输出之间的线性表达式.
- 为什么叫做卷积呢, 因为两个次序上相邻的NxN卷积核有N-1的重叠. 本质上卷积核是一个线性过滤式, 比如输入时4x4的小宏块, 卷积核过滤的结果相当于一次线性计算. 卷积核之后的亚采样和池化都是为了把局部特征进行抽象化.
- 但从数据传播的方向上来讲,卷积核进行特征提取,然后亚采样和池化(sub-sampling and pooling)会突出/削弱一些主要的特征成分. 说简单点,问题中的这张图包含字母,字母的特征是什么呢?基本特征就是边界在灰度图上的映射. 通过卷积核进行每个局部特征的提取然后层层递进.
- 最接近输入层(即数据帧)的卷积核-亚采样-池化提取的是基本特征,比如边界,明暗, 简单的条纹(实际就是一阶的数学特征,比如明暗的梯度). 但越靠近输出提取的特征越抽象. 比如在前几层卷积核提取的是条纹- -纹理--分布边界--物体轮廓这样的分级递进关系, 后面就是宏观的特征了.比如这个物体是猫还是狗,如果是狗是哪个品种的狗.
1. 卷积层输出尺寸计算
1.1 理论计算
假定参数如下:
- 输入图片的大小: (n,n)
- 卷积核的大小:(f,f)
- 步长:s (卷积核计算一个区域后,挪动几个像素再进行计算)
- padding值:p (即在图像边缘填充几层0)$padding = frac{f-1}{2}$(大小为偶数的卷积核即使对称地加padding也不能保证输入feature map尺寸和输出feature map尺寸不变,所以一般都用>1的奇数作为卷积核大小 )
计算公式如下(长、宽的计算方法都一样):
$n' = lfloor frac{n+2*p-f}{s} floor +1$
- 卷积输出的图像大小是多少,就看卷积核在横向一行走了多少次(+1),纵向一列走了多少次(+1)。
- 图像会先根据padding值在四周填充0,然后卷积核在左上方对齐填充后的图片,再向一个方向移动。可以移动的长度是$n+2*p-f$ , 然后我们还要除以步长(如果商不是整数,那么向下取整),最后都会差一步,所以加上这一步。
*池化层处理*
输入图片的大小: (n,n)
pool_size的大小:(f,f)
步长:s (卷积核计算一个区域后,挪动几个像素再进行计算)
默认s大小为pool_size的大小
*池化后的大小*
$n' = lfloor frac{n-f}{s} floor +1$
1.2 tf.keras中的卷积层类
tf.keras.layers.MaxPool2D()、tf.keras.layers.Conv2D()等文档中padding参数只有两项:valid | same
same模式:卷积核的中心对齐图片左上角,然后开始做卷机运算
此时:kernel_size = 3, padding = 1, 若stride = 2
$n' =lfloor frac{n+2*p-f}{s} floor +1 =lfloor frac{6+2*1-3}{2} floor +1=3$
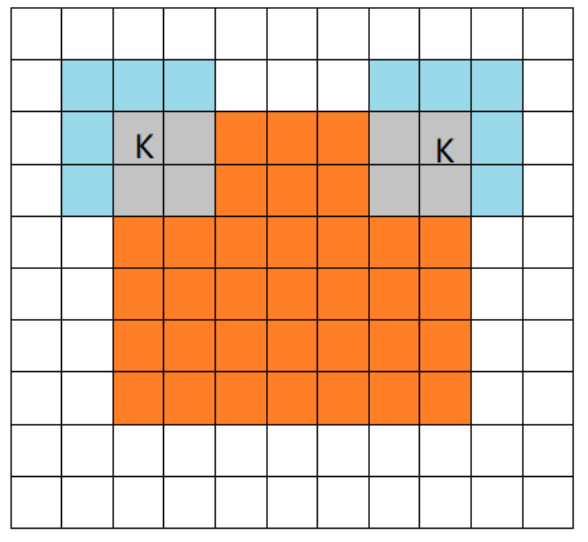
valid模式:卷积核最上角与图片左上角对齐,再做卷积运算
此时:kernel_size = 3, padding = 0, 若stride=2
$n' = lfloor frac{n+2*p-f}{s} floor +1 = lfloor frac{6+2*0-3}{2} floor +1=2$
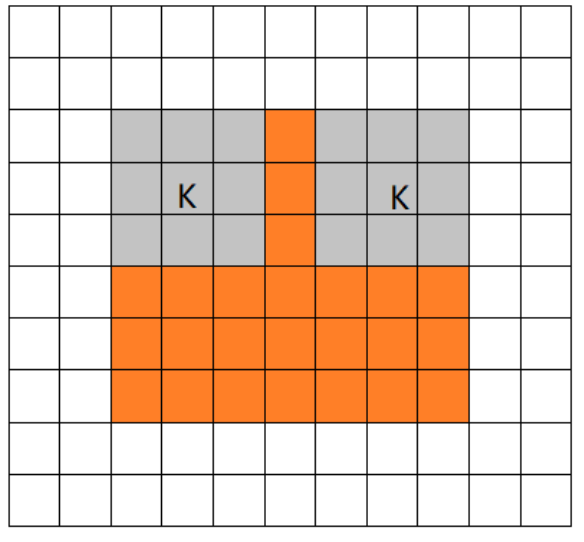
—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—|—
2. 卷积核大小、卷积层数选择
2.1 卷积核大小、卷积层数与参数、计算开销的关系


上四图(上左-1、上右-2、下左-1、下右-2)阐释了,为什么很多流行的深度卷积网络多采用小而深的卷积核与网络结构:
- 卷积层的卷积核去计算上一层图像中与卷积核大小相同的感知域区域(感受野),得出一个数值。在卷积核扫描过上一层图像之后,得到的这些数值将组合成新的特征图。之后的卷积层重复相同的工作。(图1)
- 卷积核的权重在这步骤中告诉模型如何去理解图片、抽象出有用的图片信息。这个过程逐步抽象,这个抽象的方法就是各层卷积核的权重。
- 为获得一个抽点的像素点,一个7*7的卷积核完成的任务,可以用3个3*3的卷积核去复现。(图2)
- 7*7的卷积核有49个权重,而3层、每层用3*3的卷积核的权重只有27个权重(图3)
- 通过拆分卷积核、增加卷积层数、可以降低计算复杂度。
- 除此之外,深层的网络由于多层激活函数嵌套的原因,会提升更多的非线性拟合能力,使网络能够表示的函数范围更宽泛。
2.2 卷积核大小(kernel_size)和卷积层个数如何选择
CNN网络结构设计的 观点:
- 每一层卷积有多少filters,以及一共有多少层卷积,这些暂时没有理论支撑。一般都是靠感觉去设置几组候选值,然后通过实验挑选出其中的最佳值。
- 每一层卷积的filters数和网络的总卷积层数,构成了一个巨大的超参集合。一来没有理论去求解这个超参集合里的最优,二来没有足够的计算资源去穷举这个超参集合里的每一个组合,因此我们不知道这个超参集合里的最优组合是什么。
- 虽然说目前有比较火的研究方向针对这种自动神经网络结构搜索(NAS),这些自动搜索出来的网络在常规数据集上的建模结果显示(当然是达到一定的准确度):自动搜索出来的网络中的卷积核的类别有包括各种常见的型号(3*3、5*5、7*7),且在网络中的前后排布没有规律。
- 知乎的一位网友认为:“在网络中使用不同种类、不同大小的卷积核,尤其是在非串联结构中,大概率会取得更好的效果。”
- 在ProxylessNAS中,作者发现:降采样层的卷积核大小相对较大,作者认为大的卷积核有利于在降采样时保留更多的信息。
- 至于卷积核的大小. 取决于要提取的特征分布和区分度.如果本身要提取的特征很小那卷积核也应该很小,卷积核太大比如16x16 vs 4x4这样的差异可能导致丢失一些局部特征。
2.3. feature map个数如何选择
(tf.keras中卷积层的filters参数)
- 关于feature map的个数,有一个大部分网络都在遵循的原则就是当输出特征图尺寸减半时,输出特征图的通道数应该加倍,这样保证相邻卷积层所包含的信息量不会相差太大
- 至于全连接层的节点数,首先现有的分类网络的最后一层几乎都是使用softmax函数激活,输出图片属于每一个类别的概率值,所以最后一层的节点数等于待分类图片的类别数,这是毋庸置疑的。而在Network in network提出全局平均池化(GAP)后,主流的网络几乎都是在特征图尺寸降低到7*7左右时,直接GAP+全连接+softmax输出分类概率。这样网络中只有一层全连接层,其输入节点数是GAP之前的特征图个数,输出节点数是图片分类类别数目。
附上一个从别的知乎网友那里扒来的资料