背景:
KMP算法(Knuth-Morris-Pratt Algorithm)是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现,因此人们称它为克努特——莫里斯——普拉特操作(简称KMP算法)。KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。时间复杂度O(m+n)。
思路:
通过前缀和后缀的思路列出一张《部分匹配表》(Partial Match Table)
使用《部分匹配表》提高字符串匹配的效率
一个简单的想法:
一般人匹配字符串都是一位一位匹配的,怎么说呢,就是从主串的第一个位置开始,将主串与子串长度相同的每一位进行比较,若有一位不同,就跳到主串的第二个位置,重复上面的步骤。举个例子,有两个串
主串:123143612313
子串:12313
当匹配到第五位时发现主串和子串元素的差异,正常人的思路是将整个子串往后移一格,像这样
主串:123143612313
子串: 12313
但是这样的效率太低了,该如何改进它呢,三个巨神稍稍一思考,KMP算法就出来了
新算法的诞生:
可能很多人可以注意到,刚才的操作中,完全可以以“大步”替代“小步”,让算法的效率得到提高,就像这样
主串:123143612313
子串: 12313
可能有些人想要让子串直接跳到匹配位,但这显然不可能,“大步”是建立在探索的基础上,在原算法的基础上,新算法避免了很多不必要的操作
但是该如何实现它呢,这时就要引入新的概念:《部分匹配表》
匹配表的实现:
还是这个例子:
12313
匹配表是通过前缀和后缀比较共有元素长度得出的,
12313的匹配表是:
00010
这是怎么得出来的呢?接下来是highlight部分
"前缀"指除了最后一个字符以外,一个字符串的全部头部组合;"后缀"指除了第一个字符以外,一个字符串的全部尾部组合。
还是以12313为例
1的前缀和后缀都是空集 共有元素长度为0
12的前缀为1 后缀为2,共有元素长度为0
123的前缀为1,12后缀为3,23,共有元素的长度为0
1231的前缀为1,12,123后缀为1,31,231,共有元素的长度为1
12313的前缀为1,12,123,1231后缀为3,13,313,2313,共有元素的长度为0
故00010为这个子串的部分匹配表
更直观地说,部分匹配的实质是,有时候,串头部和尾部会有重复。比如,1231之中有两个"1",那么它的部分匹配值就是1("1"的长度)。搜索词移动的时候,第一个"1"向后移动3位(字符串长度-部分匹配值),就可以来到第二个"1"的位置。
代码的实现
如果想要无注释版本的,在教程的最后会附上
//here array:ne is the Partial_Match_Table //substring here is saving from 1 void workne(){ for(int i=2,j=0;i<=substring_length;i++) //make a loop from 2 to string's length in order to visit from the second element to the last element //j is used to mark the present_largest_match_num's length { while(substring[i]!=substring[j+1]&&j>0)j=ne[j]; //this in order to make a special judge,because this program we use the present_largest_match_num's length to //optimizate the algorithm ,but sometimes it may let us miss some cases //for example :123121 the present_largest_match_num's length is 2(12),j+1=3 but 3(third)!=1(sixth) //just means 123 != 121 //but we find that 1(first)==1(sixth), //so we should move the present_largest_match_num's length back to avoid this missing case if(substring[i]==substring[j+1])ne[i]=++j; //if find the same part just replace it's ne and renew the present_largest_match_num's length } //for example:12311 //at beginning,j=0,and the first element is not the same as the second element //just go on,at position4 the fourth element is the same as the first element //so set the fourth element's sum as 1,then we arrive at the fifth element //1!=2,this means that we can't use the largest_length //because we have break it,12!=11 so,we should move j's num back and try to match them //when move to 0,we can out of while,and mark the true ne:1(because [0+1=1]:1==[5]:1 ,this break the while_condition) }
已经尽我所能的详细了,可惜的是还是没能找出一个很好的several largest_match_num的例子,极端主义者也请think by yourself 然后 out some data against several largest_match_num's case
建立在匹配表上的算法实现:
现在让我们回到原先那个例子
主串:123143612313
子串:12313
匹配表:00010
当我们比较到4!=3时
已匹配的字符数为4(“1231”)
对应的部分匹配值为1,我们就将“1”向后移动4-1=3位(字符串长度-部分匹配值),就可以来到第二个“1”的位置。
可能有的人要问,要是匹配值为0怎么办
这时我们就要把子串开头向后移动字符串长度的位数(字符串长度-部分匹配值),也就是访问到字符串长度+1的位置
因为在已搜索的范围内是不可能找到可能情况的(连相同的开头都不存在,怎么可能会有可能情况),所以这也同样能够让我们避免亢余的操作
代码的实现
void kmp(){ for(int i=1,j=0;i<=mainstring_length;i++){ while(mainstring[i]!=substring[j+1]&&j>0)j=ne[j]; if(mainstring[i]==substring[j+1])++j; if(j==substring_length){printf("%d ",i-substring_length+1);j=ne[substring_length];} } }
操作过程和我刚才所解释的差不多,这里就不一一解释了
疑难分析
1.Next数组的意义
1.字符串中前缀和后缀最长相同情况的长度
2.相同前后缀中与字符串末尾相同的上一个元素的位置(若无则为0)
举个例子
121212
“1”:相同的前后缀为“121”,在这个最长相同前后缀内,我们发现第三个位置为与字符串末尾相同的上一个元素的位置
ne值为3,即与之相同的上一个元素的位置为3
“2”:相同的前后缀为“1212”,在这个最长相同前后缀内,我们发现第四个位置为与字符串末尾相同的上一个元素的位置
ne值为4,即与之相同的上一个元素的位置为4
2.j=ne[j]
分为两种情况:
情况一:ne[j]=0,即说明无法推进(因为前缀后缀无相同情况,我们只能老老实实地从子串的第一位开始匹配)
情况二:ne[j]!=0,即说明可以推进(因为前后缀有相同情况,我们可以直接从相同前缀处开始匹配
该部分需要结合程序理解
因为各个模板的要求不一样,这里以洛谷的题目为准
题目描述
如题,给出两个字符串s1和s2,其中s2为s1的子串,求出s2在s1中所有出现的位置。
为了减少骗分的情况,接下来还要输出子串的前缀数组next。
(如果你不知道这是什么意思也不要问,去百度搜[kmp算法]学习一下就知道了。)
输入输出格式
输入格式:
第一行为一个字符串,即为s1(仅包含大写字母)
第二行为一个字符串,即为s2(仅包含大写字母)
输出格式:
若干行,每行包含一个整数,表示s2在s1中出现的位置
接下来1行,包括length(s2)个整数,表示前缀数组next[i]的值。
输入输出样例
ABABABC ABA
1 3 0 0 1
说明
时空限制:1000ms,128M
数据规模:
设s1长度为N,s2长度为M
对于30%的数据:N<=15,M<=5
对于70%的数据:N<=10000,M<=100
对于100%的数据:N<=1000000,M<=1000
样例说明:
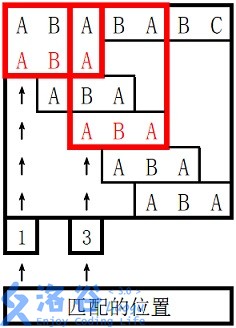
所以两个匹配位置为1和3,输出1、3
#include<cstdio> #include<cstring> int len1,len2,ne[1000001];char s2[1000001],s1[1000001]; inline void out(int x){if(x<0)putchar('-'),x=-x;if(x>9)out(x/10);putchar(x%10+'0');} void sb(){ for(int i=2,j=0;i<=len2;i++){while(s2[i]!=s2[j+1]&&j>0)j=ne[j]; if(s2[i]==s2[j+1])ne[i]=++j;}} void kmp(){for(int i=1,j=0;i<=len1;i++){ while(s1[i]!=s2[j+1]&&j>0)j=ne[j]; if(s1[i]==s2[j+1])++j;if(j==len2)printf("%d ",i-len2+1),j=ne[len2];}} using namespace std; int main(){scanf("%s%s",s1+1,s2+1); len1=strlen(s1+1),len2=strlen(s2+1);sb();kmp(); for(int i=1;i<=len2;i++)out(ne[i]),putchar(' '); }